flink实战--窗口解析
本文主要介绍flink窗口的操作,相关窗口基础概念参考博客:https://blog.csdn.net/aA518189/article/details/82908993
flink windows类型
按照行为划分可分为三类:
- 翻滚窗口(Tumbling Window,无重叠)
- 滚动窗口(Sliding Window,有重叠)
- 会话窗口(Session Window,活动间隙)
按照控制流的方式分为两类:
窗口在处理数据前,会对数据做分流,有两种控制流的方式,按照数据流划分:Keyed和Non-Keyed Windows
Keyed Windows:就是有按照某个字段分组的数据流使用的窗口,可以理解为按照原始数据流中的某个key进行分类,拥有同一个key值的数据流将为进入同一个window,多个窗口并行的逻辑流。
stream
.keyBy(...) <- 是keyed类型数据集
.window(...) <- 指定窗口分配器类型
[.trigger(...)] <- 指定触发器类型(可选)
[.evictor(...)] <- 指定evictor或不指定(可选)
[.allowedLateness(...)] <- 指定是否延迟处理数据(可选)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/flod/apply() //指定窗口计算函数
.getSideOutput(...) //根据Tag输出数据(可选)
Non-Keyed Windows:没有进行按照某个字段分组的数据使用的窗口
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
注意:
- 方括号[]中的是可选项。窗口相关的函数使的flink允许你自有定义的
- allowedLateness只对事件时间窗口有效
Keyed和Non-Keyed Windows的区别
在定义窗口之前,要指定的第一件事是流是否需要Keyed,使用keyBy(...)将无界流分成逻辑的keyed stream。 如果未调用keyBy(...),则表示流不是keyed stream。
- 对于Keyed流:可以将传入事件的任何属性用作key。 拥有Keyed stream将允许窗口计算由多个任务并行执行,因为每个逻辑Keyed流可以独立于其余任务进行处理。 相同Key的所有元素将被发送到同一个任务。
- 对于Non-Keyed流:原始流将不会被分成多个逻辑流,并且所有窗口逻辑将由单个Task执行,即并行性为1。
窗口周期
只要属于此窗口的第一个元素到达,就会创建一个窗口,当时间(事件或处理时间)超过其结束时间戳加上用户指定的允许延迟时,窗口将被完全删除。 Flink保证仅删除基于时间的窗口而不是其他类型的窗口,例如全局窗口。使用基于事件时间的窗口策略,每5分钟创建一个不重叠(或翻滚)的窗口并允许延迟1分钟,当具有落入该间隔的时间戳的第一个元素到达时,Flink将为12:00到12:05之间的间隔创建一个新窗口,当水位线(watermark)到12:06时间戳时它将删除它。【这里同时我们也可以明白watermark的作用】。 每个窗口都有一个Trigger和函数(ProcessWindowFunction,ReduceFunction,AggregateFunction或FoldFunction)。该函数将包含要应用于窗口内容的计算,而触发器指定窗口被认为准备好应用该函数的条件。触发策略可能类似于“当窗口中的元素数量大于4”时,或“当水位线通过窗口结束时”。触发器还可以决定在创建和删除之间的任何时间清除窗口的内容。在这种情况下,清除仅涉及窗口中的元素,而不是窗口元数据。这意味着仍然可以将新数据添加到该窗口。
窗口开始的时间类型
对于目前大部分流处理系统来说,时间窗口一般是根据Task所在节点的本地时钟来进行切分,这种方式实现起来比较容易,不会阻塞消息处理。但是可能无法满足某些应用的要求,例如:
- 消息本身带有时间戳,用户希望按照消息本身的时间特性进行分段处理。
- 由于不同节点的时钟可能不同,以及消息在流经各个节点时延迟不同,在某个节点属于同一个时间窗口处理的消息,流到下一个节点时可能被切分到不同的时间窗口中,从而产生不符合预期的结果。
Flink支持三种类型的时间窗口,分别适用于用户对于时间窗口不同类型的要求:
- Operator Time。根据Task所在节点的本地时钟来进行切分的时间窗口。
- Event Time。消息自带时间戳,根据消息的时间戳进行处理,确保时间戳在同一个时间窗口的所有消息一定会被正确处理。由于消息可能是乱序流入Task的,所以Task需要缓存当前时间窗口消息处理的状态,直到确认属于该时间窗口的所有消息都被处理后,才可以释放其状态。如果乱序的消息延迟很高的话,会影响分布式系统的吞吐量和延迟。
- Ingress Time。有时消息本身并不带有时间戳信息,但用户依然希望按照消息而不是节点时钟划分时间窗口(例如,避免上面提到的第二个问题)。此时可以在消息源流入Flink流处理系统时,自动生成增量的时间戳赋予消息,之后处理的流程与Event Time相同。Ingress Time可以看成是Event Time的一个特例,由于其在消息源处时间戳一定是有序的,
- 所以在流处理系统中,相对于Event Time,其乱序的消息延迟不会很高,因此对Flink分布式系统的吞吐量和延迟的影响也会更小。
window和timeWindow
在keyed流中,对于时间窗口我们可以使用window和timeWindow,这两种方式有如下区别;
- window必须指定时间类型,也就是指定TumblingProcessingTimeWindows.of(Time.seconds(5))和TumblingEventTimeWindows.of(Time.seconds(5)).
