Spring cloud系列十四 分布式链路监控Spring Cloud Sleuth
1. 概述
Spring Cloud Sleuth实现对Spring cloud 分布式链路监控
本文介绍了和Sleuth相关的内容,主要内容如下:
- Spring Cloud Sleuth中的重要术语和意义:Span、Trance、Annotation
- Zipkin中图形化展示分布式链接监控数据并说明字段意义
- Spring Cloud集成Sleuth + Zipkin 的代码demo: Sleuth集成Zipkin, Zipkin数据持久化等
2. 术语
Span
Span是基本的工作单元。Span包括一个64位的唯一ID,一个64位trace码,描述信息,时间戳事件,key-value 注解(tags),span处理者的ID(通常为IP)。
最开始的初始Span称为根span,此span中span id和 trace id值相同。
Trance
包含一系列的span,它们组成了一个树型结构
Annotation
用于及时记录存在的事件。常用的Annotation如下
- cs - Client Sent:客户端发送一个请求,表示span的开始
- sr - Server Received:服务端接收请求并开始处理它。(sr-cs)等于网络的延迟
- ss - Server Sent:服务端处理请求完成,开始返回结束给服务端。(ss-sr)表示服务端处理请求的时间
- cr - Client Received:客户端完成接受返回结果,此时span结束。(cr-sr)表示客户端接收服务端数据的时间
如果一个服务的调用关系如下:
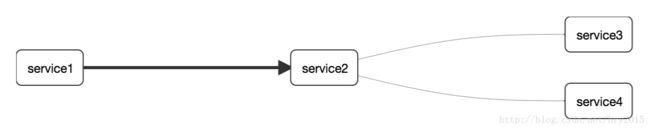
那么此时将Span和Trace在一个系统中使用Zipkin注解的过程图形化:
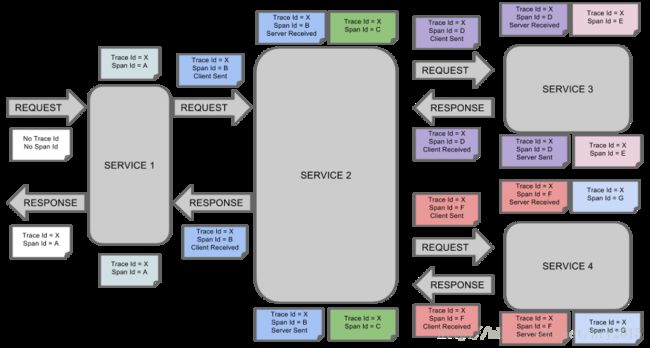
每个颜色的表明一个span(总计7个spans,从A到G),每个span有类似的信息
Trace Id = X
Span Id = D
Client Sent此span表示span的Trance Id是X,Span Id是D,同时它发送一个Client Sent事件
spans 的parent/child关系图形化如下:

3. 在Zipkin中图形化展示分布式链接监控数据
3.1 spans在zipkin界面的信息解读
在Zipkin中展示了上图的跟踪信息,红框里是对上图调用span的跟踪
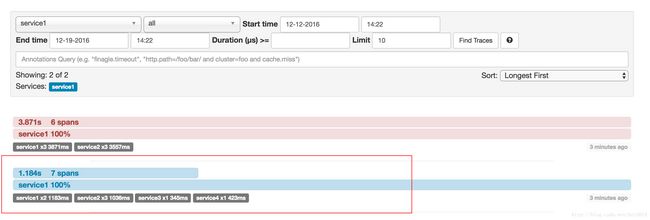
但是你点击这个trace时,我们只看到4个span

