回顾2016--Apache Flink流处理在生产中的实践
从2016年4月底开始接触Flink,到现在已经8个多月了。从了解到熟悉,再到实际开发,这个过程就是我从0到实际开发使用Flink的过程。
上周,我们的Flink流计算程序终于上线了。也算是在实时流计算方面的一个成果。
下面,我将简要介绍下公司如何使用Flink进行流处理的开发。
1、简介
我们主要是针对股票市场,进行实时的流处理,统计出各种相关的指标,并将输出提供给公司的产品用作展示和一些策略的生成。
2、为什么选用Apache Flink ?
公司要求提供的数据以低延迟为首要目标,同时尽可能保证正确性与较低的成本。我们的需求类似于下图中的描述:

在选型阶段,开源的分布式流处理的框架主要有Storm、Spark Streaming以及Flink等。
1、Spark Streaming: 当时正值Spark非常火爆的时期,但是其micro-batch的本质决定了其提供低延迟的能力相对较弱,不能满足我们的需求,故放弃了Spark。
2、Storm: Storm可是说是低延迟的代表,但是其本身在吞吐量以及不能很好的提供exactly-once的处理(trident又回归批处理了),同时对于session window和state的支持都不够好,因此也没有使用。
3、Flink: 一个非常新(仅听说过)的纯流式计算框架,能够提供低延迟、带状态的操作、提供基于event time的处理,同时支持session window以及处理乱序的能力,使得我们最终选择了Flink。- 1
- 2
- 3
- 4
- 5
Flink特性:

2、面临的挑战
选择Flink,当时来讲不得不说是一次大胆的尝试,对于Google Cloud DataFlow,Flink算是对其论文实现最好的框架了,但是也是资料最少的一个框架。(当时都不知道国内有哪些公司在用,中文资料更是很少)
学习之初,只有官方文档和源代码,中文的资料当时除了2篇概括性的文章外(深入理解Apache Flink核心技术,新一代大数据处理引擎 Apache Flink),就只有VinoYang’sBlog以及Jark’s Blog可以参考。
在学习的过程中,也非常感谢VinoYang和Jark以及李呈祥对我的帮助和对我提出的问题的耐心回答,使得我在最开始时度过了一段比较黑暗的时光。
3、Flink的部署模式
我们目前线上生产系统采用的Standalone HA模式,而测试环境则是yarn cluster模式。之所以线上没有使用yarn模式,主要考虑是当前Flink中yarn的支持没有实现动态分配,而且其他公司使用的也不多,而阿里的Blink中对yarn的改进,反馈给社区要到未来的版本,所以我们就稳妥起见,选择了standalone模式。
4、data flow流程
下面进入重点,简单介绍下我们如何使用Flink进行流处理开发的。

我们的数据流大致如下:
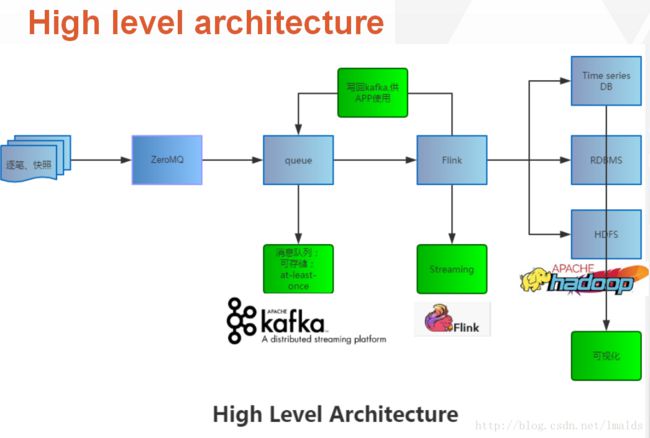
从交易所出来的数据,经过ZMQ接收并pub出来,给不同的框架或者其他系统统一使用。然后我们选择Kafka作为MQ,接收并存储,然后立刻pub出来,供Flink消费。通过Flink处理后的数据流,根据某些需要会将部分结果再次写回Kafka,再次由Flink处理;有些数据流在处理完成后,则是直接输出到HDFS和DB中。
这里有一个非常匪夷所思的架构设计就是ZeroMQ本身就是一个MQ框架,为什么还要用Kafka再加一层?这样做岂不是既增加了延迟又增加了复杂度么?