- imeWindow使用时我们不需要指定时间类型,timeWindow的时间类型和env设置的时间类型一样,使用时直接使用:
timeWindow(Time.seconds(5))
注意点:
下面给大家强调一个任务运行时间的注意事项,尤其是利用flink处理离线数据时:
如果我们使用时间窗口,比如一分钟的时间窗口,那么我们可能直接认为此时flink任务的处理频率是一分钟计算一次数据,如果使用处理时间可以这么认为,但是如果使用事件时间,那么处理数据的时间间隔可能大于一分钟,也可能小于一分钟,实际处理数据的时间间隔是:数据的某个事件时间减去窗口开始的时间满足一分钟就会触发计算。
窗口分配器(Window Assigners)
指定是否Keyed流之后,下一步定义窗口分配器(window assigner),窗口分配器定义如何将元素分配给窗口。这是通过在window(...)(对于keyed streams)或windowAll()(对于non-keyed streams)调用中指定所选的WindowAssigner来完成的。WindowAssigner负责将每个传入元素分配给一个或多个窗口。 Flink带有预定义的窗口分配器,用于最常见的用例,即翻滚窗口,滑动窗口,会话窗口和全局窗口。还可以通过扩展WindowAssigner类来实现自定义窗口分配器。所有内置窗口分配器(全局窗口除外)都根据时间为窗口分配元素,这可以是处理时间或事件时间。基于时间的窗口具有开始时间戳(包括)和结束时间戳(不包括),它们一起描述窗口的大小。在代码中,Flink在使用基于时间的窗口时使用TimeWindow,该窗口具有查询开始和结束时间戳的方法,以及返回给定窗口的最大允许时间戳的方法maxTimestamp()。
触发器(Triggers)
触发器决定了一个窗口何时可以被窗口函数处理,每一个窗口分配器都有一个默认的触发器,如果默认的触发器不能满足需要,你可以通过调用trigger(...)来指定一个自定义的触发器,触发器的接口有5个方法来允许触发器处理不同的事件:
onElement()方法,每个元素被添加到窗口时调用
onEventTime()方法,当一个已注册的事件时间计时器启动时调用
onProcessingTime()方法,当一个已注册的处理时间计时器启动时调用
onMerge()方法,与状态性触发器相关,当使用会话窗口时,两个触发器对应的窗口合并时,合并两个触发器的状态。
clear()方法,执行任何需要清除的相应窗口
上面的方法中有两个需要注意的地方:
- 前三个通过返回一个TriggerResult来决定如何操作调用他们的事件,这些操作可以是下面操作中的一个:
CONTINUE:什么也不做
FIRE:触发计算
PURGE:清除窗口中的数据
FIRE_AND_PURGE:触发计算并清除窗口中的数据 - 这些函数可以注册 "处理时间定时器" 或者 "事件时间计时器",被用来为后续的操作使用
触发和清除(Fire and Purge)
一旦一个触发器决定一个窗口已经准备好进行处理,它将触发并返回FIRE或者FIRE_AND_PURGE。这是窗口操作==发送当前窗口结果的信号==,给定一个拥有一个ProcessWindowFunction的窗口,那么所有的元素都将发送到ProcessWindowFunction中(可能之后还会发送到驱逐器[Evitor]中)。ReduceFunction、AggregateFunction或者FoldFunction的窗口仅仅发送他们想要的聚合结果。当一个触发器触发时,它可以是FIRE或者FIRE_AND_PURGE,如果是FIRE,将保持window中的内容,如果是FIRE_AND_PURGE,会清除window的内容。默认情况下,预实现的触发器仅仅是FIRE,不会清除window的状态。清除操作仅清除window的内容,并留下潜在的窗口元信息和完整的触发器状态。
默认触发器(Default Triggers of WindowAssigners)
默认的触发器适用于许多种情况,例如:所有的事件时间分配器都有一个EventTimeTrigger作为默认的触发器,这个触发器仅在当水印通过窗口的最后时间时触发。GlobalWindow默认的触发器是NeverTrigger,是永远不会触发的,因此,在使用GlobalWindow时,需要定义一个自定义触发器。通过调用trigger(...)来指定一个触发器,你就重写了WindowAssigner的默认触发器。例如:如果你为TumblingEventTimeWindows指定了一个CountTrigger,就不会再通过时间来获取触发了,而是通过计数。现在,如果你想通过时间和计数来触发的话,你需要写自定义的触发器。
