重磅开源!ICCV2019~华为诺亚方舟实验室提出无需数据网络压缩技术!
点上方蓝字计算机视觉联盟获取更多干货
在右上方 ··· 设为星标 ★,与你不见不散
编辑:Sophia计算机视觉联盟 报道 | 公众号 CVLianMeng
转载于 :华为诺亚方舟实验室
华为诺亚方舟实验室联合北京大学和悉尼大学发布论文《DAFL:Data-Free Learning of Student Networks》,提出了在无数据情况下的网络蒸馏方法(DAFL),比之前的最好算法在MNIST上提升了6个百分点,并且使用resnet18在CIFAR-10和100上分别达到了92%和74%的准确率(无需训练数据),该论文已被ICCV2019接收。
论文地址:https://arxiv.org/pdf/1904.01186
开源地址:https://github.com/huawei-noah/DAFL
研究背景
随着深度学习技术的发展,深度神经网络(CNN)已经被成功的应用于许多实际任务中(例如,图片分类、物体检测、语音识别等)。由于CNN需要巨大的计算资源,为了将它直接应用到手机、摄像头等小型移动设备上,许多神经网络的压缩和加速算法被提出。
虽然现有的神经网络压缩算法在大部分数据集上已经可以取得很好的压缩和加速效果,但是一个很重要的问题被忽略了:绝大多数的神经网络压缩算法都假设训练数据是可以获得的。然而,在现实生活应用中,数据集往往由于隐私、法律或传输限制等原因是不可获得的。例如,用户不想让自己的照片被泄露。因此,现有的方法在这些限制下无法被使用。有很少的工作关注在无数据情况下的网络压缩,然而,这些方法得到的压缩后的网络准确率下降很多,这是因为这些方法没有利用待压缩网络中的信息。为了解决这一问题,我们提出了一个新的无需训练数据的网络压缩方法,具体的,我们把给定的待压缩网络看作一个固定的判别器,接着,我们设计了一系列的损失函数来训练生成网络,使得生成图片可以代替训练数据集进行训练,最后,我们使用生成数据结合蒸馏算法得到压缩后的网络。实验表明,我们的算法在没有训练数据的情况下仍然可以达到和需要数据的压缩算法类似的准确率。
使用GAN生成训练数据
由于训练数据在实际中常常无法得到,在此情况下,神经网络的压缩变得十分困难,因此,本论文提出了利用生成网络生成与训练数据相似的样本,以便于神经网络的压缩。生成对抗网络(GAN)是一种可以生成数据的方法,包含生成网络与判别网络,生成网络希望输出和真实数据类似的图片,判别网络通过判别生成图片和真实图片帮助生成网络训练。然而,传统的GAN需要基于真实数据来训练判别器,这对于我们来说是无法进行的。
许多研究表明,训练好的判别器具有提取图像特征的能力,提取到的特征可以直接用于分类任务,所以,由于待压缩网络使用真实图片进行训练,也同样具有提取特征的能力,从而具有一定的分辨图像真假的能力。于是,我们把待压缩网络作为一个固定的判别器,以此来训练我们的生成网络。
然而,在传统GAN中,传统的判别器的输出是判定图片是否真假,只要让生成网络生成在判别器中分类为真的图片即可训练,但是,我们的待压缩网络为分类网络,其输出是分类结果,所以,我们需要重新设计生成网络的目标。通过观察真实图片在分类网络的响应,我们提出了以下损失函数。
在图像分类任务中,神经网络的训练采用的是交叉熵损失函数,在训练完成后,真实图片在网络中的输出将会是一个one-hot的向量,即分类类别对应的输出为1,其他的输出为0。于是,我们希望生成图片也具有类似的性质,我们的交叉熵损失函数定义为:
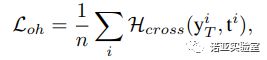 (1)
(1)
其中![]() 就是标准的交叉熵函数,由于生成图片并没有一个真实的标签,我们直接将其输出最大值对应的标签设定为它的伪标签。
就是标准的交叉熵函数,由于生成图片并没有一个真实的标签,我们直接将其输出最大值对应的标签设定为它的伪标签。
在神经网络的训练中,由卷积核提取的特征也是输入图片的一种重要表示。先前的许多工作表明,卷积核提取的特征包含着图片的许多重要信息,将训练数据输入训练好的深度网络中,卷积核会产生更大的响应(相比于噪声或与此网络无关的数据),基于此,我们提出了特征激活损失函数定义为![]() :
:
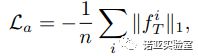 (2)
(2)
目标是让生成图像在待压缩网络中的特征响应值更大,这里我们采用了1范数来优化,原因是1范数相比于2范数会产生更加稀疏的值,而神经网络的响应也常常是稀疏的。
此外,为了让神经网络更好的训练,真实的训练数据对于每个类别的样本数目通常都保持一致,例如MNIST每个类别都含有6000张图片。于是,为了让生成网络产生各个类别样本的概率基本相同,我们引入信息熵,并定义了信息熵损失函数![]() :
:
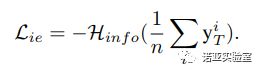 (3)
(3)
其中![]() 为标准的信息熵,信息熵的值越大,对于生成的一组样本来说,每个类别的数目就越平均,从而保证了生成样本的类别平均。
为标准的信息熵,信息熵的值越大,对于生成的一组样本来说,每个类别的数目就越平均,从而保证了生成样本的类别平均。
最后,我们将这三个损失函数组合起来,就可以得到我们生成器总的损失函数:
![]() (4)
(4)
通过优化以上的损失函数,训练得到的生成器可以和真实的样本在待压缩网络具有类似的响应,从而更接近真实样本。
蒸馏算法
除了训练样本的缺失,需要被压缩的神经网络常常是只提供了输入和输出的接口,网络的结构和参数都是未知的。另外,本发明提出的生成网络生成的训练样本是无标注的,基于这两点,我们引入了教师学生网络学习范式,利用蒸馏算法实现利用未标注生成样本对黑盒网络的压缩。
蒸馏算法最早由Hinton提出,待压缩网络(教师网络)为一个具有高准确率但参数很多的神经网络,初始化一个参数较少的学生网络,通过让学生网络的输出和教师网络相同,学生网络的准确率在教师的指导下得到提高。
于是,我们使用交叉熵损失来使得学生网络的输出符合教师网络的输出,具体的损失函数为:
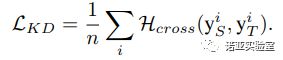 (5)
(5)
通过引入教师学生算法,我们解决了生成图片没有标签的问题,并且可以在待压缩网络结构未知的情况下对其进行压缩。
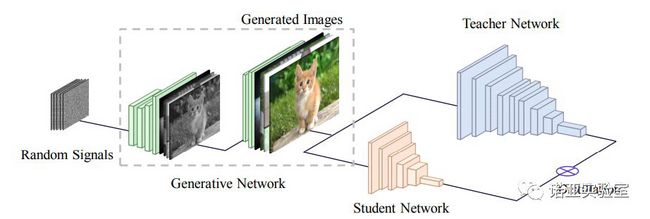
图1 Data-free Learning
算法1是本论文方法的流程。通过公式(5),我们可以训练一个生成器来生成和原始图片服从相似分布的数据。接着,我们使用生成数据,基于蒸馏算法训练学生网络,从而完成无数据情况下的网络压缩。

算法1:Data-free Learning
实验结果
我们在MNIST、CIFAR、CelebA三个数据集上分别进行了实验。
表1是在MNIST数据集上的结果,我们使用了LeNet-5和一个Hinton提出的具有3个全连接层的网络作为待压缩模型,将他们的通道数目减半分别作为学生模型。可以看到,使用原始数据集的蒸馏算法产生的学生模型具有和教师模型一样的准确率,但是参数量和FLOPs都大大减少。然而,在没有数据的情况下,蒸馏算法无法被使用,之前的一个使用元数据的方法只能达到92%的准确率,大大低于使用数据的算法。我们还使用了随机生成的正态分布、UPSP数据集作为训练数据进行训练,USPS数据集和MNIST数据集一样,都是手写数字分类数据集,然而,他们分别只取得了88%和94%的准确率。本论文提出的方法得到了98%的准确率,大大超越了之前的方法,并且比使用替代数据集得到的结果也要好很多,和使用原始数据得到的结果基本相似。
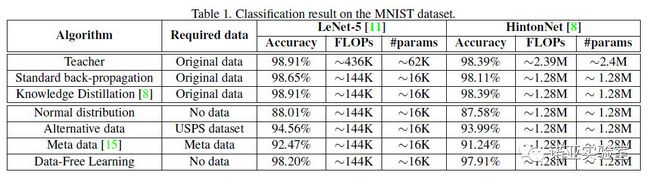
表1 MNIST数据集实验结果
我们还在CIFAR-10和100数据集上进行了实验,使用的教师和学生模型分别为Resnet-34和18。在CIFAR上,我们使用CIFAR-10的数据作为CIFAR-100的替代训练集,使用CIFAR-100的数据作为CIFAR-10的替代训练集,虽然CIFAR-10和100非常相似,并且具有一些重叠的图片,然而,得到的结果距离使用原始数据集仍然有较大的差距,证明了在实际情况中使用相似的数据集来替代原始数据集并不能取得很好效果。本论文提出的方法同样取得了和使用原始数据集的蒸馏算法相似的结果,并且超越了使用替代数据集的结果。
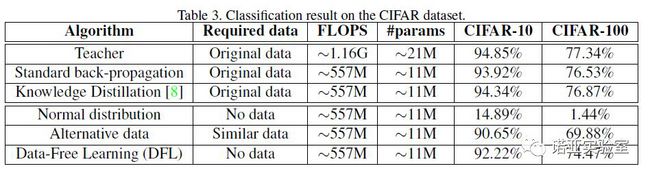
表2 CIFAR数据集实验结果
我们又在CelebA数据集上进行了实验,同样取得了很好的结果。

表3 CelebA数据集实验结果
由于我们的方法由很多损失函数组成,我们通过消融实验来分析每个损失函数项的必要性。表4是消融实验的结果,可以看到,本论文提出的损失函数的每一项都很重要。

表4 消融实验
最后,我们对教师和学生得到的卷积核做了可视化,可以发现,我们的方法学到的学生网络和教师网络具有非常相似的结构,证明了本论文方法的有效性。

图2 卷积核可视化
Great Breakthrough! Huawei Noah's Ark Labs first pioneers a novel knowledge distillation technique without training data.
Huawei Noah's Ark Lab publishes the paper "DAFL:Data-Free Learning of Student Networks", which first proposed the knowledge distillation method without data. The proposed DAFL is superior to the state-of-the art methods on MNIST by 6% accuracy, and achieves 92% and 74% accuracy on the CIFAR-10 and 100 datasets using resnet-18 with no training data.The paper has been accepted by ICCV2019.
Background
Deep convolutional neural networks (CNNs) have been successfully used in various computer vision applications such as image classification, object detection and semantic segmentation. However, launching most of the widely used CNNs requires heavy computation and storage, which can only be used on PCs with modern GPU cards. Inorder to compress and speed-up pre-trained heavy deep models, various effective approaches have been proposed recently.
Although the above mentioned methods have made tremendous efforts on benchmark datasets and models, an important issue has not been widely noticed, i.e. most existing network compression and speed-up algorithms have a strong assumption that training samples of the original network are available. However, the training dataset is routinely unknown in real-world applications due to privacy and transmission limitations. For instance, users do not want to let their photos leaked to others. Therefore, conventional methods cannot be directly used for learning portable deep models under these practice constrains.Nevertheless, only a few works have been proposed for compressing deep models without training data. The performance of compressed networks using these methods is much lower than that of the original network, due to they cannot effectively utilize the pre-trained neural networks. To address the aforementioned problem, we propose a novel framework for compressing deep neural networks without the original training dataset. To be specific, the given heavy neural network is regarded as a fixed discriminator. Then, a generative network is established for alternating the original training set by extracting information from the network during the adversarial procedure, which can be utlized for learning smaller networks with acceptable performance. The superiority of the proposed method is demonstrated through extensive experiments on benchmark datasets and models.
GAN for Generating TrainingSamples
In order to learn portable network without original data, we exploit GAN to generate training samples utilizing the available information of the given network. Generative adversarial networks (GANs) have been widely applied forgenerating samples. GANs consist of a generator G and a discriminator D. G is expected to generate desired data while D is trained to identify the differences between real images and those produced by the generator. Adversarial learning techniques can be naturally employed to synthesize training data. However, the discriminator requires real images for training. In the absence of training data, it is thus impossible to train the discriminator as vanilla GANs.
Recent works have proved that the discriminator can learn the hierarchy of representations from samples, which encourages the generalization of D in other tasks like image classification. Instead of training a new discriminator as vanilla GANs, the given deep neural network can extract semantic features from images as well, since it has already been well trained on large-scale datasets.Hence, we propose to regard this given deep neural network as a fixed discriminator. Therefore, G can be optimized directly without training D together.
The output of the discriminator is a probability indicating whether an input imageis real or fake in vanilla GANs. However, given the teacher deep neural networkas the discriminator, the output is to classify images to different concept sets, instead of indicating the reality of images. The loss function in vanilla GANs is therefore inapplicable for approximating the original training set. Thus, we conduct thorough analysis on real images and their responses on this teacher network. Several new loss functions will be devised to reflect our observations.
On the image classification task, the teacher deep neural network adopts the cross entropy loss in the training stage. Specifically for multi-class classification, the outputs are encouraged to be one-hot vectors, where only one entry is 1 and all the others are 0s. If images generated by $G$ follow the same distribution as that of the training data of the teacher network, they should also have similar outputs as the training data. We thus introduce the one-hot loss:
(1)
where ![]() is the cross-entropyloss function. Since the generated images have no true label, we suggest to usethe index of the max value of its output as the pseudo label.
is the cross-entropyloss function. Since the generated images have no true label, we suggest to usethe index of the max value of its output as the pseudo label.
Besides predicted class labels by DNNs, intermediate features extracted by convolution layers are also important representations of input images. Since filters in theteacher DNNs have been trained to extract intrinsic patterns in training data, feature maps tend to receive higher activation value if input images are realrather than some random vectors. Hence, we define an activation loss functionas:
(2)
Moreover, to ease the training procedure of a deep neural network, the number of training examples in each category is usually balanced, e.g. there are 6,000 images ineach class in the MNIST dataset. We employ the information entropy loss to measure the class balance of generated images:
(3)
where ![]() is the information entropy. When the loss takes the minimum, G could generate images of each category with roughly the same probability. T
is the information entropy. When the loss takes the minimum, G could generate images of each category with roughly the same probability. T
By combining the aforementioned three loss functions, we obtain the final objective function:
![]() (4)
(4)
By minimizing the above function, the optimal generator can synthesize images that have the similar distribution as that of the training data previously used fortraining the teacher network.
Teacher-StudentInteractions
As mentioned above, the generated images have no true label. In addition, parameters and detailed architecture information could also be unavailable sometimes. Thus, we propose to utilized the teacher-student learning paradigm for learning portable CNNs with unlabeled generated data.
Knowledge Distillation (KD) is a widely used approach to transfer the output information from a heavy network to a smaller network for achieving higher performance. The student network can be optimized using the following loss function based on knowledge distillation:
(5)
Therefore, utilizing the knowledge transfer technique, a portable network can be optimized without the specific architecture of the given network.
Figure 1: Data-free Learning
Detailed procedures of the proposed Data-Free Learning(DAFL) scheme for learning efficient student neural networks is summarized in Algorithm 1 and Figure 1. First, we regard the well-trained teacher network as a fixed discriminator. Using the loss function in Eq.(5), we optimize a generator to generate images that follow the similar distribution as that of the original training images for the teacher network. Second, we utilize the knowledge distillation approach to directly transfer knowledge from the teacher network to the student network.
Algorithm 1:Data-free Learning
ExperimentalResults
We first implement experiments on the MNIST dataset. Two architectures are used for investigating the performance of proposed method, \ie a convolution-based architecture and a network consists of fully-connect layers. The student networks have significantly fewer parameters than teacher networks. Table 1 reports the results of different methods on the MNIST datasets. Traditional methods achieve decent results, but they cannot be applied without training data. A previous method using meta-data achieves only a 92.47% accuracy. We then use a similar dataset (USPS) to train the student network and achieves only 94.56% accuracy. The proposed method utilizing generative adversarial networks achieved a 98.20% accuracy, which is much higher than the previous data-free methods.
We then conduct experiments on CIFAR-10 and CIFAR-100 datasets using ResNet-34 and ResNet-18 as teacher and student, respectively. we train the student network using the CIFAR-100 dataset, which has considerable overlaps with the original CIFAR-10 dataset, but this network only achieves a 90.65% accuracy, which is obviously lower than that of the teacher model. In contrast, the student network trained utilizing the proposed method achieved a 92.22% accuracy with only synthetic data.
The experiments on the CelebA dataset also provide similar results.
Table 2 reports the ablation study of the proposed method, which indicates that each term of the loss function is essential.
We visualize the convolutional filters of teacher and student in Figure 2, and find that they are similar, which demonstrate the effectiveness of the proposed method.
Figure 2: Visualization of filters
Paper URL: https://arxiv.org/pdf/1904.01186
Github URL:https://github.com/huawei-noah/DAFL
END
声明:本文来源于华为
如有侵权,联系删除
联盟学术交流群
扫码添加联盟小编,可与相关学者研究人员共同交流学习:目前开设有人工智能、机器学习、计算机视觉、自动驾驶(含SLAM)、Python、求职面经、综合交流群扫描添加CV联盟微信拉你进群,备注:CV联盟

最新热文荐读
重磅!GitHub:计算机视觉最全资料集锦(含实验室、算法及AI会议)
全网首发!2020年AI、CV、NLP顶会最全时间表!
Python必备收藏!博士大佬总结的Pycharm 常用快捷键思维导图!
如何看待 2020 届校招算法岗「爆炸」的情况?英雄所见略同
惊叹!阿里达摩院发布2019十大科技趋势!未来无限可期!
收藏!最全深度学习视觉目标检测技术综述!

点个在看支持一下吧