机器学习实战笔记——利用SVD简化数据
SVD(Singular Value Decomposition)奇异值分解,可以用来简化数据,去除噪声,提高算法的结果。
一、SVD与推荐系统
下图由餐馆的菜和品菜师对这些菜的意见组成,品菜师可以采用1到5之间的任意一个整数来对菜评级,如果品菜师没有尝过某道菜,则评级为0
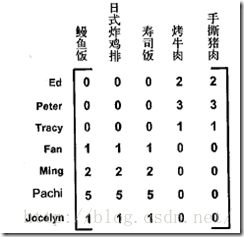
建立一个新文件svdRec.py并加入如下代码:
def loadExData():
return[[0, 0, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1],
[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 1, 0, 0]]>>> import svdRec
>>> Data=svdRec.loadExData()
>>> Data
[[0, 0, 0, 2, 2], [0, 0, 0, 3, 3], [0, 0, 0, 1, 1], [1, 1, 1, 0, 0], [2, 2, 2, 0, 0], [5, 5, 5, 0, 0], [1, 1, 1, 0, 0]]
>>> U,Sigma,VT=linalg.svd(Data)
>>> Sigma
array([ 9.64365076e+00, 5.29150262e+00, 8.05799147e-16,
2.43883353e-16, 2.07518106e-17])我们可以发现得到的特征值,前两个比其他的值大很多,所以可以将最后三个值去掉,因为他们的影响很小。
可以看出上图中前三个人,喜欢烤牛肉和手撕猪肉,这些菜都是美式烧烤餐馆才有的菜,这两个特征值可以分别对应到美食BBQ和日式食品两类食品上,所以可以认为这三个人属于一类用户,下面四个人属于一类用户,这样推荐就很简单了。
建立一个新文件svdRec.py并加入如下代码:
def loadExData():
return[[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[1, 1, 1, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1]]SVD分解:
>>> reload(svdRec)
>>> Data=svdRec.loadExData()
>>> Data
[[1, 1, 1, 0, 0], [2, 2, 2, 0, 0], [1, 1, 1, 0, 0], [5, 5, 5, 0, 0], [1, 1, 0, 2, 2], [0, 0, 0, 3, 3], [0, 0, 0, 1, 1]]
>>> U,Sigma,VT=linalg.svd(Data)
>>> Sigma
array([ 9.72140007e+00, 5.29397912e+00, 6.84226362e-01,
1.67441533e-15, 3.39639411e-16]) ![]()

![]()
上面例子就可以将原始数据用如下结果近似:![]()
二、基于协同过滤的推荐引擎
协同过滤(collaborative filtering)是通过将用户与其他用户的数据进行对比来实现推荐的。
1.相似度计算

from numpy import *
from numpy import linalg as la
def eulidSim(inA,inB):
return 1.0/(1.0+la.norm(inA,inB))
def pearsSim(inA,inB):
if len(inA<3):return 1.0
return 0.5+0.5*corrcoef(inA,inB,rowvar=0)[0][1]
def cosSim(inA,inB):
num=float(inA.T*inB)
denom=la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom)2.基于物品的相似度与基于用户的相似度
当用户数目很多时,采用基于物品的相似度计算方法更好。
3.示例:基于物品相似度的餐馆菜肴推荐引擎
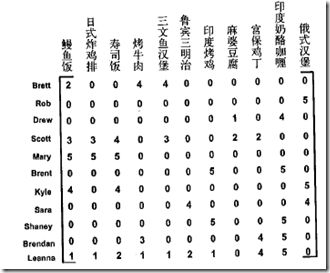
from numpy import *
from numpy import linalg as la
def loadExData():
return[[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[1, 1, 1, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1]]
def loadExData2():
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
def ecludSim(inA,inB):
return 1.0/(1.0 + la.norm(inA - inB))
def pearsSim(inA,inB):
if len(inA) < 3 : return 1.0
return 0.5+0.5*corrcoef(inA, inB, rowvar = 0)[0][1]
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom)
#计算在给定相似度计算方法的条件下,用户对物品的估计评分值
#standEst()函数中:参数dataMat表示数据矩阵,user表示用户编号,simMeas表示相似度计算方法,item表示物品编号
def standEst(dataMat,user,simMeas,item):
n=shape(dataMat)[1] #shape用于求矩阵的行列
simTotal=0.0; ratSimTotal=0.0
for j in range(n):
userRating=dataMat[user,j]
if userRating==0:continue #若某个物品评分值为0,表示用户未对物品评分,则跳过,继续遍历下一个物品
#寻找两个用户都评分的物品
overLap=nonzero(logical_and(dataMat[:,item].A>0,dataMat[:,j].A>0))[0]
if len(overLap)==0:similarity=0
else: similarity=simMeas(dataMat[overLap,item],dataMat[overLap,j])
#print'the %d and%d similarity is: %f' %(item,j,similarity)
simTotal+=similarity
ratSimTotal+=similarity*userRating
if simTotal==0: return 0
else: return ratSimTotal/simTotal
