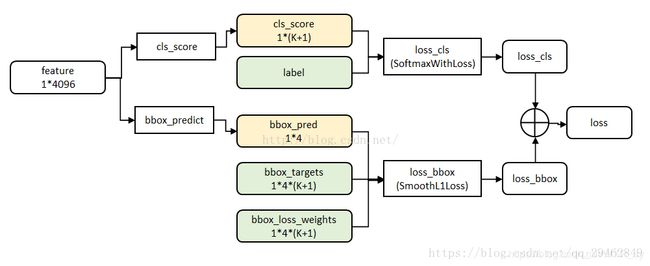
faster rcnn 原理解读
faster rcnn 原理解读
- 简介
- VGG and ResNet
- VGG
- ResNet
- RPN
- 训练RPN的标签分类
- ROI
简介
Faster R-CNN 第一步是采用基于分类任务(如,ImageNet)的 CNN 模型作为特征提取器. 听起来是比较简单的,重要的是理解其如何工作和为什么会有效,并可视化中间层,查看其输出形式.
网络结构很难说哪种是最好的. Faster R-CNN 最早是采用在 ImageNet 训练的 ZF 和 VGG,其后出现了很多其它权重不同的网络. 如,MobileNet 是一种小型效率高的网络结构,仅有 3.3M 参数;而,ResNet-152 的参数量达到了 60M. 新网络结构,如 DenseNet 在提高了结果的同时,降低了参数数量.
VGG and ResNet
VGG
由于 Faster R-CNN 是采用 VGG16 的中间卷积层的输出,因此,不用关心输入的尺寸. 而且,该模块仅利用了卷积层. 进一步去分析模块所使用的哪一层卷积层. Faster R-CNN 论文中没有指定所使用的卷积层,但在官方实现中是采用的卷积层 conv5/conv5_1 的输出.
每个卷积层利用前面网络信息来生成抽象描述. 第一层一般学习边缘edges信息,第二层学习边缘edges中的图案patterns,以学习更复杂的形状等信息. 最终,可以得到卷积特征图,其空间维度(分辨率)比原图小了很多,但更深. 特征图的 width 和 height 由于卷积层间的池化层而降低,而 depth 由于卷积层学习的 filters 数量而增加.
在 depth 上,卷积特征图对图片的所有信息进行了编码,同时保持相对于原始图片所编码“things”的位置. 例如,如果在图片的左上角存在一个红色正方形,而且卷积层有激活响应,那么该红色正方形的信息被卷积层编码后,仍在卷积特征图的左上角.
ResNet
ResNet 结构逐渐取代 VGG 作为基础网络,用于提取特征. Faster R-CNN 的共同作者也是 ResNet 网络结构论文 Deep Residual Learning for Image Recognition 的共同作者.
ResNet 相对于 VGG 的明显优势是,网络更大,因此具有更强的学习能力. 这对于分类任务是重要的,在目标检测中也应该如此.
另外,ResNet 采用残差连接(residual connection) 和 BN (batch normalization) 使得深度模型的训练比较容易. 这对于 VGG 首次提出的时候没有出现.
RPN
RPN的核心思想是使用CNN卷积神经网络直接产生Region Proposal,使用的方法本质上就是滑动窗口(只需在最后的卷积层上滑动一遍),因为anchor机制和边框回归可以得到多尺度多长宽比的Region Proposal。
RPN网络是在CNN上额外增加了2个卷积层(全卷积层cls和reg)。用来判断是否有目标和对box进行回归。
①将每个特征图的位置编码成一个特征向量(256dfor ZF and 512d for VGG)。
②对每一个位置输出一个objectness score和regressedbounds for k个region proposal,即在每个卷积映射位置输出这个位置上多种尺度(3种)和长宽比(3种)的k个(3*3=9)anchor的物体得分和回归边界。
RPN网络的输入可以是任意大小(但还是有最小分辨率要求的,例如VGG是228*228)的图片。如果用VGG16进行特征提取,那么RPN网络的组成形式可以表示为VGG16+RPN。
RPN的具体流程如下:使用一个小网络在最后卷积得到的特征图上进行滑动扫描,这个滑动网络每次与特征图上n*n(论文中n=3)的窗口全连接(图像的有效感受野很大,ZF是171像素,VGG是228像素),然后映射到一个低维向量(256d for ZF / 512d for VGG),最后将这个低维向量送入到两个全连接层,即bbox回归层(reg)和box分类层(cls)。sliding 窗口的处理方式保证reg-layer和cls-layer关联了conv5-3的全部特征空间。
reg层:预测proposal的anchor对应的proposal的(x,y,w,h)
cls层:判断该proposal是前景(object)还是背景(non-object)。
对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;窗口回归层从256维特征中输出4个平移缩放参数。
在下图中,33卷积核的中心点对应原图(re-scale,源代码设置re-scale为6001000)上的位置(点),将该点作为anchor的中心点,在原图中框出多尺度、多种长宽比的anchors。所以,anchor不在conv特征图上,而在原图上。对于一个大小为H*W的特征层,它上面每一个像素点对应9个anchor,这里有一个重要的参数feat_stride = 16, 它表示特征层上移动一个点,对应原图移动16个像素点(看一看网络中的stride就明白16的来历了)。把这9个anchor的坐标进行平移操作,获得在原图上的坐标。之后根据ground truth label和这些anchor之间的关系生成rpn_lables,具体的方法论文中有提到,根据overlap来计算,这里就不详细说明了,生成的rpn_labels中,positive的位置被置为1,negative的位置被置为0,其他的为-1。box_target通过_compute_targets()函数生成,这个函数实际上是寻找每一个anchor最匹配的ground truth box, 然后进行box坐标的转化。
reg层(bbox_pred)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数(x,y,w,h)。
cls层(cls_score)输出每一个位置上,9个anchor属于前景和背景的概率。
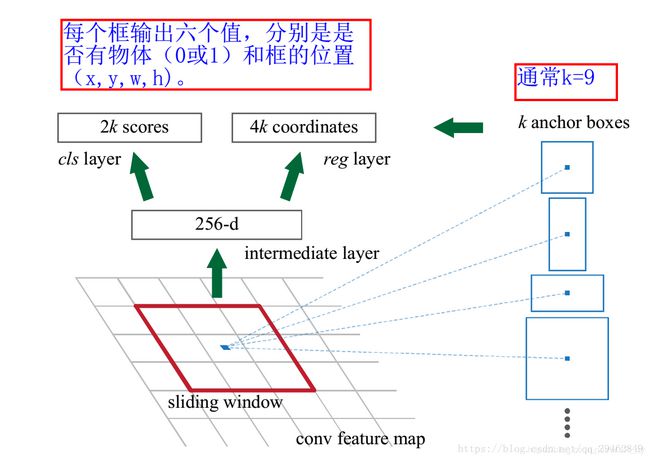
解释一下上面这张图的数字。
在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions
在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息(猜测这样做也许更鲁棒?反正我没测试),同时256-d不变(如图4和图7中的红框)
假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4k coordinates
补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练(什么是合适的anchors下文5.1有解释)
注意,使用的VGG conv5 num_output=512,所以是512d,其他类似。
训练RPN的标签分类
训练RPN时,需要给每个anchor分配的类标签{目标、非目标}。positive label(正标签)满足如下规定
1.与GT包围盒最高IoU重叠的anchor
2.与任意GT包围盒的IoU大于0.7的anchor
注意,一个GT包围盒可以对应多个anchor,这样一个GT包围盒就可以有多个正标签。
事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的anchor box与groud truth的IoU不大于0.7,可以采用第一种规则生成。
negative label(负标签):与所有GT包围盒的IoU都小于0.3的anchor。
对于既不是正标签也不是负标签的anchor,以及跨越图像边界的anchor我们给予舍弃,因为其对训练目标是没有任何作用的。