python-爬虫-xpath(词云)
一>.使用csv保存文件
1>.写入csv文件
import csv
with open('list.csv','w') as f:
writ=csv.writer(f)
writ.writerows([['1','2','3'],['4','5','6']])
print("文件写入成功")
2>.读取csv文件
import csv
with open('list.csv') as f:
read=csv.reader(f)
for row in read:
print(row)

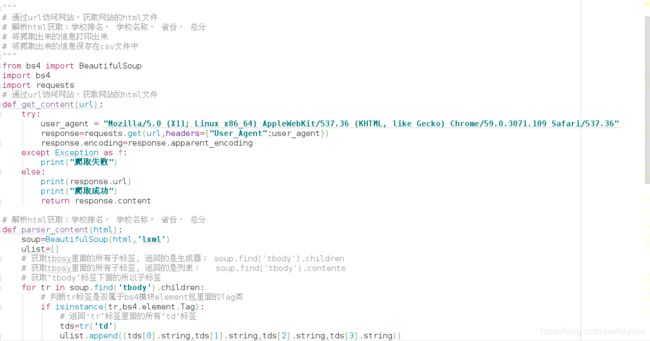
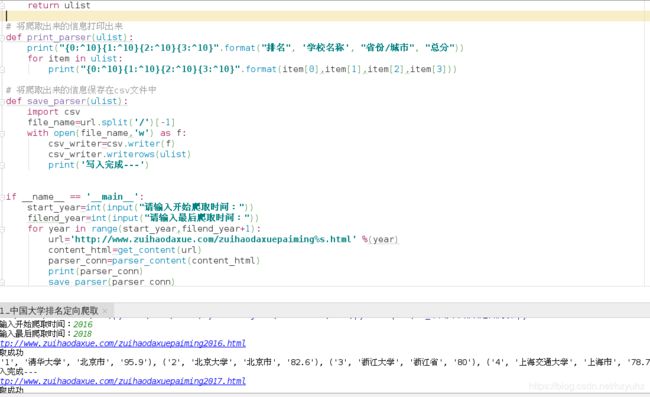
二>.使用bs4爬取中国最好大学排名:(学校排名, 学校名称, 省份, 总分)
三>.xpath的简单使用


