CTR 预测理论(十一):神经网络激活函数优缺点总结
1. 激活函数的定义与作用
在人工神经网络中,神经元节点的激活函数定义了对神经元输出的映射,简单来说,神经元的输出(例如,全连接网络中就是输入向量与权重向量的内积再加上偏置项)经过激活函数处理后再作为输出。加拿大蒙特利尔大学的Bengio教授在 ICML 2016 的文章[1]中给出了激活函数的定义:激活函数是映射 h:R→R,且几乎处处可导。
神经网络中激活函数的主要作用是提供网络的非线性建模能力,如不特别说明,激活函数一般而言是非线性函数。假设一个示例神经网络中仅包含线性卷积和全连接运算,那么该网络仅能够表达线性映射,即便增加网络的深度也依旧还是线性映射,难以有效建模实际环境中非线性分布的数据。加入(非线性)激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。因此,激活函数是深度神经网络中不可或缺的部分。
从定义来看,几乎所有的连续可导函数都可以用作激活函数。但目前常见的多是分段线性和具有指数形状的非线性函数。下文将依次对它们进行总结。

2. 背景
深度学习的基本原理是基于人工神经网络,信号从一个神经元进入,经过非线性的activation function,传入到下一层神经元;再经过该层神经元的activate,继续往下传递,如此循环往复,直到输出层。正是由于这些非线性函数的反复叠加,才使得神经网络有足够的capacity来抓取复杂的pattern,在各个领域取得state-of-the-art的结果。显而易见,activation function在深度学习中举足轻重,也是很活跃的研究领域之一。目前来讲,选择怎样的activation function不在于它能否模拟真正的神经元,而在于能否便于优化整个深度神经网络。下面我们简单聊一下各类函数的特点以及为什么现在优先推荐ReLU函数。
3. 激活函数及优缺点
3.1 Sigmoid函数
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
下图展示了 Sigmoid 函数及其导数:
Sigmoid 激活函数

Sigmoid 导数
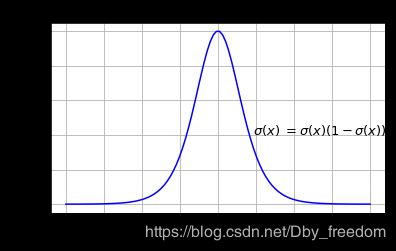
Sigmoid函数是深度学习领域开始时使用频率最高的activation function。它是便于求导的平滑函数,其导数为
σ ( x ) ( 1 − σ ( x ) ) \sigma(x)(1- \sigma(x)) σ(x)(1−σ(x)),这是优点。
优点:
-
便于求导的平滑函数;
-
能压缩数据,保证数据幅度不会有问题;
-
适合用于前向传播。
缺点:
-
容易出现梯度消失(gradient vanishing)
-
Sigmoid 的输出不是 0 均值(zero-centered)
-
幂运算相对耗时
Gradient Vanishing:
当激活函数接近饱和区时,变化太缓慢,导数接近0,根据后向传递的数学依据是微积分求导的链式法则,当前导数需要之前各层导数的乘积,几个比较小的数相乘,导数结果很接近0,从而无法完成深层网络的训练。
为了防止饱和,必须对于权重矩阵的初始化特别留意。比如,如果初始化权重过大,那么大多数神经元将会饱和,导致网络就几乎不学习。
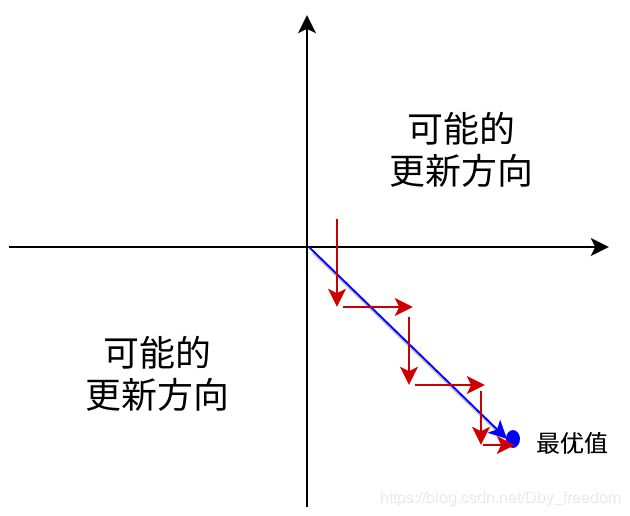
输出不是zero-centered
Sigmoid函数的输出值恒大于0,这会导致模型训练的收敛速度变慢。举例来讲,对 σ ( ∑ i w i x i + b ) \sigma(\sum_i w_i x_i + b) σ(∑iwixi+b),如果所有 x i x_i xi 均为正数或负数,那么其对 w i w_i wi 的导数总是正数或负数,这会导致如下图红色箭头所示的阶梯式更新,这显然并非一个好的优化路径。深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用 zero-centered 数据 (可以经过数据预处理实现) 和zero-centered 输出。
幂运算相对耗时:相对于前两项,这其实并不是一个大问题,我们目前是具备相应计算能力的,但面对深度学习中庞大的计算量,最好是能省则省)。之后我们会看到,在ReLU函数中,需要做的仅仅是一个thresholding,相对于幂运算来讲会快很多。
3.2 Tanh函数
tanh 表达式:
f ( x ) = e x − e − x e x + e − x f(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}} f(x)=ex+e−xex−e−x
tanh 变形:
t a n h ( x ) = 2 s i g m o i d ( 2 x ) − 1 tanh(x)=2sigmoid(2x)-1 tanh(x)=2sigmoid(2x)−1
这个变换从图像上可直接得出.
