flink在k8s上的部署和使用教程
进大厂,身价翻倍的法宝来了!
主讲内容:docker/kubernetes 云原生技术,大数据架构,分布式微服务,自动化测试、运维。
视频地址:ke.qq.com/course/419718
官网:https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/python.html
架构
要了解一个系统,一般都是从架构开始。我们关心的问题是:系统部署成功后各个节点都启动了哪些服务,各个服务之间又是怎么交互和协调的。下方是 Flink 集群启动后架构图。

当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
- Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
- JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
- TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
可以看到 Flink 的任务调度是多线程模型,并且不同Job/Task混合在一个 TaskManager 进程中。
Graph
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
这里对一些名词进行简单的解释。
-
StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
- StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
- StreamEdge:表示连接两个StreamNode的边。
-
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
- JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
- IntermediateDataSet:表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge。
- JobEdge:代表了job graph中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
-
ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。
- ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是IntermediateResultPartition。
- IntermediateResult:和JobGraph中的IntermediateDataSet一一对应。一个IntermediateResult包含多个IntermediateResultPartition,其个数等于该operator的并发度。
- IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。
- ExecutionEdge:表示ExecutionVertex的输入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。
- Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
-
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
- Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
- ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应。
- ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
- InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition。
- InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。

首先我们看到,JobGraph 之上除了 StreamGraph 还有 OptimizedPlan。OptimizedPlan 是由 Batch API 转换而来的。StreamGraph 是由 Stream API 转换而来的。为什么 API 不直接转换成 JobGraph?因为,Batch 和 Stream 的图结构和优化方法有很大的区别,比如 Batch 有很多执行前的预分析用来优化图的执行,而这种优化并不普适于 Stream,所以通过 OptimizedPlan 来做 Batch 的优化会更方便和清晰,也不会影响 Stream。JobGraph 的责任就是统一 Batch 和 Stream 的图,用来描述清楚一个拓扑图的结构,并且做了 chaining 的优化,chaining 是普适于 Batch 和 Stream 的,所以在这一层做掉。ExecutionGraph 的责任是方便调度和各个 tasks 状态的监控和跟踪,所以 ExecutionGraph 是并行化的 JobGraph。而“物理执行图”就是最终分布式在各个机器上运行着的tasks了。所以可以看到,这种解耦方式极大地方便了我们在各个层所做的工作,各个层之间是相互隔离的。
在k8s上的部署集群版flink服务器端
官网:https://ci.apache.org/projects/flink/flink-docs-stable/ops/deployment/kubernetes.html
Flink会话群集作为长期运行的Kubernetes部署执行。请注意,您可以在会话群集上运行多个Flink作业。部署群集后,需要将每个作业提交到群集。
安装后打开web页面

master节点运行jobManager程序
每一个worker节点将运行一个taskmanager程序。
- The Web Client is on port 8081
- JobManager RPC port 6123
- TaskManagers RPC port 6122
- TaskManagers Data port 6121
下载flink二进制软件
下载地址https://flink.apache.org/downloads.html
我这边使用的是flink1.7.2,hadoop2.7,scala2.11,所以我下载的是flink-1.7.2-bin-hadoop27-scala_2.11.tgz
我们开发的代码只是在客户端上,如果用服务器端的flink,需要我们在客户端的配置文件里面把flink服务器端信息配置进去。
配置文件在flink-1.7.2/conf/flink-conf.yaml中
jobmanager.rpc.address : master 节点ip
jobmanager.rpc.port: 6123 端口
rest.port: 8081 端口号
jobmanager.heap.mb : JobManager可用的内存数量 单位MB
taskmanager.heap.mb : 每个TaskManager可以用内存数量 单位MB
taskmanager.numberOfTaskSlots : 每个机器可用的CPU数量
parallelism.default : 集群中总的CPU数量
taskmanager.tmp.dirs : 临时目录
因为我们这里提交的是python进程,所以需要在jobmanager和taskmanager使用的flink镜像中封装python的包。
这里我们重构镜像,如果你的python代码用到其他的包,需要你自己把包封装进来
Dockerfile文件内容如下
FROM flink:latest
RUN apt update && apt install -y python3-dev && ln -s /usr/bin/python3 /usr/bin/python && apt install -y procps && apt clean
重新构建镜像
docker build -t luanpeng/lp:flink-1.7.2 .
