阿里巴巴开发手册解析个人笔记(五)Mysql规约(四)ORM 映射
文章目录
- ORM 映射
- 1. 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
- 2. 【强制】 POJO 类的布尔属性不能加 is,而数据库字段必须加 is_,要求在 resultMap 中进行
- 3. 【强制】不要用 resultClass 当返回参数,即使所有类属性名与数据库字段一一对应,也需要定义; 反过来,每一个表也必然有一个 POJO 类与之对应。
- 4. 【强制】sql.xml 配置参数使用: #{}, #param# 不要使用${} 此种方式容易出现 SQL 注入。
- 5. 【强制】 iBATIS 自带的 queryForList(String statementName,int start,int size)不推荐使用。
- 6. 【强制】不允许直接拿 HashMap 与 Hashtable 作为查询结果集的输出。
- 7. 【强制】更新数据表记录时,必须同时更新记录对应的 gmt_modified 字段值为当前时间。
- 8. 【推荐】不要写一个大而全的数据更新接口。 传入为 POJO 类,不管是不是自己的目标更新字
- 9. 【参考】 @Transactional 事务不要滥用。事务会影响数据库的 QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
- 9.1. 事务说经过的历程
- 9.2. 缓存回滚方案 摘自:
- 9.3 搜索引擎回滚
- 9.4 消息回滚
- 9.5 统计修正
- 10.【参考】 中的 compareValue 是与属性值对比的常量,一般是数字,表示相等时带上此条件; 表示不为空且不为 null 时执行; 表示不为 null 值时执行
ORM 映射
1. 【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明: 1) 增加查询分析器解析成本。 2) 增减字段容易与 resultMap 配置不一致。 3)无用字
段增加网络消耗,尤其是 text 类型的字段。
2. 【强制】 POJO 类的布尔属性不能加 is,而数据库字段必须加 is_,要求在 resultMap 中进行
is 映射的 在set,get方法不会有i
字段与属性之间的映射。
说明: 参见定义 POJO 类以及数据库字段定义规定,在中增加映射,是必须的。
在 MyBatis Generator 生成的代码中,需要进行对应的修改。
java的object类中,自动生成set,get方法没有 判断isTest的is,直接用test字段来生成set,get
package com.blockchain.vo;
public class AssetSummaryInfoVo {
boolean isTest;
public boolean isTest() { //isTest 没有正确的名称
return isTest;
}
public void setTest(boolean isTest) {//Test 没有正确的名称
this.isTest = isTest;
}
}
而在sql规范中,boolean类型必须要求实用is_test来代表,所以要如上映射
3. 【强制】不要用 resultClass 当返回参数,即使所有类属性名与数据库字段一一对应,也需要定义; 反过来,每一个表也必然有一个 POJO 类与之对应。
说明: 配置映射关系,使字段与 DO 类解耦,方便维护。
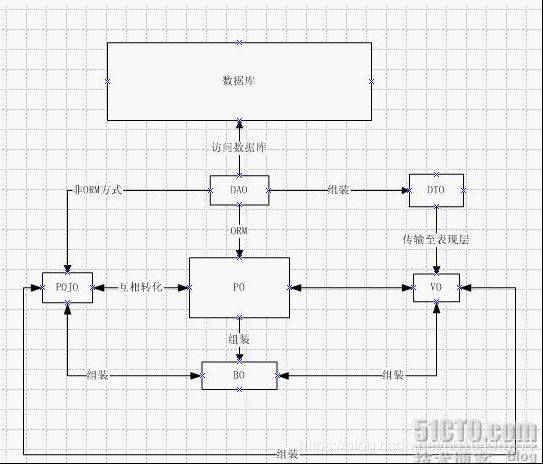
(1)PO:
persistant object持久对象
最形象的理解就是一个PO就是数据库中的一条记录。
好处是可以把一条记录作为一个对象处理,可以方便的转为其它对象。
(2)BO:
business object业务对象
主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。
比如一个简历,有教育经历、工作经历、社会关系等等。
我们可以把教育经历对应一个PO,工作经历对应一个PO,社会关系对应一个PO。
建立一个对应简历的BO对象处理简历,每个BO包含这些PO。
这样处理业务逻辑时,我们就可以针对BO去处理。
(3)VO:
value object值对象
ViewObject表现层对象
主要对应界面显示的数据对象。对于一个WEB页面,或者SWT、SWING的一个界面,用一个VO对象对应整个界面的值。
(4)POJO:
plain ordinary java object 简单java对象
个人感觉POJO是最常见最多变的对象,是一个中间对象,也是我们最常打交道的对象。
一个POJO持久化以后就是PO
直接用它传递、传递过程中就是DTO
直接用来对应表示层就是VO
(5)DTO:
Data Transfer Object数据传输对象
主要用于远程调用等需要大量传输对象的地方。
比如我们一张表有100个字段,那么对应的PO就有100个属性。
但是我们界面上只要显示10个字段,
客户端用WEB service来获取数据,没有必要把整个PO对象传递到客户端,
这时我们就可以用只有这10个属性的DTO来传递结果到客户端,这样也不会暴露服务端表结构.到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为VO
(6)DAO:
data access object数据访问对象
这个大家最熟悉,和上面几个O区别最大,基本没有互相转化的可能性和必要.