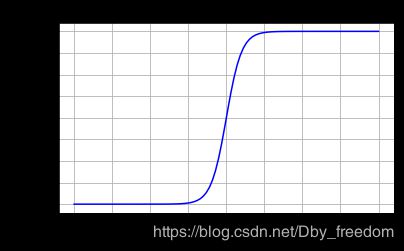
Tanh 激活函数
Tanh 导数
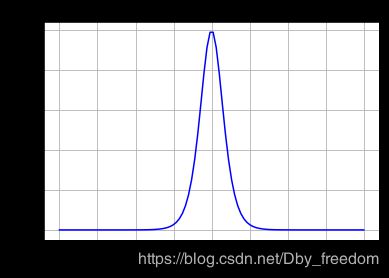
tanh 读作 Hyperbolic Tangent,tanh 函数将输入值压缩到 -1~1 的范围,**因此它是0均值的,解决了Sigmoid函数的非zero-centered问题,**但是它也存在梯度消失和幂运算的问题。
缺点:
- 容易出现梯度消失问题,在饱和时也会「杀死」梯度。
- 幂运算相对耗时
3.3 修正线性单元(ReLU)
Relu 表达式:
f ( x ) = { x x >= 0 0 x < 0 f(x) = \begin{cases} x& \text{x >= 0}\\ 0& \text{x < 0} \end{cases} f(x)={x0x >= 0x < 0
即:
f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x)
ReLU 激活函数
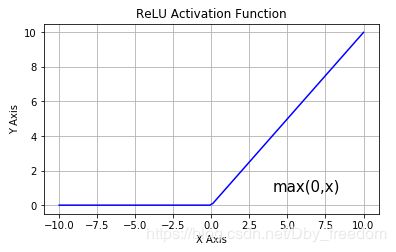
ReLU 导数

从上图可以看到,ReLU 是从底部开始半修正的一种函数。
当输入 x<0 时,输出为 0,当 x> 0 时,输出为 x。该激活函数使网络更快速地收敛。它不会饱和,即它可以对抗梯度消失问题,至少在正区域(x> 0 时)可以这样,因此神经元至少在一半区域中不会把所有零进行反向传播。由于使用了简单的阈值化(thresholding),ReLU 计算效率很高。
优点:
- 解决了gradient vanishing问题 (在正区间)
- 计算速度非常快,只需要判断输入是否大于0
- 收敛速度远快于sigmoid和tanh
缺点:
-
ReLU的输出不是zero-centered:
和 Sigmoid 激活函数类似,ReLU 函数的输出不以零为中心。
-
Dead ReLU Problem
指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生:
(1) 不合理的参数初始化,这种情况比较少见 ;
(2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。
Dead neuron 问题阐述:
作者:尹相楠
链接:https://www.zhihu.com/question/67151971/answer/434079498
假设某层网络权重为 W W W,输入为 x x x ,经过 R e L U \mathrm{ReLU} ReLU 激活后为 a a a。
首先复习一下神经网络的前向传播公式和反向传播公式。对反向传播公式,记忆方法是根据维度法,即求某个向量或矩阵的导数,乘完后看看这个导数的维度是否和原向量/矩阵相同。
前向传播公式为:
z = W ⋅ x a = R e L U ( z ) z=W\cdot x \\ \ \\ \ a = \mathrm{ReLU}(z) z=W⋅x a=ReLU(z)
设损失函数为 L L L,反向传播公式为:
∂ L ∂ z = ∂ L ∂ a ⋅ ∂ a ∂ z ∂ L ∂ W = ∂ L ∂ z ⋅ x T ∂ L ∂ x = W T ⋅ ∂ L ∂ z \frac{\partial L}{\partial z}=\frac{\partial L}{\partial a}\cdot\frac{\partial a}{\partial z} \\ \ \\ \ \frac{\partial L}{\partial W}=\frac{\partial L}{\partial z}\cdot x^T \\ \ \\ \ \frac{\partial L}{\partial x} = W^T\cdot \frac{\partial L}{\partial z} ∂z∂L=∂a∂L⋅∂z∂a ∂W∂L=∂z∂L⋅xT ∂x∂L=WT⋅∂z∂L
对固定的学习率 l r lr lr ,梯度 ∂ L ∂ W \frac{\partial L}{\partial W} ∂W∂L 越大,权重 W W W 更新的越多:
W = W + l r ⋅ ∂ L ∂ W W=W+lr\cdot \frac{\partial L}{\partial W} W=W+lr⋅∂W∂L
如果梯度太大,而学习率又不小心设置得太大,就会导致权重一下子更新过多,就有可能出现这种情况:对于任意训练样本 x i x_i xi,网络的输出都是小于0的。
z i = W ⋅ x i < 0 , ∀ x i ∈ D t r a i n i n g z_i = W\cdot x_i<0,\forall x_i\in D_{training} zi=W⋅xi<0,∀xi∈Dtraining
此时,根据 R e L U \mathrm{ReLU} ReLU 的激活函数
a i = m a x ( z i , 0 ) = 0 a_i = \mathrm{max}(z_i, 0)=0 ai=max(zi,0)=0
这会导致什么后果呢?我们不妨举下面这个简单的网络层为例:
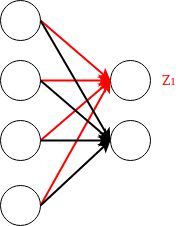
对于上面的网络结构, W W W 为 2 × 4 2\times4 2×4的矩阵,单个训练样本 x x x为 4 × 1 4\times 1 4×1 的向量。
为了方便,只研究红线连接的神经元(也就是权重矩阵 W W W 中的一行)。
z 1 = [ W 11 W 12 W 13 W 14 ] ⋅ [ x 1 x 2 x 3 x 4 ] z_1=\begin{bmatrix} W_{11}&W_{12}&W_{13}&W_{14} \end{bmatrix} \cdot \begin{bmatrix} x_{1}\\x_{2}\\x_{3}\\x_{4} \end{bmatrix} z1=[W11W12W13W14]⋅⎣⎢⎢⎡x1x2x3x4⎦⎥⎥⎤
假设这个时候的 W W W 是坏掉的,对所有的训练样本 x ⃗ \vec{x} x,输出的这个 z_1 始终是小于零的数。那么,
a 1 = R e L U ( z 1 ) = m a x ( z 1 , 0 ) = 0 a_1 = \mathrm{ReLU}(z_1)=\mathrm{max}(z_1, 0)=0 a1=ReLU(z1)=max(z1,0)=0
即,对于上面这个神经元,激活函数的输出始终为常数0 。回到前面的反向传播公式:
∂ L ∂ z 1 = ∂ L ∂ a 1 ⋅ ∂ a 1 ∂ z 1 \frac{\partial L}{\partial z_1} = \frac{\partial L}{\partial a_1}\cdot\frac{\partial a_1}{\partial z_1} ∂z1∂L=∂a1∂L⋅∂z1∂a1
其中,由于 z 1 z_1 z1 小于0时, a 1 a_1 a1 是常数 0。所以在 z 1 z_1 z1 小于0时始终有:
∂ a 1 ∂ z 1 = 0 \frac{\partial a_1}{\partial z_1}=0 ∂z1∂a1=0
所以导致:
∂ L ∂ z 1 = ∂ L ∂ a 1 ⋅ ∂ a 1 ∂ z 1 = ∂ L ∂ a 1 ⋅ 0 = 0 \frac{\partial L}{\partial z_1} = \frac{\partial L}{\partial a_1}\cdot\frac{\partial a_1}{\partial z_1}=\frac{\partial L}{\partial a_1}\cdot 0=0 ∂z1∂L=∂a1∂L⋅∂z1∂a1=∂a1∂L⋅0=0
而:
∂ L ∂ W 11 = ∂ L ∂ z 1 ⋅ x 1 ∂ L ∂ W 12 = ∂ L ∂ z 1 ⋅ x 2 ∂ L ∂ W 13 = ∂ L ∂ z 1 ⋅ x 3 ∂ L ∂ W 14 = ∂ L ∂ z 1 ⋅ x 4 \frac{\partial L}{\partial W_{11}}=\frac{\partial L}{\partial z_1}\cdot x_1 \\ \ \\ \ \frac{\partial L}{\partial W_{12}}=\frac{\partial L}{\partial z_1}\cdot x_2 \\ \ \\ \ \frac{\partial L}{\partial W_{13}}=\frac{\partial L}{\partial z_1}\cdot x_3 \\ \ \\ \ \frac{\partial L}{\partial W_{14}}=\frac{\partial L}{\partial z_1}\cdot x_4 ∂W11∂L=∂z1∂L⋅x1 ∂W12∂L=∂z1∂L⋅x2 ∂W13∂L=∂z1∂L⋅x3 ∂W14∂L=∂z1∂L⋅x4
向量化后即是:
∂ L ∂ W 1 ⋅ = ∂ L ∂ z 1 ⋅ x T \frac{\partial L}{\partial W_{1\cdot}}=\frac{\partial L}{\partial z_1}\cdot x^T ∂W1⋅∂L=∂z1∂L⋅xT