将k8s部署文件中的镜像改为 luanpeng/lp:flink-1.7.2
提交流程
要想提交本地py文件的应用到集群,需要在配置文件中加入集群启动的相关信息,在flink-1.7.2/conf/flink-conf.yaml文件中修改内容
# JobManager的地址
jobmanager.rpc.address: 192.168.11.127
#JobManager的端口,默认6123
jobmanager.rpc.port: 32224
其他的任务调度的配置信息也可以在这个文件中修改。
我们在客户端上,我们编写了python代码,通过flink的pyflink.sh脚本,将我们的代码分解为job,并向jobmanager服务器发送job启动,并接收返回结果。在显示给我们的python代码端。
默认情况下,Flink通过调用”python”或”python3″来启动python进程,这取决于使用了哪种启动脚本。通过在 flink-conf.yaml 中设置 “python.binary.python[2/3]”对应的值,来设定你所需要的启动方式。
我们这里测试的python代码如下wordcount.py
from flink.plan.Environment import get_environment
from flink.functions.GroupReduceFunction import GroupReduceFunction
class Adder(GroupReduceFunction):
def reduce(self, iterator, collector):
count, word = iterator.next()
count += sum([x[0] for x in iterator])
collector.collect((count, word))
# 加载本地配置文件,获取一个集群运行环境
env = get_environment()
# 加载/创建一个运行环境
data = env.from_elements("Who's there?", "I think I hear them. Stand, ho! Who's there?")
# 指定对这些数据的操作
data \
.flat_map(lambda x, c: [(1, word) for word in x.lower().split()]) \
.group_by(1) \
.reduce_group(Adder(), combinable=True) \
.output()
# 运行程序
# env.execute(local=True) # 设置execute(local=True)强制程序在本机运行
result = env.execute() # 设置execute(local=True)强制程序在本机运行
print(result)
其中,output()方法仅适用于在本机上进行开发/调试,它会将数据集的内容输出到标准输出。(请注意,当函数在集群上运行时,结果将会输出到整个集群节点的标准输出流,即输出到workers的.out文件。)前两种方法,能够将数据集写入到对应的文件中。
使用客户端,将python脚本生成job推送到jobmanager
$ flink-1.7.2/bin/pyflink.sh ./wordcount.py
Starting execution of program
Program execution finished
Job with JobID 22b8b06de9a5f56a71468d60063f1e94 has finished.
Job Runtime: 496 ms
这样就可以在taskmanager的pod中看到输出结果了。
在web页面上,我们也能看到执行成功
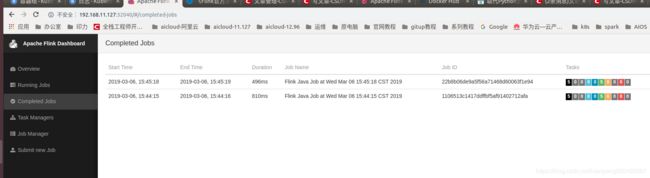
点击进入可以看到job进度图

如果执行不成功,可以在该页面查看Exceptions中显示的报错信息。
任务详解
从示例程序可以看出,Flink程序看起来就像普通的python程序一样。每个程序都包含相同的基本组成部分:不能缺少了某些部分,不然会无法执行。
- 获取一个运行环境
- 加载/创建初始数据
- 指定对这些数据的操作
- 指定计算结果的存放位置
- 运行程序
Environment(运行环境)是所有Flink程序的基础。通过调用Environment类中的一些静态方法来建立一个环境:
get_environment()
运行环境可通过多种读文件的方式来指定数据源。如果是简单的按行读取文本文件:
env = get_environment()
text = env.read_text("file:///path/to/file")
这样,你就获得了可以进行操作(apply transformations)的数据集。关于数据源和输入格式的更多信息,请参考Data Sources
一旦你获得了一个数据集DataSet,你就可以通过transformations来创建一个新的数据集,并把它写入到文件,再次transform,或者与其他数据集相结合。你可以通过对数据集调用自己个性化定制的函数来进行数据操作。例如,一个类似这样的数据映射操作:
data.map(lambda x: x*2)
这将会创建一个新的数据集,其中的每个数据都是原来数据集中的2倍。若要获取关于所有transformations的更多信息,及所有数据操作的列表,请参考Transformations。
当需要将所获得的数据集写入到磁盘时,调用下面三种函数的其中一个即可。
