利用modelarts和物体检测方式识别验证码
近来有朋友让老山帮忙识别验证码。在github上查看了下,目前开源社区中主要流行以下几种验证码识别方式:
- tesseract-ocr模块:
这是HP实验室开发由Google 维护的开源 OCR引擎,内置传统模式识别方法和现代深度神经网络算法 - 采用深度学习网络
通常是基于CNN网络,通过captcha等验证码生产器自动生产训练集,通常对生成器内置的验证码类型有极高的识别度。
需求中需要识别的验证码来自特定网站 http://fota.redstone.net.cn/,使用通用的验证码识别模块识别准确率比较低,因此很可能需要自己创建数据集进行训练。
查看数据
无论如何,都必须看到数据才能处理数据。因此我们通过对网站进行请求生成验证码集:
import os, requests
from time import sleep
# 文件保存路径
path = 'images'
# 验证码网站
url = 'http://fota.redstone.net.cn/index.php/home/index/get_verify.html'
# 图片数目
number = 100
os.makedirs(path, exist_ok=True)
# 请求并保存图片
for i in range(number):
sleep(0.1)
r = requests.get(url)
with open(f'{path}/{i}.jpg', 'wb') as f:
f.write(r.content)
观察数据:
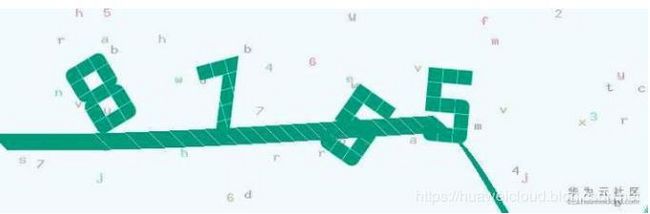

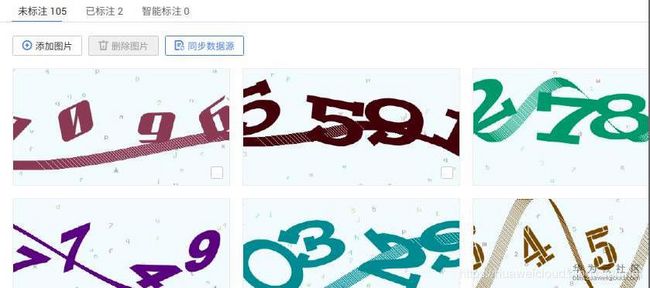
通过观察数据,发现这些验证码基本有这几个特点:
- 需要识别的是4个数字;
- 数字字体有多种风格,数字有一定旋转,数字之间有可能交叉;
- 背景中有许多小字;
- 与数字相同的颜色的间断粗线穿过数字,对数字识别造成影响。
标注
按通常的图像处理方式,可以通过形态学去除小字,然后转换成灰度图进行后期训练处理。但老山正好最近涉及些图像识别的深度学习方法,于是在想,是否能直接通过yolov3,faster-rcnn等物体检测模型来识别验证码呢?
要按物体检测方式识别验证码,首先要有标注数据集,这里采用modelarts内置的标注进行标注。
- 先将图像传到obs中
2. 在modelarts上点击创建数据集
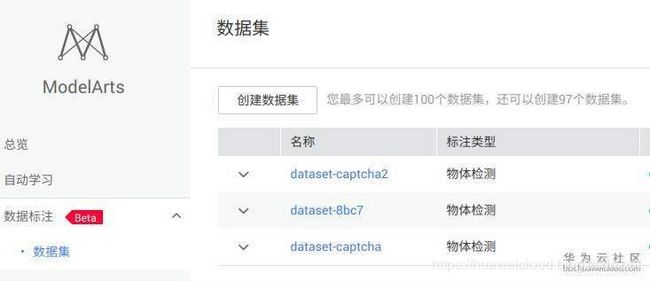
3. 按要求填写列表,选择物体检测,(标签可以在此处添加,也可以在标注的时候添加),然后创建数据集
4. 点击进入已创建的数据集,然后就可以进行图片标注了

5. 这里不得不提的是智能标注,这也成为后面老山深深的怨念;在标注图片超过20的时候,就可以启用智能标注,可以自动识别物体,减少标注时间

运行10多分钟后,标注就完成了,可以看到,标注的效果是真好

在已标注集仅为20的情况下,虽然还有不少需要更改的地方,但效果还是可用的;但标注集达到100时,效果就可以达到95%以上的准确率;由于智能标注使用的算法无非是常见的物体检测方法的一种,如此好的效果让我一度产生“标注数据集100就可以得到很好的训练效果“的幻觉。
训练
1. 标注完成后,点击数据集右侧的发布按钮,然后你在数据集输出路径里很深的路径里找到生成的标注的xml文件