内置的和自定义的触发器(Build-in and Custom Triggers)
Flink有一些内置的触发器:
EventTimeTrigger,根据由水印衡量的事件时间的进度来的
ProcessingTimeTrigger,根据处理时间来触发
CountTrigger,一旦窗口中的元素个数超出了给定的限制就会触发
PurgingTrigger,作为另一个触发器的参数并将它转换成一个清除类型
如果想实现一个自定义的触发器,需要使用抽象类Trigger。这个API还在优化中,后续的Flink版本可能会改变。
注意:
我们在测试的时候尽量使用CountTrigge去触发窗口执行,如果使用默认的EventTimeTrigger,我们还需要设置具体的时间戳,不然可能测试时出现获取不到数据的假象,其实是窗口一直没触发。
使用案例:十条数据就触发一次窗口的执行
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.trigger(CountTrigger.of(10))
驱逐器(Evictors)
Flink的窗口模型允许指定一个除了WindowAssigner和Trigger之外的可选参数Evitor,这个可以通过调用evitor(...)方法来实现。这个驱逐器可以在触发器触发之前或者之后,或者窗口函数被应用之前清理窗口中的元素。为了达到这个目的,Evitor接口有两个方法:
void evictBefore(Iterable> elements, int size, W window, EvictorContext evictorContext);
void evictAfter(Iterable> elements, int size, W window, EvictorContext evictorContext);
evitorBefore()方法包含了在window function之前应用的驱逐逻辑,而evitorAfter()方法包含了在window function之后应用的驱逐逻辑。在window function应用之前被驱逐的元素将不会再被window function处理。
Flink有三个预实现的驱逐器:
- CountEvitor:在窗口中保持一个用户指定数量的元素,并在窗口的开始处丢弃剩余的其他元素
- DeltaEvitor:通过一个DeltaFunction和一个阈值,计算窗口缓存中最近的一个元素和剩余的所有元素的delta值,并清除delta值大于或者等于阈值的元素
- TimeEvitor:对于一个给定的窗口,使用一个毫秒级的interval作为参数,它会找出元素中的最大时间戳max_ts,并清除时间戳小于(max_ts - interval)的元素。
默认情况下,所有预实现的evitor都是在window function前应用它们的逻辑,指定一个Evitor要防止预聚合,因为窗口中的所有元素必须得在计算之前传递到驱逐器中,Flink 并不保证窗口中的元素是有序的,所以驱逐器可能从窗口的开始处清除,元素到达的先后不是那么必要。
允许延迟(Allowed Lateness)
当使用event-time的window时,可能会出现元素到达晚了,Flink用,来与事件时间联系的水印(watermark)已经过了元素所属的窗口的最后时间。默认情况下,当水印已经过了窗口的最后时间时,晚到的元素会被丢弃。然而,Flink允许为窗口操作指定一个最大允许时延,允许时延指定了元素可以晚到多长时间,默认情况下是0,也就是说水印之后到达的元素将被丢弃。
水印已经过了窗口最后时间后才来的元素,如果还未到窗口最后时间加时延时间,那么元素任然添加到窗口中。如果依赖触发器的使用的话,晚到但是未丢弃的元素可能会导致窗口再次被触发。
为了达到这个目的,Flink将保持窗口的状态直到允许时延的发生,一旦发生,Flink将清除Window,删除window的状态。
val input: DataStream[T] = ...
input
.keyBy()
.window()
.allowedLateness(
注意:当使用GlobalWindows分配器时,没有数据会被认为是延迟的,因为Global Window的最后时间是Long.MAX_VALUE。
以Side Output来获取延迟数据(Getting late data as a side output)
使用Flink的 Side Output 特性,你可以获得一个已经被丢弃的延迟数据流。首先你需要在窗口化的数据流中调用sideOutputLateData(OutputTag)指定你需要获取延迟数据。然后,你就可以在window操作的结果中获取到Side output了。
val lateOutputTag = OutputTag[T]("late-data")
val input: DataStream[T] = ...
val result = input
.keyBy()
.window()
.allowedLateness(
窗口函数
flink的窗口函数需要我们自己去实现,比如聚合,求品均值等操作,window函数可以是ReduceFunction、AggregateFunction、FoldFunction或ProcessWindowFunction中的一个。前面两个更高效一些,因为在++每个窗口中增量地对每一个到达的元素执行聚合操作++。一个ProcessWindowFunction可以获取一个窗口中的所有元素的迭代器(Iterable)以及元素所属窗口的额外元信息。有ProcessWindowFunction的窗口化操作会比其他的操作效率要差一些,因为Flink内部在调用函数之前会将窗口中的所有元素都缓存起来。这个可以通过ProcessWindowFunction和ReduceFunction、AggregateFunction、FoldFunction结合使用来获取窗口中所有元素的增量聚合和额外的窗口元数据
AggregateFunction
聚合函数是ReduceFunction的一种广义函数,具有三种类型:输入类型(in)、累加器类型(ACC)和输出类型(out)。输入类型是输入流中的元素类型,而聚合函数有一种将一个输入元素添加到累加器的方法。该接口还具有用于创建初始累加器的方法,用于将两个累加器合并为一个累加器,并从累加器中提取输出。
ACC createAccumulator();//创建一个数据统计的容器,提供给后续操作使用。
ACC add(IN in, ACC acc);//每个元素被添加进窗口的时候调用。第一个参数是添加进窗口的元素,第二个参数是统计的容器(上面创建的那个)。
OUT getResult(ACC acc);//窗口统计事件触发时调用来返回出统计的结果。
ACC merge(ACC acc1, ACC acc2);//只有在当窗口合并的时候调用,合并2个容器
注意:ACC可以换成你需要的类型,比如Long,Int等
下面这个AverageAggregate用来持续计算sum和count,getResult方法计算平均值
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
// 创建初始累加器
override def createAccumulator() = (0L, 0L)
// 将一个输入元素添加到累加器
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
// 输出结果
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
// 合并累加器
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
val input: DataStream[(String, Long)] = ...
input
.keyBy()
.window()
.aggregate(new AverageAggregate)
FoldFunction
1.6.0+已经过期
FoldFunction指定了一个输入元素如何与一个输出类型的元素合并的过程,这个FoldFunction会被每一个加入到窗口中的元素和当前的输出值增量地调用,第一个元素是与一个预定义的类型为输出类型的初始值合并。
ProcessWindowFunction
一个ProcessWindowFunction获得一个包含了window中的所有元素的迭代器(Iterable),和一个Context对象包含访问时间和状态信息,提供了更大的灵活性。这些带来了性能的成本和资源的消耗,因为window中的元素无法进行增量迭代,而是缓存起来直到window被认为是可以处理时。
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.timeWindow(Time.minutes(5))
.process(new MyProcessWindowFunction())
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]): () = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}
上面的例子展示了统计一个window中元素个数,此外,还将window的信息添加到输出中。使用ProcessWindowFunction来做简单的聚合操作,如:计数操作,性能是相当差的。将ReduceFunction跟ProcessWindowFunction结合起来,来获取增量聚合和添加到ProcessWindowFunction中的信息,性能更好。
案例一:求五秒钟内每个班级最高的分数
数据准备:时间戳,班级名,分数
2018-2-12 12:21:1,class1,123
2018-2-12 12:21:7,class1,14
2018-2-12 12:21:5,class2,7
2018-2-12 12:21:34,class3,3
2018-2-12 12:21:3,class3,15
2018-2-12 12:21:4,class2,1
案例代码:使用reduce算子计算最大值
public class WindowsTest {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource source1 = env.readTextFile("/Users/apple/Downloads/1.txt");
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
SingleOutputStreamOperator stream1 = source1.map(new MapFunction() {
@Override
public Row map(String value) throws Exception {
String[] split = value.split(",");
String timeStamp = split[0];
String name = split[1];
int score = Integer.parseInt(split[2]);
Row row = new Row(3);
row.setField(0,timeStamp);
row.setField(1,name);
row.setField(2,score);
return row;
}
}).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks() {
long currentMaxTimestamp = 0L;
long maxOutOfOrderness = 10000L;
Watermark watermark=null;
//最大允许的乱序时间是10s
@Nullable
@Override
public Watermark getCurrentWatermark() {
watermark = new Watermark(currentMaxTimestamp - maxOutOfOrderness);
return watermark;
}
@Override
public long extractTimestamp(Row element, long previousElementTimestamp) {
long timeStamp = 0;
try {
timeStamp = simpleDateFormat.parse(element.getField(0).toString()).getDate();
} catch (ParseException e) {
e.printStackTrace();
}
currentMaxTimestamp = Math.max(timeStamp, currentMaxTimestamp);
return timeStamp ;
}
}
);
stream1.keyBy(new KeySelector() {
@Override
public String getKey(Row value) throws Exception {
return value.getField(1).toString();
}
}).window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction() {
@Override
public Row reduce(Row value1, Row value2) throws Exception {
String s1 = value1.getField(2).toString();
String s2 = value2.getField(2).toString();
if(Integer.parseInt(s1)
运行结果:

案例二:窗口内分组聚合:计算10秒中内各个单词的总数
注意:本案例采用的是处理时间,如果对数据要求有序请采用时间时间,写法参考案例一
public class GruopWc {
public static void main(String[] args) throws Exception {
//获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//连接socket获取输入的数据
DataStreamSource text = env.socketTextStream("127.0.0.1", 3555);
//计算数据
DataStream windowCount = text.flatMap(new FlatMapFunction() {
public void flatMap(String value, Collector out) throws Exception {
String[] splits = value.split(",");
for (String word : splits) {
out.collect(new WordWithCount(word, 1L));
}
}
})//打平操作,把每行的单词转为类型的数据
//keyBy的时候可以指定多个ke进行分组
.keyBy("word")//针对相同的word数据进行分组
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))//指定计算数据的窗口大小和滑动窗口大小
.sum("count");
//把数据打印到控制台
windowCount.print().setParallelism(1);//使用一个并行度
//注意:因为flink是懒加载的,所以必须调用execute方法,上面的代码才会执行
env.execute("streaming word count");
}
/**
* 主要为了存储单词以及单词出现的次数
*/
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {
}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return "WordWithCount{" + "word='" + word + '\'' + ", count=" + count + '}';
}
}
}
验证:数据准备

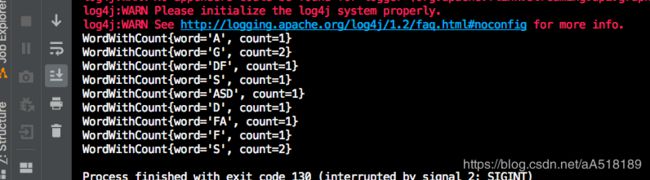
结果值:
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