data.write_text("", WriteMode=Constants.NO_OVERWRITE)
write_csv("", line_delimiter='\n', field_delimiter=',', write_mode=Constants.NO_OVERWRITE)
output()
其中,最后一种方法仅适用于在本机上进行开发/调试,它会将数据集的内容输出到标准输出。(请注意,当函数在集群上运行时,结果将会输出到整个集群节点的标准输出流,即输出到workers的.out文件。)前两种方法,能够将数据集写入到对应的文件中。关于写入到文件的更多信息,请参考Data Sinks。
当设计好了程序之后,你需要在环境中执行execute命令来运行程序。可以选择在本机运行,也可以提交到集群运行,这取决于Flink的创建方式。你可以通过设置execute(local=True)强制程序在本机运行。
本地调试
如果先不适用集群版flink,先使用本地flink进行代码调试,可以先在本地启动集群
flink-1.7.2/bin/start-cluster.sh
在配置文件conf/flink-conf.yaml中,设置集群的ip为localhost,端口可以不变。然后在代码中设置
env.execute(local=True) # 设置execute(local=True)强制程序在本机运行
这样就能调用本地的flink进行代码调试。
flink 日志
Flink中的日志记录是使用slf4j日志记录界面实现的。作为底层日志记录框架,使用log4j。flink还提供了logback配置文件,并将它们作为属性传递给JVM。愿意使用logback而不是log4j的用户可以只排除log4j(或从lib /文件夹中删除它)。
log4j的配置文件在conf/log4j.properties中,flink使用-Dlog4j.configuration=参数将此文件的文件名和位置传递给JVM。
Flink附带以下默认属性文件:
- log4j-cli.properties:由Flink命令行客户端使用(例如flink run)(不是在集群上执行的代码)
- log4j-yarn-session.properties:启动YARN会话时由Flink命令行客户端使用(yarn-session.sh)
- log4j.properties:JobManager / Taskmanager日志(独立和YARN)
调试日志在flink文件夹的log目录下面,由于flink没找到哪里配置日志level,所以控制台只会输出
starting execution of program
Failed to run plan: Job failed. (JobID: b8c522c0257bbd3a62b422045e21acad)
The program didn't contain a Flink job. Perhaps you forgot to call execute() on the execution environment.
所以只能自己查看日志文件。
延迟(惰性)求值
所有的Flink程序都是延迟执行的。当程序的主函数执行时,数据的载入和操作并没有在当时发生。与此相反,每一个被创建出来的操作都被加入到程序的计划中。当程序环境中的某个对象调用了execute()函数时,这些操作才会被真正的执行。不论该程序是在本地运行还是集群上运行。
延迟求值能够让你建立复杂的程序,并在Flink上以一个整体的计划单元来运行。
数据变换
- 数据变换(Data transformations)可以将一个或多个数据集映射为一个新的数据集。程序能够将多种变换结合到一起来进行复杂的整合变换。
该小节将概述各种可以实现的数据变换。transformations documentation数据变换文档中,有关于所有数据变换和示例的全面介绍。
- Map:输入一个元素,输出一个元素
data.map(lambda x: x * 2)
- FlatMap:输入一个元素,输出0,1,或多个元素
data.flat_map(
lambda x,c: [(1,word) for word in line.lower().split() for line
in x])
- MapPartition:通过一次函数调用实现并行的分割操作。该函数将分割变换作为一个”迭代器”,并且能够产生任意数量的输出值。每次分割变换的元素数量取决于变换的并行性和之前的操作结果。
data.map_partition(lambda x,c: [value * 2 for value in x])
- Filter:对每一个元素,计算一个布尔表达式的值,保留函数计算结果为true的元素。
data.filter(lambda x: x > 1000)
- Reduce:通过不断的将两个元素组合为一个,来将一组元素结合为一个单一的元素。这种缩减变换可以应用于整个数据集,也可以应用于已分组的数据集。
data.reduce(lambda x,y : x + y)
- ReduceGroup:将一组元素缩减为1个或多个元素。缩减分组变换可以被应用于一个完整的数据集,或者一个分组数据集。
lass Adder(GroupReduceFunction):
def reduce(self, iterator, collector):
count, word = iterator.next()
count += sum([x[0] for x in iterator)
