与其撩妹尬舞,倒不如跟AI学跳舞

作者 | Caroline Chan、Shiry Ginosar、Tinghui Zhou 和 Alexei A. Efros
译者 | linstancy
编辑 | Jane、琥珀
出品 | AI科技大本营
【AI科技大本营导读】“检测并定位图片中的人体,并进行人体属性分析”,人体姿态识别(Human Pose Detection)作为机器(计算机)视觉的一个重要分支,目前广泛应用于行为识别、人机交互、游戏、动画、零售等场景。作为该领域既有研究价值、又极富挑战性的热门课题,它吸引了全球各大科技公司和高校前来 PK,尤以 MS COCO 为代表的物体检测与人体关键点检测挑战赛受人瞩目。
早在一年前,基于卡内基梅隆大学感知计算实验室曹哲团队研究成果推出的开源项目 OnePose 就实现了一个实时多人姿态识别库,包括人体关键点、手部关键点、脸部关键点检测、姿态估计等。
可以想象,在电影、视频等场景中的任何人体姿态,如散步、舞蹈、手势,都可进行追踪。
此次,来自加州大学伯克利分校的 Caroline Chan、Shiry Ginosar、Tinghui Zhou 和 Alexei A. Efros 四位研究人员提出了一种不同视频中人体运动迁移的方法,以实现“Do As I Do",即给出任何一个人跳舞的源视频,算法就能够将该表演迁移到目标主体身上,以模仿出标准的舞蹈动作。即便你从未受过舞蹈训练,你也可以像芭蕾舞或 pop 舞者一样或优雅或活力地表演。
以下内容节选自该论文:
▌实现原理
与先前研究中采用最近邻搜索方法(nearest neighbor search) 或在3D 场景中重目标化运动不同的是,我们采用一种基于端到端的逐像素方法,在不需要昂贵的3D 或动作数据捕捉技术的情况下,我们的方法能够生成视频并在多视频目标之间实现运动的迁移。基于所提出的框架,我们能够合成各种各样的视频。

图1 两目标间的运动迁移
我们的主要贡献是提出了一种基于学习的视频间人体运动迁移的方法,并能在视频间实现复杂的运动迁移结果。此外,我们还进行了消融实验,研究模型的组成,并与基线框架方法进行比较。
其实我们的目标就是要实现源图像到目标图像的转换。具体地说,为了在两个视频之间实现逐帧的运动迁移,我们必须学习图像间两个人的逐帧映射。
实现目标的重要一步就是要完成基于关键点的姿势检测,其本质是对身体姿势进行编码,而不是对身体外观(外形不重要,动作的姿势图才是重要的),因此它可以作为任意两个人的中间表示,如图2所示,从目标视频中获得每帧所对应图像对的姿势检测。
随后,通过这些对齐的数据,我们以有监督的方式学习两人之间的图像转换模型。我们不是用两人在相同动作下所对应的图像对,因为即便是两个人都以相同的路线表演,但由于身体形状和目标各自独特的风格差异,我们也很难逐帧地得到身体姿态的相关性。
经过训练后,我们的模型能够为特定目标生成个性化的视频,进而在两人间实现运动的迁移。
为了进一步提高结果表现,我们添加了两个组分:为改善生成视频的时间平滑性,我们在每个前一时间步,对每帧预测施加一个条件;为了提高结果中合成面部的真实性,我们专门用一个GAN 模型来训练并生成目标人物的面部。

图2 姿势图和目标人物帧的相关性
▌主要方法
实现这项任务的方法主要分为三个阶段:姿势检测、全局姿态归一化、以及从标准化的姿势图到目标的映射。
-
首先,在姿势检测阶段,我们预训练当前最先进的姿势探测器,并基于给定的源视频帧数据,创建相应的姿势图。
-
接着,全局姿势标准化阶段用于处理每帧中源体和目标体在形状和位置之间的差异性。
-
最后,我们设计了一个系统,以对抗学习的方式来获取从标准的姿势图到目标人物图像的映射。
整个训练系统如图 3 所示,y 代表目标体视频中的帧,我们使用姿势检测器P 来获得相应的姿势图x = P (y)。在训练期间,我们使用相应的(x,y) 对进行学习基于姿态图x 的目标人物合成映射。使用预训练好的VGG 模型,通过对抗性判别器G 和一个感知重构误差dist,我们优化生成的输出G(x),以使其更接近真实的目标帧y。D试图区分真图像对(即(姿势图x,真实图像y)) 和假图像对(即(姿势图x,模型输出G(x))。
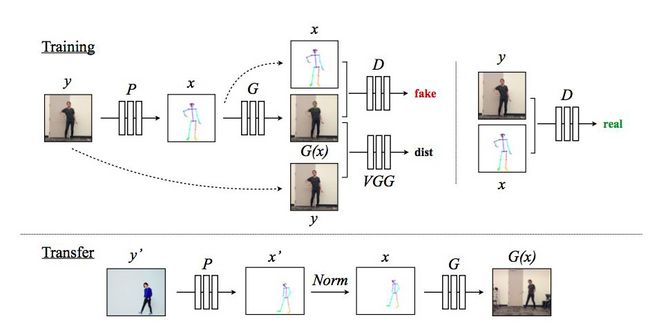
图3 (顶部) 训练过程:我们的模型使用姿势检测器P从目标对象的视频帧中创建姿势棒图。在训练期间,我们学习映射G和对抗判别器D,并试图区分真实图像对(x,y) 和假图像对((x),y);(底部) 迁移过程:我们使用姿势检测器P:Y'→X',通过标准化过程Norm 的转换,将源视频中的姿势转换为目标人物的姿势并创建相应的姿势棒图。随后,我们进一步地应用训练后的映射G。
同样,我们系统的运动迁移过程如上图3底部所示,与训练过程类似,姿势检测器P 从源视频帧y’ 中提取姿势信息以产生姿势棒图x’。然而,源视频中的目标可能看起来更大、或更小、或以不同的位置在目标视频中出现。为了将源视频的姿势与目标位置更好地对齐,我们采用全局姿势归一化Norm,来转换源视频的原始姿势x',以便使其与目标视频x 的姿势更加一致。然后,我们将标准化后的姿势棒图传递给我们训练的模型G,以获得目标人物的图像输出G(x),这个目标人物是源视频y’ 所对应的原始图像。
此外,我们的系统还包括姿态估计和标准化过程,对抗训练的图像翻译框架pix2pixHD 框架、时序平滑策略、专门的面部合成模型GAN 等。
▌实验过程
1. 实验数据
我们收集源视频和目标视频数据的方式略有不同。为了学习目标主体在不同姿势下的外观,我们要在足够广的范围捕获运动和清晰的目标视频帧数据,模糊程度要小。此外,为确保视频帧数据的质量,我们用手机相机,以每秒120帧的速度拍摄目标主体的实施镜头,时长约20分钟。由于我们不对衣服等相关信息进行编码,因此我们让目标者穿着褶皱较少的紧身衣服。
对于源视频,我们只需要得到合适的姿势检测结果,不需要保证源视频与目标视频有相同一致的质量。因此,抛开这些限制后,我们能够发现并获取许多高质量的网上表演舞蹈的视频。
此外,我们还发现,预平滑姿势关键点技术能够非常有效地减少输出的抖动。随着时间推移,我们对帧率较高的视频(120 fps) 中的关键点使用高斯平滑策略;而对较低帧率的视频,我们采用中值平滑策略。
2. 网络架构
不同的阶段,我们采用不同的模型。
为提取身体、脸部和手部等姿势关键点,我们使用最先进的姿势检测器OpenPose 架构。
图像转换阶段,我们采用pix2pixHD 模型。为了创建128x128 面部残差图,我们不需要使用整个pix2pixHD发生器,而只需要通过pix2pixHD的全局生成器来预测面部残差。
同样,我们对面部使用单个 70x70 Patch-GAN 判别器。在实际训练pix2pixHD 框架时,我们采用LSGAN 的目标函数来对整张图和面部GANs 模型进行训练。
3. 实验结果
我们在数据集上评估了实验结果,并与pix2pixHD 基线进行了对比,结果如下表1、表2、表3和表4。
3.1 Ablation Study
实际上ablation study就是为了研究模型中所提出的一些结构是否有效而设计的实验。比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study。(来源:知乎作者张晓)
我们在数据集上评估了实验结果,并与pix2pixHD 基线进行了对比,结果如下表1、表2、表3和表4。
表1展示了身体周围区域的平均图像相似性测量结果,图4展示了部分示例图像。可以看到,所有模型及其变体的SSIM 和LPIPS 分数都基本相似。pix2pixHD 基线已经能够合理地合成目标,我们的模型与其合成的结果不相上下,相似性测量指标也基本相似。
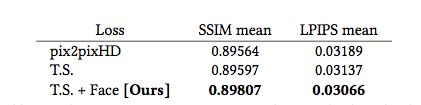
表1 身体周围区域的平均相似性结果
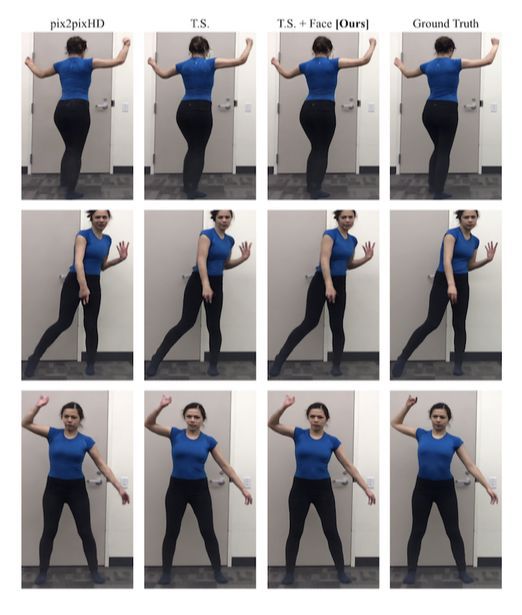
图4 不同模型的合成结果
表 2 展示了面部区域的平均得分结果。可以看到,我们的面部GAN模型在时序平滑设置下获得最佳的得分,且优于基线模型很多。
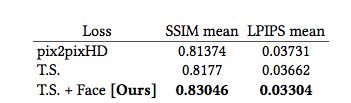
表2 面部区域的输出结果
表 3 展示了使用不同方法的平均姿势距离。我们对特定区域的关键点,如身体、面部、手等,进行姿势度量计算以确定哪些区域会导致最多的错误。可以看到,添加时间平滑设置似乎不会显著地减少重构的姿势距离,而对于面部和手部的关键点却有实质性的改进。
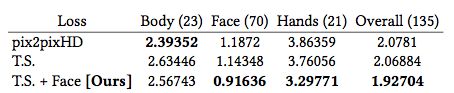
表3 不同方法得到的平均姿势距离
表4中,我们计算不同区域漏检的数量(即在真实视频帧中检测到的关节而不是输出中检测到的) 以及整个姿势作为姿势度量所导致的不准确而遗漏的检测数量。随着模型零件的添加,漏检的数量通常会减少,特别是对于面部关键点。

表4 每张图中的平均漏检数量,其值越小越好
3.2 定性评估结果
相比于pix2pixHD 基线模型表现,虽然消融实验结果表明时序平滑设置的引入通常有助于改进模型的表现,但在视频结果中却出现显著的差异,主要表现在时序平滑设置表现出更多帧到帧的一致性,这种设置将有助于平滑运动,跨帧的颜色一致性及各自帧的合成。
与消融研究结果一致的是,添加一个专门的面部生成器和判别器,将增加大量的面部细节并鼓励合成逼真的身体部位。进一步比较有无面部GAN 模型的合成结果,并在下图5展示视频结果。

图5 在验证集上不同模型的面部合成结果
▌总结
总的来说,我们的模型能够根据输入视频中舞者的身体动作,创造合理的、任意长度的目标人物动作。虽然在许多情况下,我们的模型能够产生合理的结果,但还存在一些问题:如我们输入的姿势图取决于嘈杂的姿势估计,而无法携带帧到帧的时序信息;再如姿势检测中会出现漏检或对关键点位置的不正确检测,一旦在输入中注入错误,这些错误经常会延续到我们最终的结果,即便是我们试图通过时序平滑设置来减轻这些限制。
此外,我们的结果还容易受到抖动的影响。要解决这些问题,需要在时序连贯一致性、视频生成和人体运动表示等方面开展更多工作,在未来的工作中我们将往这些方面努力,并希望能够生成各种引人注目的视频。
参考链接:https://arxiv.org/abs/1808.07371

--【完】--