主要用来封装对数据库的访问。通过它可以把POJO持久化为PO,用PO组装出来VO、DTO
4. 【强制】sql.xml 配置参数使用: #{}, #param# 不要使用${} 此种方式容易出现 SQL 注入。
摘自:https://stackoverflow.com/questions/39954300/when-to-use-vs
遵循这些myBatis准则#{}在您的sql语句中使用。
如果您查看Mapper XML文件部分中的任何MyBatis参考,它表示明确:
注意参数表示法:
#{id}
否则${}就是
1-配置属性。
例如:
<properties resource="org/mybatis/example/config.properties">
<property name="username" value="dev_user"/>
<property name="password" value="F2Fa3!33TYyg"/>
properties>
然后可以使用下一个属性:
<dataSource type="POOLED">
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
dataSource>
2-字符串替换 ${}(参数部分):
默认情况下,使用#{}语法将导致MyBatis生成PreparedStatement属性并根据PreparedStatement参数安全地设
置值(例如?)。虽然这更安全,更快速且几乎总是首选,但有时您只想将未修改的字符串直接注入SQL语句。例如,对于ORDER
BY,您可以使用以下内容:ORDER BY $ {columnName}
这里MyBatis不会修改或转义字符串。
注意接受来自用户的输入并以这种方式将其提供给未经修改的语句是不安全的。这会导致潜在的SQL注入攻击,因此您应
该禁止在这些字段中输入用户,或者始终执行自己的转义和检查。
因此,name like '%${word}%' or按照名称$ {orderAs}的顺序确定,您需要使用String替换而不是预准备语
句。
5. 【强制】 iBATIS 自带的 queryForList(String statementName,int start,int size)不推荐使用。
说明:其实现方式是在数据库取到 statementName对应的SQL语句的所有记录,再通过 subList
取 start,size 的子集合。
正例:
Map<String, Object> map = new HashMap<>();
map.put("start", start);
map.put("size", size);
6. 【强制】不允许直接拿 HashMap 与 Hashtable 作为查询结果集的输出。
说明: resultClass=”Hashtable”, 会置入字段名和属性值,但是值的类型不可控。
Hashtable 类型极为难易控制,要检测类型,又要判空,增加代码量,是在不必要。
7. 【强制】更新数据表记录时,必须同时更新记录对应的 gmt_modified 字段值为当前时间。
gmt_modified ,create_time 是创建表必建的两个字段,可以提供很多信息,需要及时关注
8. 【推荐】不要写一个大而全的数据更新接口。 传入为 POJO 类,不管是不是自己的目标更新字
段,都进行 update table set c1=value1,c2=value2,c3=value3; 这是不对的。执行 SQL
时, 不要更新无改动的字段,一是易出错; 二是效率低; 三是增加 binlog 存储。
之前写过要公用,但是这样子需求不断改变,加一个字段,少一个字段,这个pojo就得改正与维护,每一个都要加,而且
单词无意义,极难看懂,看似公用,但公用性很差,KISS法则是keep it simple Stupid
9. 【参考】 @Transactional 事务不要滥用。事务会影响数据库的 QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
9.1. 事务说经过的历程
摘自:https://blog.csdn.net/qq_29347295/article/details/79019221
https://blog.csdn.net/hjm4702192/article/details/8520354
9.2. 缓存回滚方案 摘自:
https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=404087915&idx=1&sn=075664193f334874a3fc87fd4f712ebc&scene=21#wechat_redirect
https://segmentfault.com/q/1010000012344110
@Transactional对redis没有效果,如何让缓存在异常时也回滚
三、先操作数据库 vs 先操作缓存
OK,当写操作发生时,假设淘汰缓存作为对缓存通用的处理方式,又面临两种抉择:
(1)先写数据库,再淘汰缓存
(2)先淘汰缓存,再写数据库
究竟采用哪种时序呢?
还记得在《冗余表如何保证数据一致性》文章(点击查看)里“究竟先写正表还是先写反表”的结论么?
对于一个不能保证事务性的操作,一定涉及“哪个任务先做,哪个任务后做”的问题,解决这个问题的方向是:
如果出现不一致,谁先做对业务的影响较小,就谁先执行。
由于写数据库与淘汰缓存不能保证原子性,谁先谁后同样要遵循上述原则。
假设先写数据库,再淘汰缓存:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致。

假设先淘汰缓存,再写数据库:第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次Cache miss。

结论:数据和缓存的操作时序,结论是清楚的:先淘汰缓存,再写数据库。
9.3 搜索引擎回滚
待补充
9.4 消息回滚
分布式事务RabbitMq 回滚策略,https://www.jianshu.com/p/eb7a36d25b2a
9.5 统计修正
这个也是涉及到了分布式事务,需要把旧数据用sql 强行回滚