可以发现:
∂ L ∂ W 1 ⋅ = 0 ⃗ T \frac{\partial L}{\partial W_{1\cdot}}=\vec{0}^T ∂W1⋅∂L=0T
这就出问题了,对于权重矩阵 W W W 的第一行的参数,在整个训练集上,损失函数对它的导数始终为零,也就是说,遍历了整个训练集,它的参数都没有更新。因此就说该神经元死了……
解决方案:
1. 把 R e L U \mathrm{ReLU} ReLU 换成 L e a k y \mathrm{Leaky} Leaky R e L U \mathrm{ReLU} ReLU,保证让激活函数在输入小于零的情况下也有非零的输出。
2. 采用较小的学习率
3. adagrad 等自动调节 learning rate 的优化算法,动态调整学习率
4. 可以采用 Xavier 初始化方法
当 x = 0 时,该点的梯度未定义,但是这个问题在实现中得到了解决,通过采用左侧或右侧的梯度的方式。
实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都”dead”了。
当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
3.4 Leaky ReLU

Leaky ReLU 激活函数:
该函数试图缓解 dead ReLU 问题。数学公式为:
f ( x ) = m a x ( 0.1 x , x ) f(x) = max(0.1x, x) f(x)=max(0.1x,x)
Leaky ReLU 的概念是:当 x < 0 时,它得到 0.1 的正梯度。该函数一定程度上缓解了 dead ReLU 问题,但是使用该函数的结果并不连贯。尽管它具备 ReLU 激活函数的所有特征,如计算高效、快速收敛、在正区域内不会饱和。
Leaky ReLU 可以得到更多扩展。不让 x 乘常数项,而是让 x 乘超参数,这看起来比 Leaky ReLU 效果要好。该扩展就是 Parametric ReLU,即 PRelu。
3.5 Parametric ReLU
PReLU 函数的数学公式为:
f ( x ) = m a x ( a x , x ) f(x) = max(ax,x) f(x)=max(ax,x)
其中 α \alpha α 是超参数。这里引入了一个随机的超参数 α \alpha α ,它可以被学习,因为你可以对它进行反向传播。这使神经元能够选择负区域最好的梯度,有了这种能力,它们可以变成 ReLU 或 Leaky ReLU。
总之,最好使用 ReLU,但是你可以使用 Leaky ReLU 或 Parametric ReLU 实验一下,看看它们是否更适合你的问题。
3.6 ELU (Exponential Linear Units) 函数

ELU也是为解决ReLU存在的问题而提出,显然,ELU有ReLU的基本所有优点,以及:
- 不会有Dead ReLU问题
- 输出的均值接近0,zero-centered
它的一个小问题在于计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
3.7 softmax函数 (也称归一化指数函数)
可以看到,Sigmoid函数实际上就是把数据映射到一个(0,1)的空间上,也就是说,Sigmoid函数如果用来分类的话,只能进行二 分类,而这里的softmax函数可以看做是Sigmoid函数的一般化,可以进行多分类。
Softmax - 用于多分类神经网络输出:
σ ( x ) = e z j ∑ k = 1 K e z k \sigma(x) = \frac{e^{z_j}}{\sum_{k=1}^{K}e^{z_k}} σ(x)=∑k=1Kezkezj
举个例子来看公式的意思:
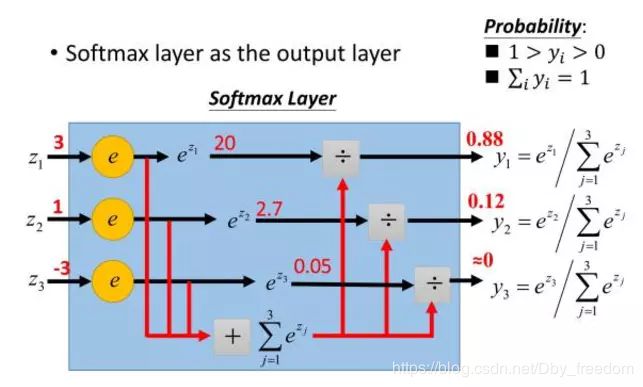
为什么要取指数,第一个原因是要模拟 max 的行为,所以要让大的更大。
第二个原因是需要一个可导的函数。

3.7 Maxout
Maxout出现在ICML2013上,作者Goodfellow将maxout和dropout结合后,号称在MNIST, CIFAR-10, CIFAR-100, SVHN这4个数据上都取得了start-of-art的识别率。
Maxout可以看做是在深度学习网络中加入一层激活函数层,包含一个参数k.这一层相比ReLU,sigmoid等,其特殊之处在于增加了k个神经元,然后输出激活值最大的值.