collector.collect((count, word))
data.reduce_group(Adder())
- Aggregate:对一个数据集包含所有元组的一个域,或者数据集的每个数据组,执行某项built-in操作(求和,求最小值,求最大值)。聚集变换可以被应用于一个完整的数据集,或者一个分组数据集。
# This code finds the sum of all of the values in the first field
and the maximum of all of the values in the second field
data.aggregate(Aggregation.Sum, 0).and_agg(Aggregation.Max, 1)
# min(), max(), and sum() syntactic sugar functions are also available
data.sum(0).and_agg(Aggregation.Max, 1)
- Join:对两个数据集进行联合变换,将得到一个新的数据集,其中包含在两个数据集中拥有相等关键字的所有元素对。也可通过JoinFunction来把成对的元素变为单独的元素。关于join keys的更多信息请查看 keys
# In this case tuple fields are used as keys.
# "0" is the join field on the first tuple
# "1" is the join field on the second tuple.
result = input1.join(input2).where(0).equal_to(1)
- CoGroup:是Reduce变换在二维空间的一个变体。将来自一个或多个域的数据加入数据组。变换函数transformation function将被每一对数据组调用。关于定义coGroup keys的更多信息,请查看 keys 。
data1.co_group(data2).where(0).equal_to(1)
- Cross:计算两个输入数据集的笛卡尔乘积(向量叉乘),得到所有元素对。也可通过CrossFunction实现将一对元素转变为一个单独的元素。
result = data1.cross(data2)
- Union:将两个数据集进行合并。
data.union(data2)
- ZipWithIndex:为数据组中的元素逐个分配连续的索引。了解更多信息,请参考 【Zip Elements Guide】(zip_elements_guide.html#zip-with-a-dense-index).
data.zip_with_index()
指定keys
- 一些变换(例如Join和CoGroup),需要在进行变换前,为作为输入参数的数据集指定一个关键字,而另一些变换(例如Reduce和GroupReduce),则允许在变换操作之前,对数据集根据某个关键字进行分组。
数据集可通过如下方式分组
reduced = data \
.group_by() \
.reduce_group()
Flink中的数据模型并不是基于键-值对。你无需将数据集整理为keys和values的形式。键是”虚拟的”:它们被定义为在真实数据之上,引导分组操作的函数。
为元组定义keys
- 最简单的情形是对一个数据集中的元组按照一个或多个域进行分组:
grouped = data \
.group_by(0) \
.reduce(/*do something*/)
数据集中的元组被按照第一个域分组。对于接下来的group-reduce函数,输入的数据组中,每个元组的第一个域都有相同的值。
grouped = data \
.group_by(0,1) \
.reduce(/*do something*/)
在上面的例子中,数据集的分组基于第一个和第二个域形成的复合关键字,因此,reduce函数输入数据组中,每个元组两个域的值均相同。
关于嵌套元组需要注意:如果你有一个使用了嵌套元组的数据集,指定group_by()操作,系统将把整个元组作为关键字使用。
向Flink传递函数
- 一些特定的操作需要采用用户自定义的函数,因此它们都接受lambda表达式和rich functions作为输入参数。
data.filter(lambda x: x > 5)
class Filter(FilterFunction):
def filter(self, value):
return value > 5
data.filter(Filter())
Rich functions可以将函数作为输入参数,允许使用broadcast-variables(广播变量),能够由init()函数参数化,是复杂函数的一个可考虑的实现方式。它们也是在reduce操作中,定义一个可选的combine function的唯一方式。
Lambda表达式可以让函数在一行代码上实现,非常便捷。需要注意的是,如果某个操作会返回多个数值,则其使用的lambda表达式应当返回一个迭代器。(所有函数将接收一个collector输入 参数)。
数据类型
- Flink的Python API目前仅支持python中的基本数据类型(int,float,bool,string)以及byte arrays。
运行环境对数据类型的支持,包括序列化器serializer,反序列化器deserializer,以及自定义类型的类。
class MyObj(object):
def __init__(self, i):