2. 如果需要追加待标注数据集,可以对输入位置对应的obs路径中添加图像,然后在标注页面里点击”同步数据源“
3. 第一期标注了200张已标注图片,于是老山自信满满的打开训练作业,创建了faster-rcnn的训练作业
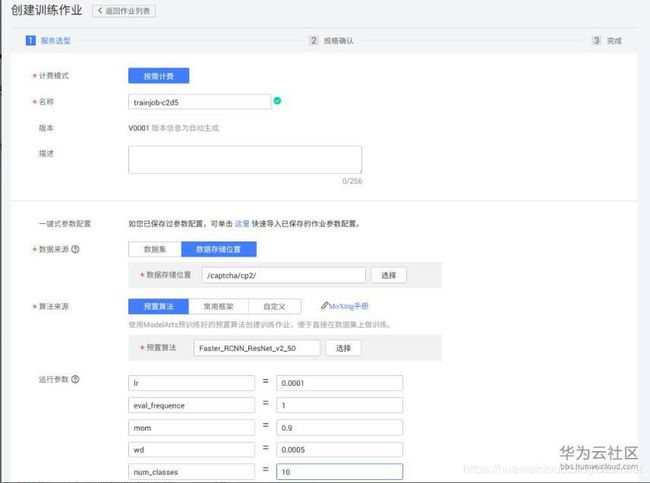
话说训练作业不用写代码还是很方便的,尤其适合前期尝试模型,让大家对模型能达到的准确率做个初步的判断,避免在一个不适合的模型中花费太多的时间。
在目前物体检测中,faster-rcnn、yolov3还有retinanet都是比较主流的模型。先尝试了faster-rcnn,mAP值只有0.2,然后是yolov3,mAP是0.29,用了retinanet,mAP值到了0.58。
老山于是便有了怨念,智能标注用啥模型啊,不还得是主流目标检测模型吗,为什么标注20张图就能有如此高的准确率,老山200张图训练的模型效果都不如他。尤其是前面faster-rcnn和yolov3的mAP值都如此的低,让老山一度很灰心,还好retinanet的效果还不错,可以继续调×教。
虽然老山调不出智能标注使用的模型,但模型复制嘛,不只是复制模型一种方法而已,把模型的结果集作为老山模型的训练集,只要数量足够大,也可以训练出相近的模型。于是就一口气又生成了800张图片,然后用已标注的200张图片做智能标注。由于标注结果十分准确,大部分标注结果就直接确认了,标注了800张图片,只花了1个多小时,效率可以说是杠杠的!
然后使用这1000个样本的数据集杀了回来,mAP值达到了0.96!看来数据集的大小非常重要,这还只是用了默认参数。
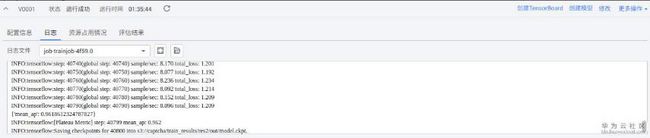
在观察日志的时候,发现右上角有个修改,点进去发现可以基于训练模型基础继续训练,同时发现预制算法旁边有个算法详情,里面描述了算法的运行参数。考虑到上次运行早停了,看了一通参数的含义,最后只改了decay_patience这个参数。
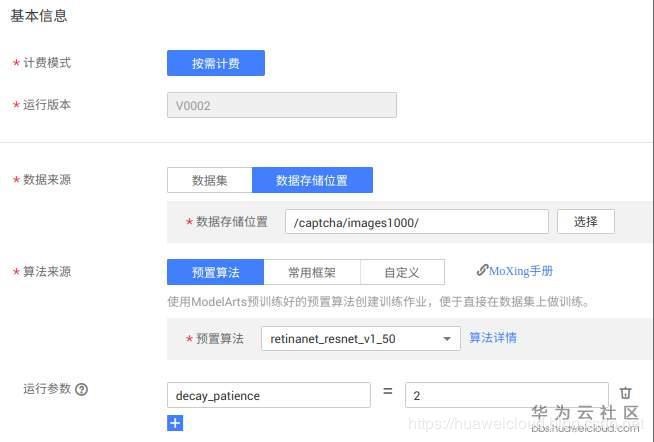
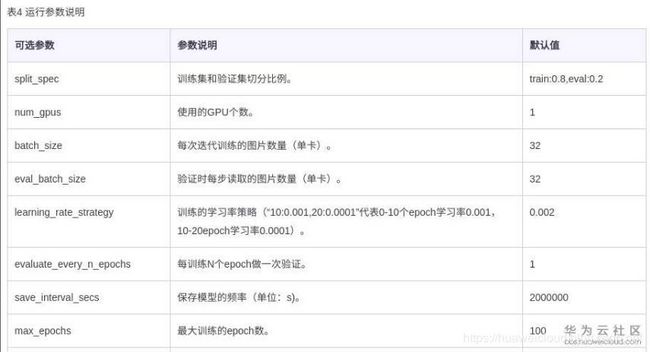
又跑了一遍,这次mAP又小小的提高到了0.97!但这些都只是个摸不着的结果,老山决定部署下看下结果
先在训练作业结果中点击创建模型,把名称改成有意义的,其他参数保持不变就好,
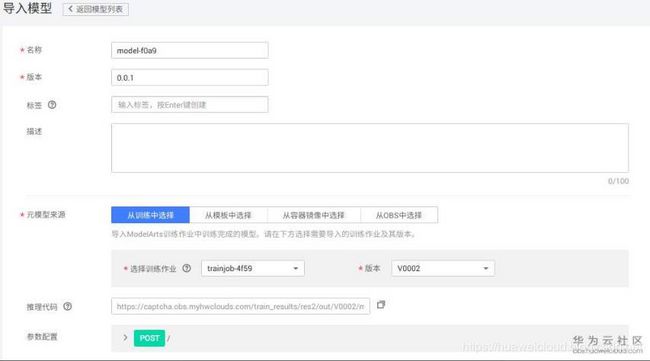
部署
等待模型状态正常后,点击右边的部署

等到部署完成后,点击部署任务中的预测,并上传图片,查看结果
许多结果看起来还可以
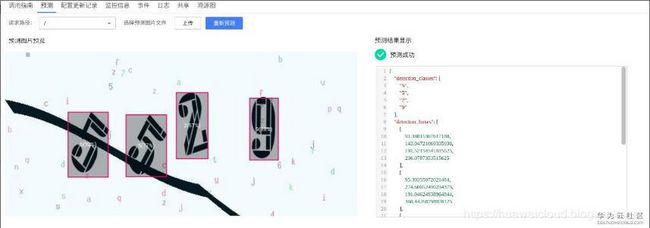
但也有不少结果没有预测正确
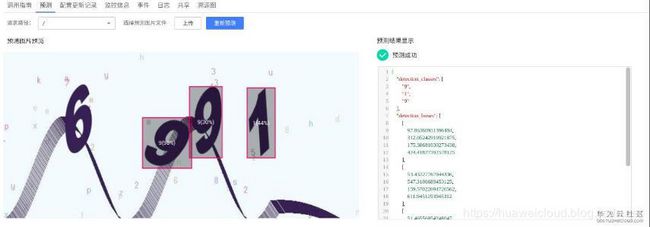
为此统计下这1000张图片的预测结果(老山这里比较懒,并没有单独准备测试集),我们需要对这些图片进行预测。由于不可能人工上传预测,为此老山祭出了大杀器,python。
首先,我们要获取X-Auth-Token认证
import requests
import json
url = "https://iam.cn-north-1.myhuaweicloud.com/v3/auth/tokens"
headers = {"Content-Type":"application/json"}
data = {