我们主要考虑到业务上要求对数据的处理更精细化,要做到exactly-once语义的处理。Flink的检查点机制可以做到失败时恢复,但源头也必须很好的支持部分数据源的重发。这点很重要,而ZMQ不具备存储数据的能力,消费完后就删除了,所以我们只得使用Kafka来作为Flink真正的源头。
在实际的测试过程中,我们测试的结果是从数据产生(event time),到Flink消费时的时间(processing time)的间隔,平均在50ms左右。这达到了我们需求,所以加一层Kafka并没有使得延迟增加,而且解决了我们的问题。

5、streaming的细节
下图展示了我们在流处理中的部分实现细节:
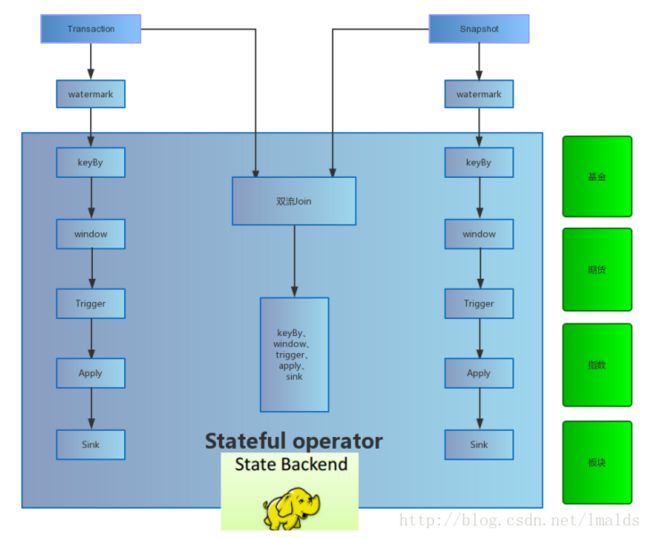
5.1、单流与多流
1、单流的基于event time的窗口操作
2、双流的基于event time的Join(实际上是coGroup)操作- 1
- 2
Flink中的operator是可以有状态的,这极大的降低了我们开发的难度,而且有效的实现了很多复杂计算的逻辑(apply中实现)。
同时,在单流(单流转换)与多流中,我们有些也需要获取外部数据源(DB)的配置信息,我们则通过RichXXXFunction中提供的Context功能,在open()中得以实现。
5.2、watermark
对于流数据在网络传输中可能出现的乱序情况,我们通过watermark对乱序的数据进行处理。
由于我们采用event time作为我们的时间度量,因此source之后,进行简单的filter与map后,立刻emit watermark。我们这里实现基于Periodic的Watermarks,并自定义与业务紧密相关的watermark机制。
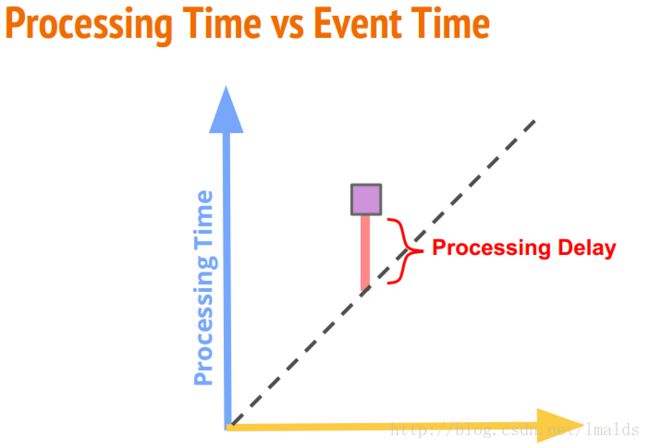
简单来说还是以允许一段时间的乱序,加上一些边界时,对watermark进行的特殊处理来实现自定义的watermark。
5.3、window
由于流是无界的,而我们需要将无界的流在一个有界的范围内进行处理,因此在window内实现业务逻辑。
我们实际开发中,用到了2类窗口:
1、TimeWindow,这里主要用到Flink中预定义的TumblingEventTimeWindow以及没有区分key的windowAll操作。
2、GlobalWindow,这里主要涉及基于count的窗口,通过数据的count来触发窗口。- 1
- 2
最开始本想采用session window实现,但是实际上需要兼容现有产品的一些设计,因此没就没有使用session window实现,转而通过TimeWindow实现。
5.4、trigger
数据被聚合到window后,何时被触发,这个就要依赖于trigger了。Flink中的trigger机制比较简单,有3种抽象:
1、onElement
2、onProcessingTime
3、onEventTime- 1
- 2
- 3
由于我们只使用event time作为处理的时间,以及使用GlobalWindow、基于count的触发机制,因此我们都是使用了Flink预定义的watermark trigger机制,这也是默认的trigger机制,即当event time trigger时,watermark到达了window结束的时间后,自定触发窗口计算;当count数量到达了设定的count值后,触发窗口的计算。
Flink在trigger的实现上,目前还有很多改进之处,这在我们开发中也遇到了一些问题,例如由于严重依赖watermark trigger,因此如果长时间数据没有到达窗口的触发条件,则窗口不会触发;这对于边界时间来讲,是不可接收的。
那我们是如何解决这个问题的呢?