为什么两个界面显示的span数量不同,一个是7,一个4.
- 1 个 spans:来自servier1的接口http:/start 被调用,分别是Server Received (SR) 和 Server Sent (SS) annotations.
- 2 个 spans:来自 service1 调用service2 的 http:/foo 接口。service1 端有两个span,分别为 Client Sent (CS) 和 Client Received (CR) annotations。service2 端也有两个span,分别为Server Received (SR) 和Server Sent (SS) 。物理上他有2个span,但是从逻辑上说这个他们组成一个RPC调用的span。
- 2个span:来自 service2 调用 service3 的 http:/bar 接口,service2 端有两个span,分别为Client Sent (CS) 和 Client Received (CR) annotations。service3 端也有两个span,分别为Server Received (SR) 和Server Sent (SS) 。物理上他有2个span,但是从逻辑上说它们都是同一个RPC调用的span。
- 2个span:来自 service2 调用 service4 的 http:/bar 接口,service2 端有两个span,分别为Client Sent (CS) 和 Client Received (CR) annotations。service4 端也有两个span,分别为Server Received (SR) and Server Sent (SS) 。物理上他有2个span,但是从逻辑上说这个它们都是同一个RPC调用的span。
所以我们计算物理spans有7个:
- 1个来自 http:/start 被请求
- 2个来自 service1调用service2
- 2个来自 service2调用service3
- 2个来自 service2调用service4.
从逻辑上说,我们只看到4个span:
- 1个来自 service1 的接口http:/start 被请求
- 3个来自 服务之前的RCP接口调用
3.2. Zipkin可视化错误
如果调用链路中发生接口调用失败,zipkin会默认使用红色展示信息,如下图:
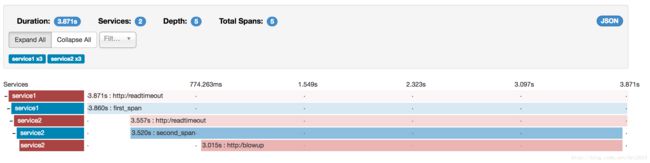
点击红色的span,可以看到详细的失败信息:

4. Spring Cloud集成Sleuth + Zipkin
本节演示在Spring Cloud中集成Sleuth并将链路监控数据传送到Zipkin,使用Zipkin展示数据,并配置mysql进行数据持久化
4.1. 相关工程
cloud-registration-center
注册中心
cloud-service-zipkin
提供测试服务接口,对外提供有两个接口:
- 调用成功后,马上返回一个结果: http://127.0.0.1:17602//zipkin/simple
- 调用成功后,服务sleep 5s后再返回: http://127.0.0.1:17602//zipkin/sleep
cloud-consumer-zipkin
消费服务
此服务会通过Feign调用cloud-service-zipkin里提供的两个接口(/zipkin/sleep和/zipkin/simple),我们访问如下URL会调用的对应的接口:
http://127.0.0.1:17603//zipkin/simple
http://127.0.0.1:17603//zipkin/sleep
以上3个服务的代码比较简单,这里代码略,可以自己看github里的代码。下文中只列出和Sleuth和Zipkin相关的配置。
cloud-dashboard-zipkin
配置Zipkin服务,提供可视化链路监控
Zipkin首页:http://127.0.0.1:17601/zipkin/
4.2. 在工程中使用sleuth+zipkin+http配置
在cloud-service-zipkin和cloud-consumer-zipkin中启动sleuth,sleuth会收集spans信息,并使用http异步地将spans 信息发送到Zipkin,然后Zipkin展示信息
cloud-service-zipkin和cloud-consumer-zipkin配置Sleuth+Zipkin
2个工程中为了集成Sleuth和Zipkin,需要在普通工程基础上增加如下配置:
- pom.xml增加sleuth和zipkin相关的jar
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>- application-zipkin.yml
Zipkin+Sleuth配置参数:
- spring.zipkin.baseUrl:指定cloud-dashboard-zipkin的服务地址,本例子中使用真实的IP。在新的版本spring-cloud-sleuth-core-1.3.0.RELEASE中,可以实现通过服务名称进行访问
- spring.sleuth.sampler.percentage:设置采样率,为了测试设置100%采集
spring:
zipkin:
enabled: true
# zipkkin dashboard的地址:通过真实IP地址访问
baseUrl: http://localhost:17601/
# 通过cloud-dashboard-zipkin注册到注册中心的服务名称访问,本版本(spring-cloud-sleuth-core-1.2.5.RELEASE)不支持,需要从spring-cloud-sleuth-core-1.3.0.RELEASE开始支持这个功能
# 配置如下:
# baseUrl: http://cloud-dashboard-zipkin/
sleuth:
sampler:
# 默认值为0.1f,现在为了测试设置100%采集
percentage: 1cloud-dashboard-zipkin
配置zipkin服务
- pom.xml
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-serverartifactId>
dependency>- 配置参数
bootstrap-zipkin-http.yml
# port
server:
port: 17601
spring:
application:
# 本服务注册到注册到服务器的名称, 这个名称就是后面调用服务时的服务标识符
name: cloud-dashboard-zipkin
eureka:
client:
serviceUrl:
# 服务器注册/获取服务器的zone
defaultZone: http://127.0.0.1:10761/eureka/
# defaultZone: http://192.168.21.3:10761/eureka/,http://192.168.21.4:10761/eureka/
instance:
prefer-ip-address: true- application-zipkin-http.yml
关闭本工程的推送到zipkin服务的功能
spring:
zipkin:
enabled: false启动类:
@EnableZipkinServer:注解此类为Zipkin服务
@EnableEurekaClient // 配置本应用将使用服务注册和服务发现
@SpringBootApplication
@EnableZipkinServer // 启动Zipkin服务
public class ZipkinDashboardCloudApplication {
public static void main(String[] args) {
args = new String[1];
args[0] = "--spring.profiles.active=zipkin-http";
SpringApplication.run(ZipkinDashboardCloudApplication.class, args);
}4.3. 测试
启动zipkin服务,提供可视化链路监控
Zipkin访问地址: http://127.0.0.1:17601/zipkin/
我们演示链路跟踪,访问以下两个请求:
http://127.0.0.1:17603/zipkin/simple :正常方法
http://127.0.0.1:17603/zipkin/sleep :访问超时
进入zipkin,访问成功为蓝色,失败为红部。同时显示各个服务花费的时间