"auth": {
"identity": {
"methods": ["password"],
"password": {
"user": {
"name": "your-username",
"password": "your-password",
"domain": {
"name": "your-domainname:normally equal to your-username"
}
}
}
},
"scope": {
"project": {
"name": "cn-north-1"
}
}
}
}
data = json.dumps(data)
r = requests.post(url, data = data, headers = headers)
print(r.headers['X-Subject-Token'])
data具体参数填写可网址详见https://support.huaweicloud.com/api-modelarts/modelarts_03_0004.html
程序最后获得的便是X-Auth-Token认证码。
接下来我们开始预测
config.py
X_Auth_Token = "MIIZpAYJKoZIhvcNAQcCoIIZlTCC..." # 前面获取的X-Auth-Token值
url = "https://39ae62200d7f439eaae44c7cabccf5de.apigw.cn-north-1.huaweicloud.com/v1/infers/55d5..." #在调用指南页面获取的url值
predict.py
import os
import json
from lxml import etree as ET
import requests
from config import url, X_Auth_Token
import logging
logging.basicConfig(level=logging.INFO,
format="%(asctime)s %(name)s %(levelname)s %(message)s",
handlers = [
logging.FileHandler(f"log.txt"), #生成日志文件
logging.StreamHandler()
])
# 图片(jpg文件)和标注文件(xml文件)所在位置,注意jpg和xml文件一一对应
path = 'images1000'
def requestImage(filename):
'''根据图片文件利用在线服务预测结果, jsonStr'''
files = {'images':open(filename,'rb')}
headers2 = {'X-Auth-Token': X_Auth_Token}
response = requests.request("POST", url, files=files, headers=headers2)
return response.text
def getImageFile(xml_file):
'''根据xml文件返回对应的图片文件'''
return os.path.splitext(xml_file)[0]+'.jpg'
def getFileList(folder):
'''folder下的同名xml和jpg组成tuple,并以list返回 [(xml_file, jpeg_file), ...]'''