我们通过了对watermark在边界时间的改造,间接的实现了类似earlier trigger的功能,使得延迟保持较低的程度。- 1
其实现在想想,我们为什么要使用trigger?
trigger本质上来讲的功能就是在数据的正确性、延迟以及成本之间进行平衡的一种机制。 
只不过当前Flink1.1.X版本中,对trigger的实现还没有像Google Cloud DataFlow那么完备。
但现在Flink社区将在Flink1.2中,增加window中的元数据信息(例如提供触发window的原因等),同时对trigger的支持将实现组合式trigger、earlier trigger以及later trigger等功能,同时,对于late的元素,也可以选择丢弃或者重新累加计算等细化的功能。具体见:FLIP-2 Extending Window Function Metadata以及FLIP-9: Trigger DSL。
这一特性将完全匹配DataFlow模型中的trigger机制,同时我们未来的程序中,也有可能使用最新的Flink版本进行开发。
5.5、sink
我们目前将中间的DataStream流写入到Kafka、DB以及HDFS,供现有产品使用。
5.6、state存储
Flink的检查点的触发,会生成分布式快照,而快照中除了系统运行时的一些元数据信息外,就是程序中各种状态的数据了,例如window中的数据,UDF的方法中的数据等。目的是在恢复时实现exactly-once语义的处理。
Flink支持有状态的operator以及UDF的state,而支持的state backend包括3种方式:
1、JobManager memory(当前版本的默认模式)
2、HDFS
3、RocksDB(未来Flink版本的默认模式) - 1
- 2
- 3
JobManager的memory存储快照有很大的风险,主要表现在两方面:
1、JobManager一旦失败,则内存的快照数据丢失;如果配置了HA(通过zookeeper实现),虽然可以自动切换到standby JobManager,但是原JobManager中的快照信息就丢失了,也就无法做到exactly-once。
2、JobaManager的内存有限,一旦快照的大小很大,例如上百兆或者更大,那么肯定会对JobManager造成性能上的影响;而且频繁的将快照存入JobManager的内存,即使快照大小比较小,但是对于JobManager与TaskManager和Zookeeper之间的通信,也会造成一定的影响。- 1
- 2
- 3
基于这两方面,我们选择了较为稳妥的HDFS上。这可以通过配置文件实现state backend的存储;
对于RocksDB,则是官方非常推荐的一种state backend。也是未来版本的默认模式,我们这里没有使用。
5.7、实现了哪些业务
这里不打算详细介绍业务,只说下我们基于Flink data streaming,实现了对股票、基金、期货、指数以及板块的实时统计,并在基础上对某些特殊的指标进行了一些策略的处理。
6、总结
Apache Flink在流处理方面的诸多特性,以及我们自身的业务需求,是促使我学习并实践Flink的根本原因。
目前国内使用Flink的公司主要是阿里(实际是二次开发后的Blink),并也投入到了实际的生产中。虽然数据量以及集群规模无法相比,但是这也从侧面反映出Flink是具有很大的潜力的。
最后,对于已经或者准备使用Flink的朋友,我把我曾经学习的资源(主要是网络博客)共享:
1、Flink源码
2、官方文档1.2
3、官方博客
4、Flink母公司data-Artisans官方博客
5、Flink Training
6、Madhukar’s Blog
7、Flink1.1中文文档(部分)
8、The world beyond batch: Streaming 101
9、The world beyond batch: Streaming 102
10、VinoYang的专栏
11、Jark’s Blog
12、fxjwind
当然,还有些其他的朋友也在写Flink相关的内容,大家可以自行google学习。