JAVA的并发编程(一): 线程和锁
目录
一、创建线程
继承Thread类,重写run方法
Synchronized锁类型示例:
Synchronized的四种用法
线程中的脏读
引申:数据库的ACID
一、创建线程
继承Thread类,重写run方法
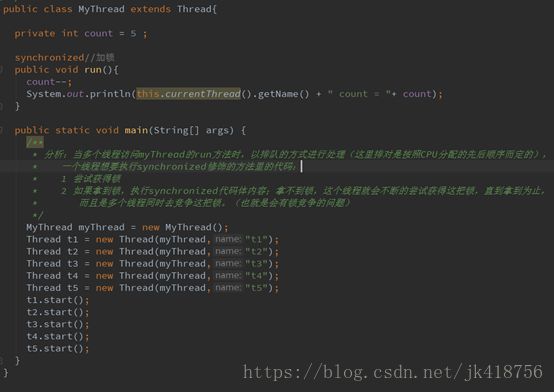
Thread的线程默认是不安全的,多个线程进行抢占式执行,出现结果如下
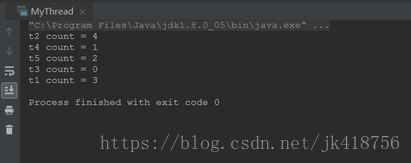
想要实现安全的线程,可以给run添加synchronized修饰,进行线程同步
Synchronized锁类型示例:
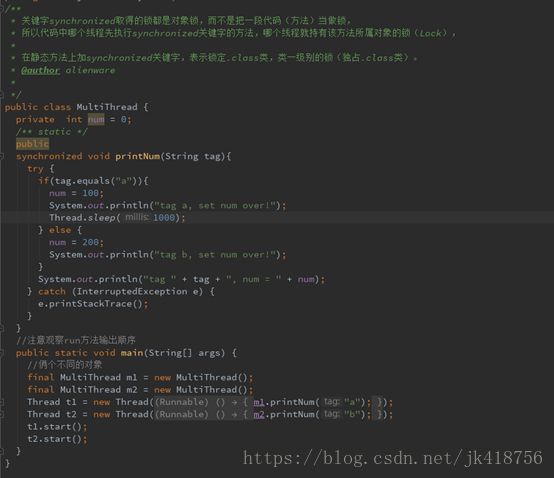
线程B和线程A同时执行了
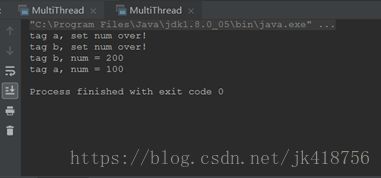
Synchronized的四种用法
Synchronized修饰非静态方法和代码块时取得的是对象锁,每个对象对应一个对象锁
Synchronized修饰静态方法和代码块时取得的是类锁,所有对象对应一个类锁
(对象锁仅针对被Synchronized修饰方法和代码块,对其他区域不起线程同步的作用)
- 修饰一个类,其作用的范围是synchronized后面括号括起来的部分, 作用的对象是这个类的所有对象。
class ClassName {
public void method() {
synchronized(ClassName.class) {
// todo
}
}
}
- 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法, 作用的对象是调用这个方法的对象。
public synchronized void method(){
// todo
}
- 修饰一个静态的方法,其作用的范围是整个静态方法, 作用的对象是这个类的所有对象;
public synchronized static void method() {
// todo
}
- 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码, 作用的对象是调用这个代码块的对象;
class ClassName {
public void method() {
synchronized(this) {
// todo
}
}
}
线程中的脏读
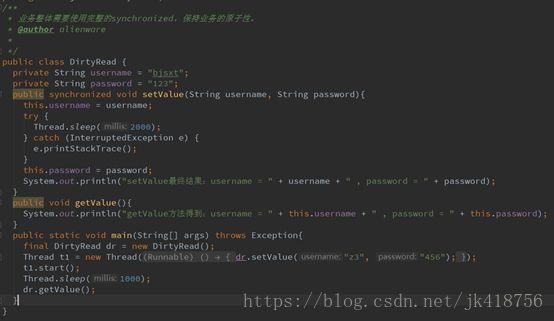
在写方法正在执行的时候,执行了读方法,结果得到了未经修改的密码123
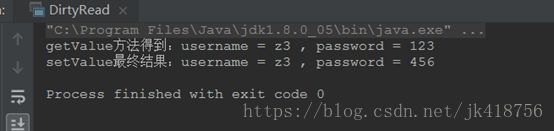
这种情况是应当避免的,可以给读写方法都加上synchronized
引申:数据库的ACID
A:Atomicity原子性 事务中的所有操作要么全部完成,要么就像全部没有发生一样
C:Consistency一致性 无论事务成功和失败,数据的完整性不会被破坏,例如 a+b=2000 依然相等。
I:Isolation隔离性 事务在未提交时在各自的空间操作,互不可见
D:Durability持久性 数据一旦被事务提交,其状态就保持不变,数据被持久化下来
1. 实现方式:
- 隔离性I:通过锁来实现
- 原子性和持久性AD:通过redo log 来实现
- 一致性C:通过undo来实现
2. redo 和 undo 比较:
- 都是恢复操作:
redo:恢复提交事务修改的页操作
undo: 回滚行记录到某个特定版本
- 记录内容不同:
redo : 在数据库运行时,不需要读取操作(注:数据库恢复时,才用redo)
undo : 在数据库运行时,需要随机读取(注:回滚时用undo)
- 读取方式不同:
redo : 在数据库运行时,不需要读取操作(注:数据库恢复时,才用redo)
undo : 在数据库运行时,需要随机读取(注:回滚时用undo)
3. redo 和 undo 的工作流程:
假设有A、B两个数据,值分别为1,2.
