机器学习笔记(三):一个完整的机器学习项目
开篇
波折了一个多月,顺利在华为实习,在晚上加班的空余时间继续刷我的机器学习笔记。
要点提示
缺失值填充
查找关联
前面我们通过画图分析了一些数据的相关属性。因为数据集并不是非常大,我们可以很容易地使用corr()方法计算出每对属性间的标准相关系数(standard correlation coefficient,也称作皮尔逊相关系数):
corr_matrix = housing.corr()现在来看下每个属性和房价中位数的关联度:
>>> corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.687170
total_rooms 0.135231
housing_median_age 0.114220
households 0.064702
total_bedrooms 0.047865
population -0.026699
longitude -0.047279
latitude -0.142826
Name: median_house_value, dtype: float64相关系数的范围是 -1 到 1。当接近 1 时,意味强正相关;例如,当收入中位数增加时,房价中位数也会增加。当相关系数接近 -1 时,意味强负相关;你可以看到,纬度和房价中位数有轻微的负相关性(即,越往北,房价越可能降低)。最后,相关系数接近 0,意味没有线性相关性。图 2-14 展示了相关系数在横轴和纵轴之间的不同图形。
警告:相关系数只测量线性关系(如果x上升,y则上升或下降)。相关系数可能会完全忽略非线性关系(例如,如果x接近 0,则y值会变高)。在上面图片的最后一行中,他们的相关系数都接近于 0,尽管它们的轴并不独立:这些就是非线性关系的例子。另外,第二行的相关系数等于 1 或 -1;这和斜率没有任何关系。例如,你的身高(单位是英寸)与身高(单位是英尺或纳米)的相关系数就是 1。
另一种检测属性间相关系数的方法是使用 Pandas 的scatter_matrix函数,它能画出每个数值属性对每个其它数值属性的图。因为现在共有 11 个数值属性,你可以得到11 ** 2 = 121张图,在一页上画不下,所以只关注几个和房价中位数最有可能相关的属性
from pandas.tools.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))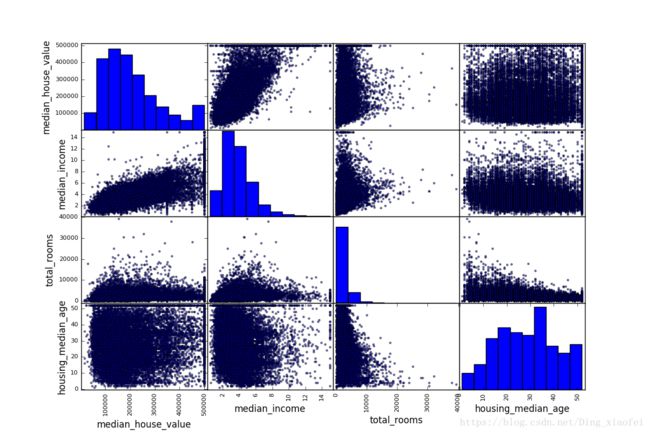
如果 pandas 将每个变量对自己作图,主对角线(左上到右下)都会是直线图。所以 Pandas 展示的是每个属性的柱状图(也可以是其它的,请参考 Pandas 文档)。
最有希望用来预测房价中位数的属性是收入中位数,因此将这张图放大(图 2-16):
housing.plot(kind="scatter", x="median_income",y="median_house_value",
alpha=0.1)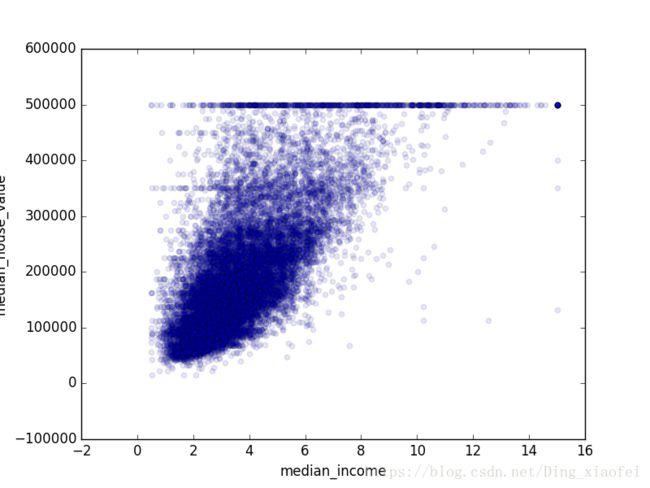
这张图说明了几点。首先,相关性非常高;可以清晰地看到向上的趋势,并且数据点不是非常分散。第二,我们之前看到的最高价,清晰地呈现为一条位于 500000 美元的水平线。这张图也呈现了一些不是那么明显的直线:一条位于 450000 美元的直线,一条位于 350000 美元的直线,一条在 280000 美元的线,和一些更靠下的线。你可能希望去除对应的街区,以防止算法重复这些巧合。
属性组合试验
希望前面的一节能教给你一些探索数据、发现规律的方法。你发现了一些数据的巧合,需要在给算法提供数据之前,将其去除。你还发现了一些属性间有趣的关联,特别是目标属性。你还注意到一些属性具有长尾分布,因此你可能要将其进行转换(例如,计算其log对数)。当然,不同项目的处理方法各不相同,但大体思路是相似的。
给算法准备数据之前,你需要做的最后一件事是尝试多种属性组合。例如,如果你不知道某个街区有多少户,该街区的总房间数就没什么用。你真正需要的是每户有几个房间。相似的,总卧室数也不重要:你可能需要将其与房间数进行比较。每户的人口数也是一个有趣的属性组合。让我们来创建这些新的属性:
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]现在,再来看相关矩阵:
>>> corr_matrix = housing.corr()