def recommend(dataMat,user,N=3,simMeas=cosSim,estMethod=standEst):
#寻找未评级的物品
unratedItems=nonzero(dataMat[user,:].A==0)[1]
if len(unratedItems)==0: return 'you rated everything'
itemScores=[]
for item in unratedItems:
estimatedScore=estMethod(dataMat,user,simMeas,item) #对每一个未评分物品,调用standEst()来产生该物品的预测得分
itemScores.append((item,estimatedScore)) #该物品的编号和估计得分值放入一个元素列表itemScores中
#对itemScores进行从大到小排序,返回前N个未评分物品
return sorted(itemScores,key=lambda jj:jj[1],reverse=True)[:N]
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat)
Sig4 = mat(eye(4)*Sigma[:4]) #arrange Sig4 into a diagonal matrix
xformedItems = dataMat.T * U[:,:4] * Sig4.I #create transformed items
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j==item: continue
similarity = simMeas(xformedItems[item,:].T,\
xformedItems[j,:].T)
print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal其中dataMat[:,item].A,表示找出item列,因为是matrix,用.A转成array,logical_and,其实就是找出最item列和j列都>0,只有都大于0才会是true,nonzero会给出其中不为0的index。
进行SVD分解:
>>>from numpy import linalg as la
>>> U,Sigma,VT=la.svd(mat(svdRec.loadExData2()))
>>> Sigma
array([ 1.38487021e+01, 1.15944583e+01, 1.10219767e+01,
5.31737732e+00, 4.55477815e+00, 2.69935136e+00,
1.53799905e+00, 6.46087828e-01, 4.45444850e-01,
9.86019201e-02, 9.96558169e-17])如何决定r?有个定量的方法是看多少个奇异值可以达到90%的能量,其实和PCA一样,由于奇异值其实是等于data×dataT特征值的平方根,所以总能量就是特征值的和
>>> Sig2=Sigma**2
>>> sum(Sig2)
541.99999999999932而取到前4个时,发现总能量大于90%,因此r=4
>>> sum(Sig2[:3])
500.50028912757909SVD分解的关键在于,降低了user的维度,从n变到了4
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat)
Sig4 = mat(eye(4)*Sigma[:4]) #arrange Sig4 into a diagonal matrix
xformedItems = dataMat.T * U[:,:4] * Sig4.I #create transformed items
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j==item: continue
similarity = simMeas(xformedItems[item,:].T,\
xformedItems[j,:].T)
print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal将m×n的dataMat用特征值缩放转换为n×4的item和user类的矩阵
>>> myMat=mat(svdRec.loadExData2())
>>> myMat
matrix([[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]])
>>> svdRec.recommend(myMat,1,estMethod=svdRec.svdEst)
the 0 and 3 similarity is: 0.490950
the 0 and 5 similarity is: 0.484274
the 0 and 10 similarity is: 0.512755
the 1 and 3 similarity is: 0.491294
the 1 and 5 similarity is: 0.481516
the 1 and 10 similarity is: 0.509709
the 2 and 3 similarity is: 0.491573
the 2 and 5 similarity is: 0.482346
the 2 and 10 similarity is: 0.510584
the 4 and 3 similarity is: 0.450495
the 4 and 5 similarity is: 0.506795
the 4 and 10 similarity is: 0.512896
the 6 and 3 similarity is: 0.743699
the 6 and 5 similarity is: 0.468366
the 6 and 10 similarity is: 0.439465
the 7 and 3 similarity is: 0.482175
the 7 and 5 similarity is: 0.494716
the 7 and 10 similarity is: 0.524970
the 8 and 3 similarity is: 0.491307
the 8 and 5 similarity is: 0.491228
the 8 and 10 similarity is: 0.520290
the 9 and 3 similarity is: 0.522379
the 9 and 5 similarity is: 0.496130
the 9 and 10 similarity is: 0.493617
[(4, 3.3447149384692283), (7, 3.3294020724526967), (9, 3.328100876390069)]