我们常见的隐含层节点输出:
h i ( x ) = sigmoid ( x T W … i + b i ) h_i(x)=\text{sigmoid}(x^TW_{…i}+b_i) hi(x)=sigmoid(xTW…i+bi)
而在Maxout网络中,其隐含层节点的输出表达式为:
f i ( x ) = m a x j ∈ [ 1 , k ] z i j f_i(x)=max_{j\in [1,k]}z_{ij} fi(x)=maxj∈[1,k]zij
其中 z i j = x T W … i j + b i j , W ∈ R d × m × k z_{ij}=x^TW_{…ij}+b_{ij}, W\in R^{d\times m\times k} zij=xTW…ij+bij,W∈Rd×m×k
假设 w w w 是 2 维,那么有:
f ( x ) = m a x ( w 1 T x + b 1 , w 2 T x + b 2 ) f(x)=max(w_1^Tx+b_1,w_2^Tx+b_2) f(x)=max(w1Tx+b1,w2Tx+b2)
可以注意到,ReLU 和 Leaky ReLU 都是它的一个变形(比如, w 1 , b 1 = 0 w_1, b_1 = 0 w1,b1=0 的时候,就是 ReLU).
以如下最简单的多层感知器(MLP)为例:
Maxout激活函数
与常规激活函数不同的是,它是一个可学习的分段线性函数.
然而任何一个凸函数,都可以由线性分段函数进行逼近近似。其实我们可以把以前所学到的激活函数:ReLU、abs激活函数,看成是分成两段的线性函数,如下示意图所示:

实验结果表明Maxout与Dropout组合使用可以发挥比较好的效果。
Maxout的拟合能力是非常强的,它可以拟合任意的的凸函数。作者从数学的角度上也证明了这个结论,即只需2个 maxout 节点就可以拟合任意的凸函数了(相减),前提是”隐隐含层”节点的个数可以任意多.
这样 Maxout 神经元就拥有 ReLU 单元的所有优点(线性和不饱和),而没有它的缺点(死亡的ReLU单元)。然而和 ReLU 对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。
Maxout 激活函数特点:
-
maxout激活函数并不是一个固定的函数,不像Sigmod、Relu、Tanh等函数,是一个固定的函数方程
-
它是一个可学习的激活函数,因为我们 W 参数是学习变化的。
-
它是一个分段线性函数:
优点:
- Maxout的拟合能力非常强,可以拟合任意的凸函数。
- Maxout具有ReLU的所有优点,线性、不饱和性。
- 同时没有ReLU的一些缺点。如:神经元的死亡。
缺点:
从上面的激活函数公式中可以看出,每个神经元中有两组(w,b)参数,那么参数量就增加了一倍,这就导致了整体参数的数量激增。
详细解释可参考此博客:https://blog.csdn.net/hjimce/article/details/50414467
4. 小结
建议使用ReLU函数,但是要注意初始化和learning rate的设置;可以尝试使用Leaky ReLU或ELU函数;不建议使用tanh,尤其是sigmoid函数。
参考资料
-
Udacity Deep Learning Courses
-
Stanford CS231n Course
-
激活函数(ReLU, Swish, Maxout)
-
[机器学习] 常用激活函数的总结与比较
-
一文概览深度学习中的激活函数
-
【机器学习】神经网络-激活函数-面面观(Activation Function)
-
常用激活函数比较
-
深度学习(二十三)Maxout网络学习