>>> corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.687170
rooms_per_household 0.199343
total_rooms 0.135231
housing_median_age 0.114220
households 0.064702
total_bedrooms 0.047865
population_per_household -0.021984
population -0.026699
longitude -0.047279
latitude -0.142826
bedrooms_per_room -0.260070
Name: median_house_value, dtype: float64看起来不错!与总房间数或卧室数相比,新的bedrooms_per_room属性与房价中位数的关联更强。显然,卧室数/总房间数的比例越低,房价就越高。每户的房间数也比街区的总房间数的更有信息,很明显,房屋越大,房价就越高。
这一步的数据探索不必非常完备,此处的目的是有一个正确的开始,快速发现规律,以得到一个合理的原型。但是这是一个交互过程:一旦你得到了一个原型,并运行起来,你就可以分析它的输出,进而发现更多的规律,然后再回到数据探索这步。
为机器学习算法准备数据
现在来为机器学习算法准备数据。不要手工来做,你需要写一些函数,理由如下:
- 函数可以让你在任何数据集上(比如,你下一次获取的是一个新的数据集)方便地进行重复数据转换。
- 你能慢慢建立一个转换函数库,可以在未来的项目中复用。
- 在将数据传给算法之前,你可以在实时系统中使用这些函数。
这可以让你方便地尝试多种数据转换,查看哪些转换方法结合起来效果最好。
但是,还是先回到干净的训练集(通过再次复制strat_train_set),将预测量和标签分开,因为我们不想对预测量和目标值应用相同的转换(注意drop()创建了一份数据的备份,而不影响strat_train_set):
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()数据清洗
大多机器学习算法不能处理缺失的特征,因此先创建一些函数来处理特征缺失的问题。前面,你应该注意到了属性total_bedrooms有一些缺失值。有三个解决选项:
- 去掉对应的街区;
- 去掉整个属性;
- 进行赋值(0、平均值、中位数等等)
用DataFrame的dropna(),drop(),和fillna()方法,可以方便地实现:
housing.dropna(subset=["total_bedrooms"]) # 选项1
housing.drop("total_bedrooms", axis=1) # 选项2
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median) # 选项3如果选择选项 3,你需要计算训练集的中位数,用中位数填充训练集的缺失值,不要忘记保存该中位数。后面用测试集评估系统时,需要替换测试集中的缺失值,也可以用来实时替换新数据中的缺失值。
Scikit-Learn 提供了一个方便的类来处理缺失值:Imputer。下面是其使用方法:首先,需要创建一个Imputer实例,指定用某属性的中位数来替换该属性所有的缺失值:
from sklearn.preprocessing import Imputer
imputer = Imputer(strategy="median")因为只有数值属性才能算出中位数,我们需要创建一份不包括文本属性ocean_proximity的数据副本:
housing_num = housing.drop("ocean_proximity", axis=1)现在,就可以用fit()方法将imputer实例拟合到训练数据:
imputer.fit(housing_num)imputer计算出了每个属性的中位数,并将结果保存在了实例变量statistics_中。虽然此时只有属性total_bedrooms存在缺失值,但我们不能确定在以后的新的数据中会不会有其他属性也存在缺失值,所以安全的做法是将imputer应用到每个数值:
>>> imputer.statistics_
array([ -118.51 , 34.26 , 29. , 2119. , 433. , 1164. , 408. , 3.5414]) >>> housing_num.median().values array([ -118.51 , 34.26 , 29. , 2119. , 433. , 1164. , 408. , 3.5414])现在,你就可以使用这个“训练过的”imputer来对训练集进行转换,将缺失值替换为中位数:
X = imputer.transform(housing_num)结果是一个包含转换后特征的普通的 Numpy 数组。如果你想将其放回到 PandasDataFrame中,也很简单:
housing_tr = pd.DataFrame(X, columns=housing_num.columns)Scikit-Learn 设计
Scikit-Learn 设计的 API 设计的非常好。它的主要设计原则是:
- 一致性:所有对象的接口一致且简单:
估计器(estimator)。任何可以基于数据集对一些参数进行估计的对象都被称为估计器(比如,imputer就是个估计器)。估计本身是通过fit()方法,只需要一个数据集作为参数(对于监督学习算法,需要两个数据集;第二个数据集包含标签)。任何其它用来指导估计过程的参数都被当做超参数(比如imputer的strategy),并且超参数要被设置成实例变量(通常通过构造器参数设置)。
转换器(transformer)。一些估计器(比如imputer)也可以转换数据集,这些估计器被称为转换器。API也是相当简单:转换是通过transform()方法,被转换的数据集作为参数。返回的是经过转换的数据集。转换过程依赖学习到的参数,比如imputer的例子。所有的转换都有一个便捷的方法fit_transform(),等同于调用fit()再transform()(但有时fit_transform()经过优化,运行的更快)。
预测器(predictor)。最后,一些估计器可以根据给出的数据集做预测,这些估计器称为预测器。例如,上一章的LinearRegression模型就是一个预测器:它根据一个国家的人均 GDP 预测生活满意度。预测器有一个predict()方法,可以用新实例的数据集做出相应的预测。预测器还有一个score()方法,可以根据测试集(和相应的标签,如果是监督学习算法的话)对预测进行衡器。
可检验。所有估计器的超参数都可以通过实例的public变量直接访问(比如,imputer.strategy),并且所有估计器学习到的参数也可以通过在实例变量名后加下划线来访问(比如,imputer.statistics_)。 - 类不可扩散。数据集被表示成 NumPy 数组或 SciPy 稀疏矩阵,而不是自制的类。超参数只是普通的 Python 字符串或数字。
- 可组合。尽可能使用现存的模块。例如,用任意的转换器序列加上一个估计器,就可以做成一个流水线,后面会看到例子。
- 合理的默认值。Scikit-Learn 给大多数参数提供了合理的默认值,很容易就能创建一个系统。
处理文本和类别属性
前面,我们丢弃了类别属性ocean_proximity,因为它是一个文本属性,不能计算出中位数。大多数机器学习算法跟喜欢和数字打交道,所以让我们把这些文本标签转换为数字。
Scikit-Learn 为这个任务提供了一个转换器LabelEncoder:
>>> encoder = LabelEncoder()
>>> housing_cat = housing["ocean_proximity"]
>>> housing_cat_encoded = encoder.fit_transform(housing_cat)
>>> housing_cat_encoded
array([1, 1, 4, ..., 1, 0, 3])译注:
在原书中使用LabelEncoder转换器来转换文本特征列的方式是错误的,该转换器只能用来转换标签(正如其名)。在这里使用LabelEncoder没有出错的原因是该数据只有一列文本特征值,在有多个文本特征列的时候就会出错。应使用factorize()方法来进行操作:
housing_cat_encoded, housing_categories = housing_cat.factorize() housing_cat_encoded[:10]好了一些,现在就可以在任何 ML 算法里用这个数值数据了。你可以查看映射表,编码器是通过属性classes_来学习的(<1H OCEAN被映射为 0,INLAND被映射为 1,等等):
>>> print(encoder.classes_)
['<1H OCEAN' 'INLAND' 'ISLAND' 'NEAR BAY' 'NEAR OCEAN']