return [(os.path.join(folder, filename), os.path.join(folder, getImageFile(filename))) for filename in os.listdir(folder) iffilename.endswith('.xml')]
def json2text(jsonStr):
'''根据预测结果jsonStr返回预测的数字'''
obj = json.loads(jsonStr)
boxes = []
for className, box in zip(obj["detection_classes"], obj["detection_boxes"]):
boxes.append([className]+[float(pos) for pos in box])
# 注意预测的box以[top, left, bottom, right]进行排序,与xml文件有点不同
boxes.sort(key = lambda x: x[2])
return ''.join([className for className, *_ in boxes])
def xml2text(xml_file):
'''根据xml_file里所有box生成list [(class_name, left, top, right, bottom), ...]'''
tree = ET.parse(xml_file)
root = tree.getroot()
boxes = []
for obj in root.findall('object'):
name = obj.find('name').text
xmlbox = obj.find('bndbox')
b = (round(float(xmlbox.find('xmin').text)), round(float(xmlbox.find('ymin').text)),
round(float(xmlbox.find('xmax').text)), round(float(xmlbox.find('ymax').text)))
boxes.append((name, *b))
boxes.sort(key = lambda x: x[1])
return ''.join([className for className, *_ in boxes])
if __name__ == "__main__":
fileList = getFileList(path)
count = 0 # 预测数目
sameCount = 0 # 预测正确数目
for xml_file, jpg_file in fileList:
# 根据图片文件在线预测结果
jsonStr = requestImage(jpg_file)
text_image = json2text(jsonStr)
# 根据标注文件获得正确结果
text_xml = xml2text(xml_file)
# 对比输出
count += 1
if text_image==text_xml:
sameCount+=1
logging.info(f"count:{count}, sameCount:{sameCount}, \
text_image:{text_image}, text_xml:{text_xml}, percent:{sameCount/count}")
运行程序结果如下
可以看到,由于在线服务使用的是CPU,预测的结果比较慢,大概5~6秒出一个结果,准确率一直不高,最后定格在75.6%。对于这个结果,老山只能说,还好是用于预测验证码,可以反复预测,预测正确的期望次数是1.3次,算是可堪一用把。
总结
当然,本文算是使用modelarts对使用物体检测算法来识别验证码做了个试探,总体结果说明这种识别验证码的方法完全是可以用的,如果后续需要继续进展的话,完全可以在以下方面进行展开:
- 数据集生成:
数据集仍可以继续扩大。此时就不需要在手动标注了,老山想到一个很好的办法。生成数据集后,用智能标注的方式生成标注结果,将标注结果利用网站去验证正确与否,这样就可以无需手动,生成很好的数据集,现在智能标注免费,完全是白嫖,数据集够大时,至少能达到智能标注的水平(无限怨念)。 - 模型参数调节
预置模型很省心,但却看不到细节,如果想自己把握模型,可以使用开源模型来运行,老老实实的写代码调参数。如果没有GPU环境,可以使用开发环境的notebook进行开发;
3. 在本地开启服务
用在线服务功能当然省心,但如果只是为了识别验证码,这性价比就不是太高了。我们可以在预置模型的输出路径找到模型生成文件,这样就可以把模型布置在本地了。
作者:山找海味