Python3识别图片文字
Python3识别图片文字
一、Pillow, pytesseract库的安装(Python 3.5)
PIL全称:Python Imaging Library,python图像处理库,这个库支持多种文件格式,并提供了强大的图像处理和图形处理能力。由于PIL仅支持到Python 2.7,所以在PIL的基础上创建了Pillow库,支持最新Python 3.x。
pip install pillow
pip install pytesseract
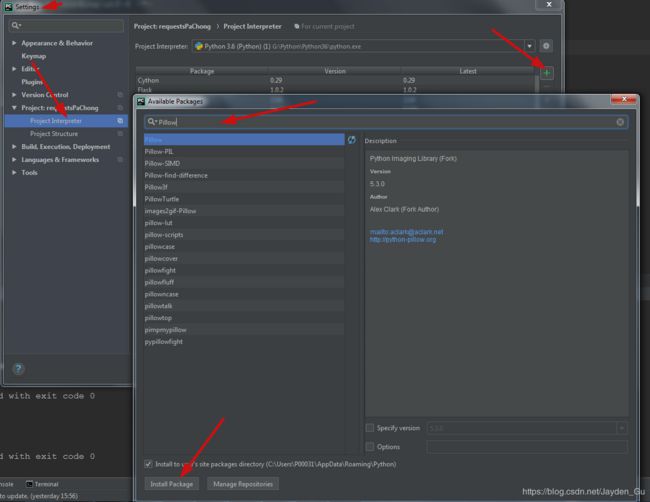
如果你使用的是Pycharm工具的话,你可以找到File->Settings->Project Interpreter下,点击“+”号,在搜索的页面中输入以上两个库,进行安装。
二、tesseract-ocr图片文字的识别引擎的安装
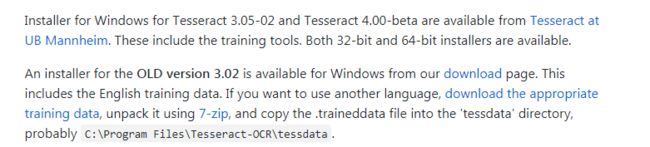
- 下载地址:https://github.com/tesseract-ocr/tesseract/wiki/Downloads
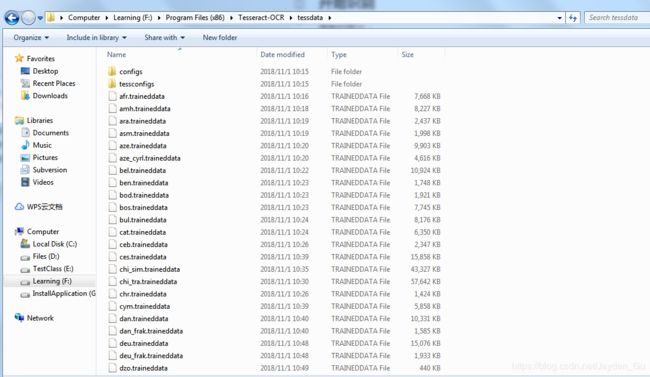
- 安装注意: 因为下载的包中已包含了所有语言,但需要在安装过程中由用户自己选择安装哪些语言(我是全选,主要是懒,哈哈),然后再安装。
- 配制方式有两种:
方式一:将安装的路径(如: F:\Program Files (x86)\Tesseract-OCR)添加到系统环境变量:Path;
方式二:找到Python的安装目录(比如:G:\Python\Python36\Lib\site-packages\pytesseract), 打开pytesseract.py 并修改以下内容:
# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY
#tesseract_cmd = 'tesseract'
tesseract_cmd = 'F:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
----------------------------------------------------------华丽的分割线------------------------------------------------------------
三、开始识别
准备的图片:
# -*- cording:utf-8 -*-
from PIL import Image
import pytesseract
img = Image.open("eeee.png")
text = pytesseract.image_to_string(img, lang='eng') #如果图片是中文,将lang='chi_sim'(此为tesseract-ocr中语言包下的各语言名称)
print(text)
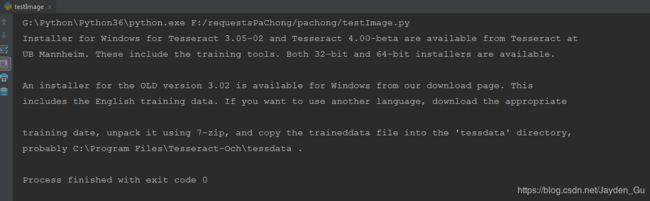
运行结果如下: