深度学习----现今主流GAN原理总结及对比
-
-
- 1.GAN
- 2.CGAN
- 3.DCGAN
- 4.WGAN
- 5.WGAN-GP
- 6.LSGAN
- 7.BEGAN
- 8.GAN的基本代码
-
1.GAN
先来看看公式:
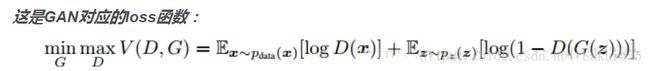
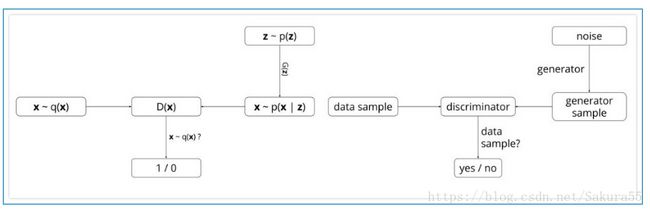
GAN网络主要由两个网络构成,生成网络G和辨别网络D,生成模型G的思想是将一个噪声包装成一个逼真的样本,判别模型D则需要判断送入的样本是真实的还是假的样本,即共同进步的过程,辨别模型D对样本的判别能力不断上升,生成模型G的造假能力也不断上升!
需要注意的是,生成模型G的输入是服从-1~1均匀分布的随机变量,输出为一张图片(或者其他,这里我们需要图片而已),因此,生成网络的结构是一个反卷积网络,即对应CNN中的可视化操作,由随机变量生成图片的过程!
GAN则是在学习从随机变量到训练样本的映射关系,其中随机变量可以选择服从正太分布,那么就能得到一个由多层感知机组成的生成网络,网络的输入是一个一维的随机变量,输出是一张图片。如何让输出的伪造图片看起来像训练样本,Goodfellow采用了这样一种方法,在生成网络后面接上一个多层感知机组成的判别网络,这个网络的输入是随机选择一张真实样本或者生成网络的输出,输出是输入图片来自于真实样本或者生成网络的概率,当判别网络能够很好的分辨出输入是不是真实样本时,也能通过梯度的方式说明什么样的输入更加像真实样本,从而通过这个信息来调整生成网络。从而需要尽可能的让自己的输出像真实样本,而则尽可能的将不是真实样本的情况分辨出来。
下图左边是GAN算法的概率解释,右边是模型构成。
GAN的优化是一个极小极大博弈问题,最终的目的是generator的输出给discriminator时很难判断是真实or伪造的,即极大化的判断能力,极小化将的输出判断为伪造的概率,公式如下。论文[5]中将下面式子转化成了Jensen-shannon散度的形式证明了仅当时能得到全局最小值,即生成网络能完全的还原出真实样本分布,并且证明了下式能够收敛。(算法流程论文讲的很清楚,这里就不说了,后面结合代码一起解释。)
以上是关于最基本GAN的介绍,最开始我看了论文后产生了几个疑问,
1.为什么不能直接学习,即直接学习一个到一个?
2.具体是如何训练的?
3.在训练的时候跟是一一对应关系吗?在对代码理解之后大概能够给出一个解释。
- 代码解释
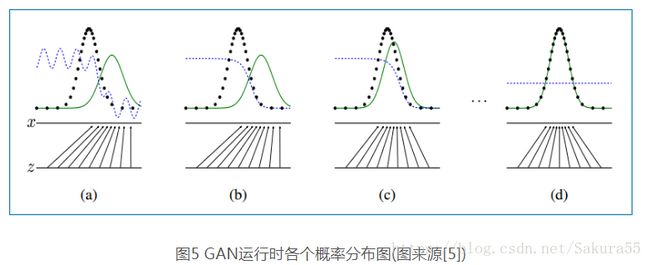
这部分主要结合tensorflow实现代码[7]、算法流程和下面的变化图[5]解释一下具体如何使用DCGAN来生成手写体图片。
下图中黑色虚线是真实数据的高斯分布,绿色的线是生成网络学习到的伪造分布,蓝色的线是判别网络判定为真实图片的概率,标x的横线代表服从高斯分布x的采样空间,标z的横线代表服从均匀分布z的采样空间。可以看出就是学习了从z的空间到x的空间的映射关系。
2.CGAN
条件GAN
原始GAN 提出,与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了。
为了解决GAN太过自由这个问题,一个很自然的想法是给GAN加一些约束,于是便有了Conditional Generative Adversarial Nets(CGAN)【Mirza M, Osindero S. Conditional】。这项工作提出了一种带条件约束的GAN,在生成模型(D)和判别模型(G)的建模中均引入条件变量y(conditional variable y),使用额外信息y对模型增加条件,可以指导数据生成过程。这些条件变量y可以基于多种信息,例如类别标签,用于图像修复的部分数据[2],来自不同模态(modality)的数据。如果条件变量y是类别标签,可以看做CGAN 是把纯无监督的 GAN 变成有监督的模型的一种改进。这个简单直接的改进被证明非常有效,并广泛用于后续的相关工作中[3,4]。Mehdi Mirza et al. 的工作是在MNIST数据集上以类别标签为条件变量,生成指定类别的图像。作者还探索了CGAN在用于图像自动标注的多模态学习上的应用,在MIR Flickr25000数据集上,以图像特征为条件变量,生成该图像的tag的词向量。
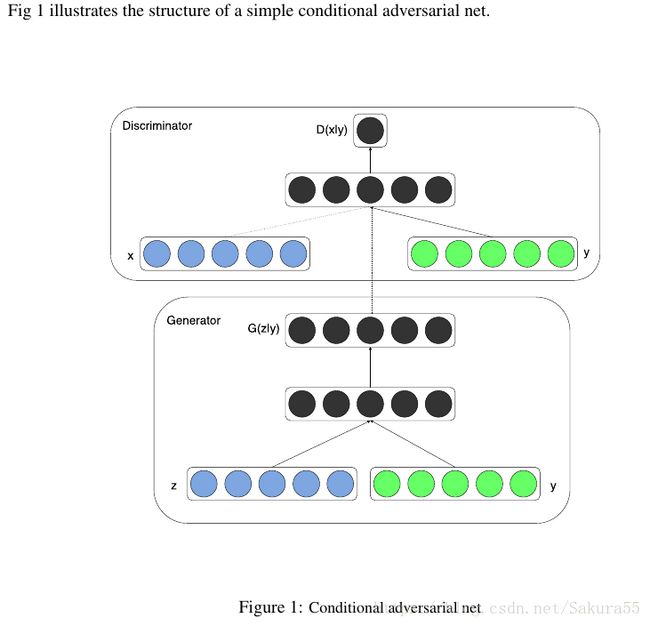
Conditional Adversarial Nets结构
条件生成式对抗网络(CGAN)是对原始GAN的一个扩展,生成器和判别器都增加额外信息y为条件, y可以使任意信息,例如类别信息,或者其他模态的数据。如Figure 1所示,通过将额外信息y输送给判别模型和生成模型,作为输入层的一部分,从而实现条件GAN。在生成模型中,先验输入噪声p(z)和条件信息y联合组成了联合隐层表征。对抗训练框架在隐层表征的组成方式方面相当地灵活。类似地,条件GAN的目标函数是带有条件概率的二人极小极大值博弈(two-player minimax game ):
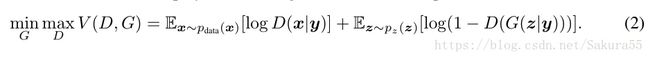
3.DCGAN
【github】地址 :
https://github.com/Newmu/dcgan_code theano
;https://github.com/carpedm20/DCGAN-tensorflow tensorflow
https://github.com/jacobgil/keras-dcgan keras
https://github.com/soumith/dcgan.torch torch
DCGAN是继GAN之后比较好的改进,其主要的改进主要是在网络结构上,到目前为止,DCGAN的网络结构还是被广泛的使用,DCGAN极大的提升了GAN训练的稳定性以及生成结果质量。
论文的主要贡献是:
◆ 为GAN的训练提供了一个很好的网络拓扑结构。
◆表明生成的特征具有向量的计算特性。
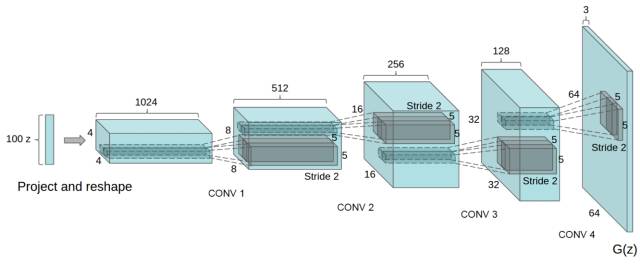
DCGAN的生成器网络结构如上图所示,相较原始的GAN,DCGAN几乎完全使用了卷积层代替全链接层,判别器几乎是和生成器对称的,从上图中我们可以看到,整个网络没有pooling层和上采样层的存在,实际上是使用了带步长(fractional-strided)的卷积代替了上采样,以增加训练的稳定性。
DCGAN能改进GAN训练稳定的原因主要有:
◆ 使用步长卷积代替上采样层,卷积在提取图像特征上具有很好的作用,并且使用卷积代替全连接层。
◆ 生成器G和判别器D中几乎每一层都使用batchnorm层,将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。(生成器的最后一层和判别器的第一层不加batchnorm)
◆ 在判别器中使用leakrelu激活函数,而不是RELU,防止梯度稀疏,生成器中仍然采用relu,但是输出层采用tanh。
◆ 使用adam优化器训练,并且学习率最好是**`0.0002`**,(我也试过其他学习率,不得不说0.0002是表现最好的了)
DCGAN结果图:
矢量计算:

LSUN数据集上的结果:

DCGAN虽然有很好的架构,但是对GAN训练稳定性来说是治标不治本,没有从根本上解决问题,而且训练的时候仍需要小心的平衡G,D的训练进程,往往是训练一个多次,训练另一个一次。
4.WGAN
【GitHub】:
https://github.com/hwalsuklee/tensorflow-generative-model-collections
https://github.com/Zardinality/WGAN-tensorflow
与DCGAN不同,WGAN主要从损失函数的角度对GAN做了改进,损失函数改进之后的WGAN即使在全链接层上也能得到很好的表现结果,WGAN对GAN的改进主要有:
◆ 判别器最后一层去掉sigmoid
◆ 生成器和判别器的loss不取log
◆ 对更新后的权重强制截断到一定范围内,比如[-0.01,0.01],以满足论文中提到的lipschitz连续性条件。
◆ 论文中也推荐使用SGD, RMSprop等优化器,不要基于使用动量的优化算法,比如adam,但是就我目前来说,训练GAN时,我还是adam用的多一些。
从上面看来,WGAN好像在代码上很好实现,基本上在原始GAN的代码上不用更改什么,但是它的作用是巨大的。
◆ WGAN理论上给出了GAN训练不稳定的原因,即交叉熵(JS散度)不适合衡量具有不相交部分的分布之间的距离,转而使用wassertein距离去衡量生成数据分布和真实数据分布之间的距离,理论上解决了训练不稳定的问题。
◆ 解决了模式崩溃的(collapse mode)问题,生成结果多样性更丰富。
◆ 对GAN的训练提供了一个指标,此指标数值越小,表示GAN训练的越差,反之越好。可以说之前训练GAN完全就和买彩票一样,训练好了算你中奖,没中奖也不要气馁,多买几注吧。
有关GAN和WGAN的解释,可以参考链接:https://zhuanlan.zhihu.com/p/25071913
总的来说,GAN中交叉熵(JS散度)不适合衡量生成数据分布和真实数据分布的距离,如果通过优化JS散度训练GAN会导致找不到正确的优化目标,所以,WGAN提出使用wassertein距离作为优化方式训练GAN,但是数学上和真正代码实现上还是有区别的,使用Wasserteion距离需要满足很强的连续性条件—lipschitz连续性,为了满足这个条件,作者使用了将权重限制到一个范围的方式强制满足lipschitz连续性,但是这也造成了隐患,接下来会详细说。另外说实话,虽然理论证明很漂亮,但是实际上训练起来,以及生成结果并没有期待的那么好。
注:Lipschitz限制是在样本空间中,要求判别器函数D(x)梯度值不大于一个有限的常数K,通过权重值限制的方式保证了权重参数的有界性,间接限制了其梯度信息。
5.WGAN-GP
(improved wgan)
【GitHub】:
https://link.zhihu.com/?target=https%3A//github.com/igul222/improved_wgan_training
https://github.com/caogang/wgan-gp
WGAN-GP是WGAN之后的改进版,主要还是改进了连续性限制的条件,因为,作者也发现将权重剪切到一定范围之后,比如剪切到[-0.01,+0.01]后,发生了这样的情况,如下图左边表示。

发现大多数的权重都在-0.01 和0.01上,这就意味了网络的大部分权重只有两个可能数,对于深度神经网络来说不能充分发挥深度神经网络的拟合能力,简直是极大的浪费。并且,也发现强制剪切权重容易导致梯度消失或者梯度爆炸,梯度消失很好理解,就是权重得不到更新信息,梯度爆炸就是更新过猛了,权重每次更新都变化很大,很容易导致训练不稳定。梯度消失与梯度爆炸原因均在于剪切范围的选择,选择过小的话会导致梯度消失,如果设得稍微大了一点,每经过一层网络,梯度变大一点点,多层之后就会发生梯度爆炸 。为了解决这个问题,并且找一个合适的方式满足lipschitz连续性条件,作者提出了使用梯度惩罚(gradient penalty)的方式以满足此连续性条件,其结果如上图右边所示。
梯度惩罚就是既然Lipschitz限制是要求判别器的梯度不超过K,那么可以通过建立一个损失函数来满足这个要求,即先求出判别器的梯度d(D(x)),然后建立与K之间的二范数就可以实现一个简单的损失函数设计。但是注意到D的梯度的数值空间是整个样本空间,对于图片(既包含了真实数据集也包含了生成出的图片集)这样的数据集来说,维度及其高,显然是及其不适合的计算的。作者提出没必要对整个数据集(真的和生成的)做采样,只要从每一批次的样本中采样就可以了,比如可以产生一个随机数,在生成数据和真实数据上做一个插值
![]()
于是就算解决了在整个样本空间上采样的麻烦。
所以WGAN-GP的贡献是:
◆ 提出了一种新的lipschitz连续性限制手法—梯度惩罚,解决了训练梯度消失梯度爆炸的问题。
◆ 比标准WGAN拥有更快的收敛速度,并能生成更高质量的样本
◆ 提供稳定的GAN训练方式,几乎不需要怎么调参,成功训练多种针对图片生成和语言模型的GAN架构
但是论文提出,由于是对每个batch中的每一个样本都做了梯度惩罚(随机数的维度是(batchsize,1)),因此判别器中不能使用batch norm,但是可以使用其他的normalization方法,比如Layer Normalization、Weight Normalization和Instance Normalization,论文中使用了Layer Normalization,weight normalization效果也是可以的。为了比较,还是祭出了下面这张图,可以发现WGAN-GP完爆其他GAN:

6.LSGAN
最小二乘GAN
全称是Least Squares Generative Adversarial Networks
【github】
https://github.com/hwalsuklee/tensorflow-generative-model-collections
https://github.com/guojunq/lsgan
LSGAN原理:
其实原理部分可以一句话概括,即使用了最小二乘损失函数代替了GAN的损失函数。
但是就这样的改变,缓解了GAN训练不稳定和生成图像质量差多样性不足的问题。事实上,作者认为使用JS散度并不能拉近真实分布和生成分布之间的距离,使用最小二乘可以将图像的分布尽可能的接近决策边界,其损失函数定义如下:
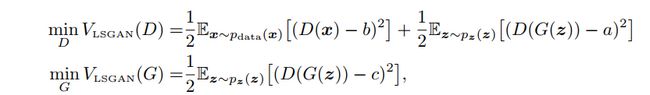
其中作者设置a=c=1,b=0论文里还是给了一些数学推导与证明,感兴趣的可以去看看生成结果展示:

7.BEGAN
(不是EBGAN)
BEGAN全称是Boundary Equilibrium GANs
【GitHub】:
https://github.com/carpedm20/BEGAN-tensorflow
https://github.com/Heumi/BEGAN-tensorflow
https://github.com/carpedm20/BEGAN-pytorch
BEGAN的主要贡献:
◆ 提出了一种新的简单强大GAN,使用标准的训练方式,不加训练trick也能很快且稳定的收敛
◆ 对于GAN中G,D的能力的平衡提出了一种均衡的概念(GAN的理论基础就是goodfellow理论上证明了GAN均衡点的存在,但是一直没有一个准确的衡量指标说明GAN的均衡程度)
◆ 提出了一种收敛程度的估计,这个机制只在WGAN中出现过。作者在论文中也提到,他们的灵感来自于WGAN,在此之前只有wgan做到了
◆ 提出了一种收敛程度的估计,这个机制只在WGAN中出现过。作者在论文中也提到,他们的灵感来自于WGAN
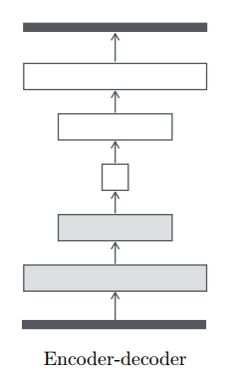
先说说BEGAN的主要原理,BEGAN和其他GAN不一样,这里的D使用的是auto-encoder结构,就是下面这种,D的输入是图片,输出是经过编码解码后的图片,
往的GAN以及其变种都是希望生成器生成的数据分布尽可能的接近真实数据的分布,当生成数据分布等同于真实数据分布时,我们就确定生成器G经过训练可以生成和真实数据分布相同的样本,即获得了生成足以以假乱真数据的能力,所以从这一点出发,研究者们设计了**各种损失函数去令G的生成数据分布尽可能接近真实数据分布。**BEGAN代替了这种估计概率分布方法,它不直接去估计生成分布Pg与真实分布Px的差距,进而设计合理的损失函数拉近他们之间的距离,而是估计分布的误差之间的距离,作者认为只要分布的的误差分布相近的话,也可以认为这些分布是相近的。即如果我们认为两个人非常相似,又发现这两人中的第二个人和第三个人很相似,那么我们就完全可以说第一个人和第三个人长的很像。
在BEGAN中,第一个人相当于训练的数据x,第二个人相当于D对x编码解码后的图像D(x),第三个人相当于D以G的生成为输入的结果D(g(z)),所以,如果||D(x)-x|| - || D(x)- D(g(z)) || 不断趋近于0,那么随着训练,D(x)会不断接近x,那么D(g(z)) 接近于D(x),岂不是就意味着 g(z) 的数据分布和x分布几乎一样了,那么就说明G学到了生成数据的能力。于是乎,假设图片足够大,像素很多。但是问题来了,如果||D(x)-x|| - || D(x)- D(g(z)) ||刚好等于0,这时候,D(x)和x可能还差的很远呢,那不就什么也学不到了D(x)-x是一个图片,假设图片上的每一个像素都满足独立同分布条件,根据中心极限定理,像素的误差近似满足正太分布,假设期望是m1,方差是μ1,同理D(x)- D(g(z)),还有m2, μ1这时候如果我们再用wassertein距离衡量m1与m2的距离,
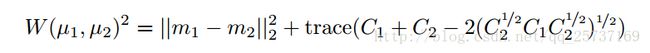
再满足下面这个条件下,
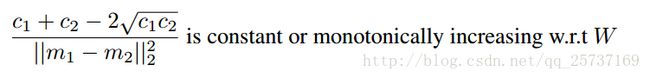
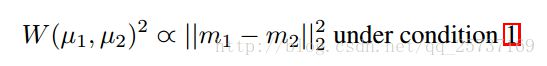
即他们成正比,这时候连lipschitz连续性条件也不需要了,
但是有一个问题,当m1和m2很接近是,条件1是趋于无穷的,不可能再忽略,于是,boundary(限制)就来了,
![]()

设置一个位于[0~1]之间的数λ,强制将m1和m2划分开界限,具体的损失函数如下:
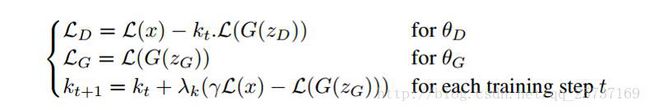
BEGAN的训练结果:不同的γ可以在图片的质量和生成多样性之间做选择。

所以说BEGAN效果还是很强的,当然先不考虑最新nvidia的渐进训练GAN,这篇之后会介绍。
这里直介绍了一些对GAN在训练和生成上改进的工作,具体还有很多很多很多很多没有介绍到,这里只是挑选了一些典型的,用的比较多的来介绍一下。感兴趣的可以去看看https://github.com/hindupuravinash/the-gan-zoo
GAN动物园,上百个GAN等着被翻牌。
8.GAN的基本代码
###################################a.起始情况
#是一个卷积神经网络,变量名是D,其中一层构造方式如下。
w = tf.get_variable('w', [4, 4, c_dim, num_filter],
initializer=tf.truncated_normal_initializer(stddev=stddev))
dconv = tf.nn.conv2d(ddata, w, strides=[1, 2, 2, 1], padding='SAME')
biases = tf.get_variable('biases', [num_filter],
initializer=tf.constant_initializer(0.0))
bias = tf.nn.bias_add(dconv, biases)
dconv1 = tf.maximum(bias, leak*bias)
...
#是一个逆卷积神经网络,变量名是G,其中一层构造方式如下。
w = tf.get_variable('w', [4, 4, num_filter, num_filter*2],
initializer=tf.random_normal_initializer(stddev=stddev))
deconv = tf.nn.conv2d_transpose(gconv2, w,
output_shape=[batch_size, s2, s2, num_filter],
strides=[1, 2, 2, 1])
biases = tf.get_variable('biases', [num_filter],
initializer=tf.constant_initializer(0.0))
bias = tf.nn.bias_add(deconv, biases)
deconv1 = tf.nn.relu(bias, name=scope.name)
...
#的网络输入为一个维服从-1~1均匀分布的随机变量,这里取的是100.
batch_z = np.random.uniform(-1, 1, [config.batch_size, self.z_dim])
.astype(np.float32)
#的网络输入是一个batch的64*64的图片,
#既可以是手写体数据也可以是的一个batch的输出。
#这个过程可以参考上图的a状态,判别曲线处于不够稳定的状态,
#两个网络都还没训练好。
############################b.训练判别网络
#判别网络的损失函数由两部分组成,一部分是真实数据判别为1的损失,一部分是的输出self.G#判别为0的损失,需要优化的损失函数定义如下。
self.G = self.generator(self.z)
self.D, self.D_logits = self.discriminator(self.images)
self.D_, self.D_logits_ = self.discriminator(self.G, reuse=True)
self.d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
self.D_logits, tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
self.D_logits_, tf.zeros_like(self.D_)))
self.d_loss = self.d_loss_real + self.d_loss_fake
#然后将一个batch的真实数据batch_images,和随机变量batch_z当做输入,执行session更新的参数。
##### update discriminator on real
d_optim = tf.train.AdamOptimizer(FLAGS.learning_rate,
beta1=FLAGS.beta1).minimize(d_loss, var_list=d_vars)
...
out1 = sess.run([d_optim], feed_dict={real_images: batch_images,
noise_images: batch_z})
#这一步可以对比图b,判别曲线渐渐趋于平稳。
#####################c.训练生成网络
#生成网络并没有一个独立的目标函数,它更新网络的梯度来源是判别网络对伪造图片求的梯度,
#并且是在设定伪造图片的label是1的情况下,保持判别网络不变,
#那么判别网络对伪造图片的梯度就是向着真实图片变化的方向。
self.g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
self.D_logits_, tf.ones_like(self.D_)))
#然后用同样的随机变量batch_z当做输入更新
g_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1)
.minimize(self.g_loss, var_list=self.g_vars)
...
out2 = sess.run([g_optim], feed_dict={noise_images:batch_z})
没什么不同
哪么重点来了,那么多GAN改进版,到底哪一个效果更好呢,最新的Google一项研究表明,GAN、WGAN、WGAN GP、LS GAN、DRAGAN、BEGAN啥的,都差不多,差不多,不多,为什么都差不多呢?因为天黑得时候他们都仰望同一片星空,忽然想起来了曲婉婷的一首歌—《没有什么不同》
Google研究原文请见:https://arxiv.org/abs/1711.10337
在此项研究中,Google此项研究中使用了minimax损失函数和用non-saturating损失函数的GAN,分别简称为MM GAN和NS GAN,对比了WGAN、WGAN GP、LS GAN、DRAGAN、BEGAN,除了DRAGAN上文都做了介绍,另外还对比的有VAE(变分自编码器)。
对比细节:
为了很好的说明问题,研究者们两个指标来对比了实验结果,分别是FID和精度(precision、)、召回率(recall)以及两者的平均数F1。
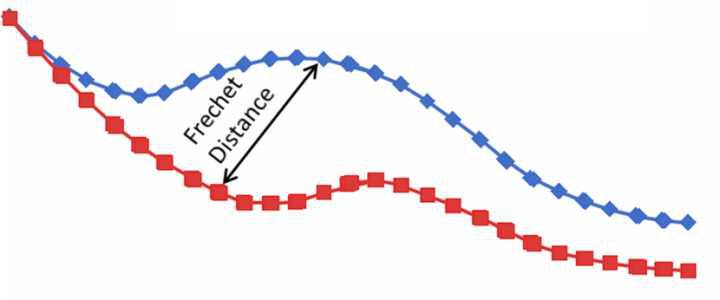
其中FID(Fréchet distance(弗雷歇距离) )是法国数学家Maurice René Fréchet在1906年提出的一种路径空间相似形描述,直观来说是狗绳距离:主人走路径A,狗走路径B,各自走完这两条路径过程中所需要的最短狗绳长度,如下图所示,所以说,FID与生成图像的质量呈负相关。
为了更容易说明对比的结果,研究者们自制了一个类似mnist的数据集,数据集中都是灰度图,图像中的目标是不同形状的三角形。
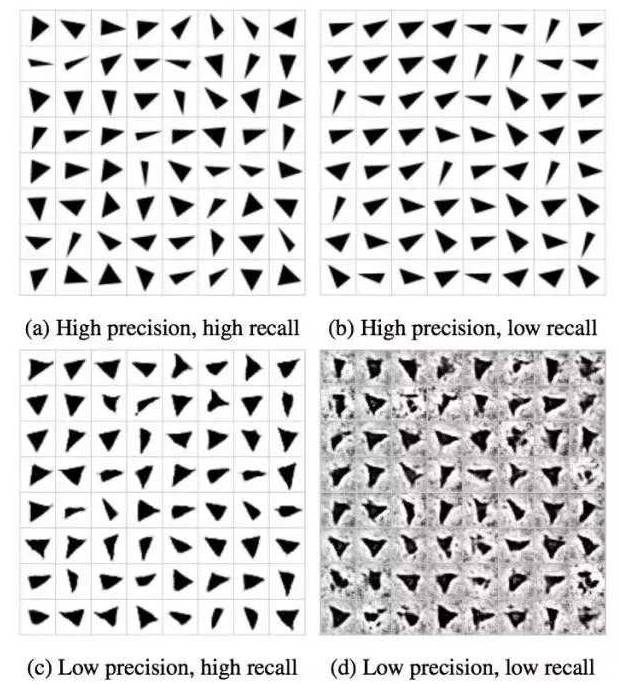
具体比较细节就不详细展开了,这里做一个结论总结
在图像生成方面,发现了VAE生成结果最差,其他的GAN等等生成质量都差不多,也很好理解其实,个人认为VAE更适合于对数据进行重构,对数据降维或者生成要求不是很高的数据上很方便(填补缺失数据),但是生成数据上还是GAN更胜一筹。
最后,研究者们也在精度(precision、)、召回率(recall)以及两者的平均数F1上做了测试,测试细节请看论文,也并没有发现其他GAN比原始GAN更突出的地方。
参考文献:
https://www.cnblogs.com/bonelee/p/9166122.html
https://blog.csdn.net/solomon1558/article/details/52555083