A.事务开始.
B.记录A=1到undolog.
C.修改A=3.
D.记录A=3到redolog.
E.记录B=2到undolog.
F.修改B=4.
G.记录B=4到redolog.
H.将undologe和redolog写入磁盘。
I.事务提交,数据持久化
这里有一个隐含的前提条件:‘数据都是先读到内存中,然后修改内存中的数据,最后将数据写回磁盘’。
- A. 为了保证持久性,必须在事务提交前将Redo Log持久化。
- B. 数据不需要在事务提交前写入磁盘,而是缓存在内存中。
- C. Redo Log保证事务的持久性,如果断电前Redo 已持久化,会在重启时将更改写入磁盘。
- D. Undo Log保证事务的原子性,在事务提交前任何时段出错,数据都可以回滚到初始状态。
- E. 有一个隐含的特点,数据必须要晚于redo log写入持久存储。
4. IO性能
Undo + Redo的设计主要考虑的是提升IO性能。虽说通过缓存数据,减少了写数据的IO. 但是却引入了新的IO,即写Redo Log的IO。如果Redo Log的IO性能不好,就不能起到提高性能的目的。
为了保证Redo Log能够有比较好的IO性能,InnoDB 的 Redo Log的设计有以下几个特点:
- A. 尽量保持Redo Log存储在一段连续的空间上。因此在系统第一次启动时就会将日志文件的空间完全分配。以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。(顺序IO)
- B. 批量写入日志。日志并不是直接写入文件,而是先写入redo log buffer.当需要将日志刷新到磁盘时 (如事务提交),将许多日志一起写入磁盘.
- C. 并发的事务共享Redo Log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起,以减少日志占用的空间。
- D. 因为C的原因,当一个事务将Redo Log写入磁盘时,也会将其他未提交的事务的日志写入磁盘。
- E. Redo Log上只进行顺序追加的操作,当一个事务需要回滚时,它的Redo Log记录也不会从Redo Log中删除掉。
5. 顺序IO和随机IO
Redo Log使用了顺序IO,大大提高的写入的性能,那么什么是顺序IO和随机IO呢?
曾经去过寿司店吗,那里的食物都是放在一个传送带上。随着每份食品在带上的传送,你瞄准了一些食物,等它们来到跟前时,立刻拿走它。然而如果你像我一样那么迟疑,那就有可能食物已经超出了你能够着的范围了。这时候你就得再等上一圈才可能拿到,前提还是别人没取走
我们假定一道食品在传送带上走完一圈需要4分钟,为简单起见还假定传送带上的食品互不相同。作为一个吃货,你看了看菜单,找到了几样你想要的食物,它就在带上的某个地方,那么需要多久才会到达你的旁边呢?
我们指定它可以在带上的任何地方。可能正在经过,你不需要等待就可以拿到手,或者它刚刚过了你的范围,那么需要4分钟的等待转完一圈。当你遵循这套随机规则(菜单中选择食品然后看传送带),就会意识到平均等待时间将会倾向于最大和最小等待时间的中间位置,也就是2分钟。于是乎你每次取食物时都需要等待2分钟,如果你有8个盘子,那很可能你需要等上16分钟才能取完。欢迎来到磁盘数据饮食,希望你不会太饿?
现在让我们来考虑另一种方案,你订了8道菜,厨师依次把他们放在了传送带的某个地方,位置是随机的,所以你需要等上平均时间2分钟取得第一份菜。然而剩下的7份菜都不需要等待。所以在这种场景下,取8道菜你只需等2分钟,比刚才好多了。
我确定你能看懂我在文章开头所作的类比了。传送带就是磁盘,食品就好比要吃/读的块。我改日会有另外一篇文章来谈磁盘原理。但现在,我大概说一下基本内容:每次访问磁盘的一个块时,磁臂就需移动到正确的磁道上(这段时间为寻址时间),然后盘片就需旋转到正确的扇区上(这叫旋转时延)。这套动作需要时间,正如寿司在传送带上传送需要时间一样。
很明显总共的时间依赖于磁头的初使位置,还有要访问的扇区的位置。如果它刚好就在磁头下方,那不需要等待;如果刚刚经过磁头,那就不得不等上一个周期时间。哪怕对于最快的15k RPM磁盘,每分钟15000转,每秒250转,那么一转需要4ms。很明显比刚才寿司的情况要快得多,但是很多时候需要读上大量的数据块,远远超过我要吃的寿司量。相信我,这种时候的时间我都可以打包好几份了。
PS:博文仅作为个人学习笔记,如有错误欢迎指正,转载请注明出处~
详见:笔记分类导航目录
参考文档:
1. MySql-Undo及Redo详解 https://blog.csdn.net/alexdamiao/article/details/51872477
2. 理解I/O:随机和顺序 https://blog.csdn.net/BaiWfg2/article/details/52885287?utm_source=blogxgwz0