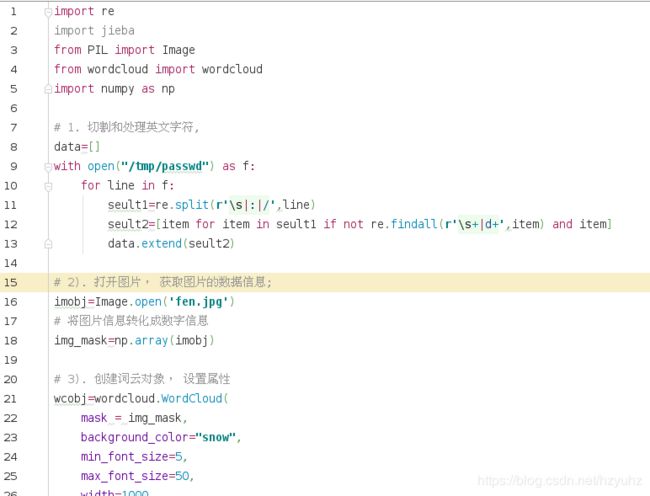
四>.使用词云分析英语单词,绘制图片


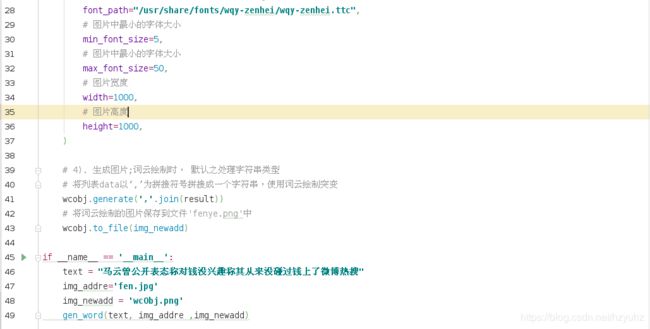
五>.使用词云分析中文,绘制图片

六>.使用xpath爬取慕课网课程信息,并且生存词云图片
import requests
import lxml.etree as etree
import jieba
from PIL import Image
from wordcloud import wordcloud
import numpy as np
def get_content(url):
try:
user_agent='Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0'
respons=requests.get(url,headers={'User-Agent':user_agent})
respons.raise_for_status()
respons.encoding=respons.apparent_encoding
except Exception as e:
print('爬取错误')
else:
print(respons.url)
print("爬取成功")
return respons.content
def parser_content(html):
courseinfos=[]
# 将文件转化成xpath可以识别的格式
selector=etree.HTML(html)
# 获取每个课程的信息
coursedetails=selector.xpath('//div[@class="course-card-container"]')
for coursedetail in coursedetails:
# 课程名称
name=coursedetail.xpath(".//h3[@class='course-card-name']/text()")[0]
# 学习人数
studentnum=coursedetail.xpath(".//span/text()")[1]
# 课程描述
courseinfo=coursedetail.xpath(".//p[@class='course-card-desc']/text()")[0]
# 课程链接
courseurl="https://www.imooc.com"+coursedetail.xpath('.//a/@href')[0]
# 课程的图片url
courseimg="https:"+coursedetail.xpath(".//img/@src")[0]
#
courseinfos.append((name,studentnum,courseinfo,courseurl,courseimg))
# print(name,studentnum,courseinfo,courseurl,courseimg)
return courseinfos
def sace_csv(courseinfos):
import csv
with open("mooc.csv",'w') as f:
writer=csv.writer(f)
writer.writerows(courseinfos)
print("csv文件保存成功-----")
def save_json(courseinfos):
import json
with open("moon.json",'w',encoding='utf-8') as f:
for item in courseinfos:
item={
"name":item[0],
"studentnum":item[1],
"courseinfo":item[2],
"courseurl":item[3],
"courseimg":item[4]
}
jsonitem=json.dumps(item,ensure_ascii=False,indent=4)
f.write(jsonitem + "\n")
print("json文件ok----")
def moocspider():
url="https://www.imooc.com/course/list"
html=get_content(url)
courseinfos=parser_content(html)
print(courseinfos)
while True:
selector=etree.HTML(html)
nextpage=selector.xpath('//a[contains(text(),"下一页")]/@href')
print(nextpage)
if nextpage and ('3' not in nextpage[0]):
url="https://www.imooc.com"+nextpage[0]
print(url)
html=get_content(url)
othercourseinfo=parser_content(html)
courseinfos+=othercourseinfo
else:
print("爬取结束")
break
save_json(courseinfos)
sace_csv(courseinfos)
def anlysecourse(filename):
import csv
import re
# 定义一个空字符串,用来将后面出现的字符串拼接成一个字符串
wordcloudstring=""
with open(filename) as f:
reader=csv.reader(f)
# 清洗需要分析的文本信息,删除里面不必要的逗号,句号,表情等
patten=re.compile(r'([\u4e00-\u9fa5]+|[a-zA-Z0-9]+)')
for item in reader:
# 将来进行词云展示时,需要的是字符串,而不是列表
name="".join(re.findall(patten,item[0]))
detail="".join(re.findall(patten,item[2]))
wordcloudstring+=name
wordcloudstring+=detail
# 将wordcloudstring字符串里面的(学习|使用|入门|基础|实现|掌握)利用正则re替换成“”
wordstring=re.sub(r'(学习|使用|入门|基础|实现|掌握)','',wordcloudstring)
return wordstring
# print(wordstring)
def gen_word(text,img_addre ,img_newadd):
# 1.强调分割有问题的词
jieba.suggest_freq(("热搜"),True)
jieba.suggest_freq(("微博"),True)
# 2.如何切割中文
result=jieba.lcut(text)
# 3). 打开图片, 获取图片的数据信息;
imobj=Image.open(img_addre)
# 将图片信息转化成数字信息
img_mask=np.array(imobj)
# 3). 创建词云对象, 设置属性
wcobj=wordcloud.WordCloud(
# 数据填充到图片
mask = img_mask,
# 背景颜色
background_color="snow",
# 如果是中文, 指定字体库(fc-list :lang=zh)
font_path="/usr/share/fonts/wqy-zenhei/wqy-zenhei.ttc",
# 图片中最小的字体大小
min_font_size=5,
# 图片中最小的字体大小
max_font_size=50,
# 图片宽度
width=1000,
# 图片高度
height=1000,
)
# 4). 生成图片;词云绘制时, 默认之处理字符串类型
# 将列表data以‘,’为拼接符号拼接成一个字符串,使用词云绘制突变
wcobj.generate(','.join(result))
# 将词云绘制的图片保存到文件'fenye.png'中
wcobj.to_file(img_newadd)
if __name__ == '__main__':
text = anlysecourse('mooc.csv')
img_addre='fy.jpg'
img_newadd = 'wcObj.png'
gen_word(text, img_addre ,img_newadd)