点击蓝色记录,进入详细界面
可知整个接口花费约19ms,cloud-zipkin-service的业务执行15ms,cloud-zipkin-consumer访问cloud-zipkin-service的 网络延迟为2ms,返回结果给cloud-zipkin-service的网络延迟是4s

点击cloud-zipkin-service得到更精确的数据

4.4. Zipkin数据持久化
默认情况,zipkin存储记录到内存,如果服务重启,则所有记录丢失。为了保证持久性,zipkin支持Mysql、Elasticsearch、Cassandra存储。我们演示为zipkin配置MYSQL数据库,其它两种配置类似,本文略
pom.xml为cloud-dashboard-zipkin引入新jar
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-storage-mysqlartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>6.0.6version>
dependency>
配置参数:
application-zipkin-http.yml:
配置启动时会根据classpath:/mysql.sql初始化数据库
spring:
zipkin:
enabled: false
# 配置mysql
datasource:
schema: classpath:/mysql.sql
# url: jdbc:mysql://127.0.0.1/test
url: jdbc:mysql://127.0.0.1:3306/test?zeroDateTimeBehavior=convertToNull&serverTimezone=GMT%2b8
username: root
password: root
# Switch this on to create the schema on startup:
initialize: true
continueOnError: true
sleuth:
enabled: false
zipkin:
storage:
type: mysql重启服务,服务成功后,查看数据库,自动生成数据库
如此数据库配置完毕,所有的spans信息存储到数据库中,重启服务,也不会丢失记录
4.5 在工程中使用sleuth+zipkin+ Spring Cloud Stream配置
本版本(spring-cloud-sleuth-core-1.2.5.RELEASE)支持集成spring-cloud-sleuth-stream,但是在新版本从spring-cloud-sleuth-core-1.3.0.RELEASE开始不支持spring-cloud-sleuth-stream。推荐直接使用通过集成RabbitMQ 或 Kafka。关于集成RabbitMQ 或 Kafka,关键是引入spring-rabbit 或 spring-kafka依赖包。默认的目的名称为zipkin.
对于这个的使用demo。这里暂时略
5. 代码
以上的详细的代码见下面
github代码,请尽量使用tag v0.11,不要使用master,因为我不能保证master代码一直不变