self.value = i
class MySerializer(object):
def serialize(self, value):
return struct.pack(">i", value.value)
class MyDeserializer(object):
def _deserialize(self, read):
i = struct.unpack(">i", read(4))[0]
return MyObj(i)
env.register_custom_type(MyObj, MySerializer(), MyDeserializer())
Tuples/Lists
可以使用元组(或列表)来表示复杂类型。Python中的元组可以转换为Flink中的Tuple类型,它们包含数量固定的不同类型的域(最多25个)。每个域的元组可以是基本数据类型,也可以是其他的元组类型,从而形成嵌套元组类型。
word_counts = env.from_elements(("hello", 1), ("world",2))
counts = word_counts.map(lambda x: x[1])
当进行一些要求指定关键字的操作时,例如对数据记录进行分组或配对。通过设定关键字,可以非常便捷地指定元组中各个域的位置。你可以指定多个位置,从而实现复合关键字(更多信息,查阅Section Data Transformations)。
wordCounts \
.group_by(0) \
.reduce(MyReduceFunction())
数据源
- 数据源创建了初始的数据集,包括来自文件,以及来自数据接口/集合两种方式。
- 基于文件的:
read_text(path) – 按行读取文件,并将每一行以String形式返回。
read_csv(path,type) – 解析以逗号(或其他字符)划分数据域的文件。
返回一个包含若干元组的数据集。支持基本的java数据类型作为字段类型。
- 基于数据集合的:
from_elements(*args) – 基于一系列数据创建一个数据集,包含所有元素。
generate_sequence(from, to) – 按照指定的间隔,生成一系列数据。
- Examples
env = get_environment
\# read text file from local files system
localLiens = env.read_text("file:#/path/to/my/textfile")
\# read text file from a HDFS running at nnHost:nnPort
hdfsLines = env.read_text("hdfs://nnHost:nnPort/path/to/my/textfile")
\# read a CSV file with three fields, schema defined using constants defined in flink.plan.Constants
csvInput = env.read_csv("hdfs:///the/CSV/file", (INT, STRING, DOUBLE))
\# create a set from some given elements
values = env.from_elements("Foo", "bar", "foobar", "fubar")
\# generate a number sequence
numbers = env.generate_sequence(1, 10000000)
数据接收器
- 数据接收器可以接受DataSet,并用来存储和返回它们:
-
write_text() –按行以String形式写入数据。可通过对每个数据项调用str()函数获取String。
-
write_csv(…) – 将元组写入逗号分隔数值文件。行数和数据字段均可配置。每个字段的值可通过对数据项调用str()方法得到。
-
output() – 在标准输出上打印每个数据项的str()字符串。
一个数据集可以同时作为多个操作的输入数据。程序可以在写入或打印一个数据集的同时,对其进行其他的变换操作。
- 标准数据池相关方法示例如下:
write DataSet to a file on the local file system
textData.write_text("file:///my/result/on/localFS")
write DataSet to a file on a HDFS with a namenode running at nnHost:nnPort
textData.write_text("hdfs://nnHost:nnPort/my/result/on/localFS")
write DataSet to a file and overwrite the file if it exists
textData.write_text("file:///my/result/on/localFS", WriteMode.OVERWRITE)
tuples as lines with pipe as the separator "a|b|c"
values.write_csv("file:///path/to/the/result/file", line_delimiter="\n", field_delimiter="|")
this writes tuples in the text formatting "(a, b, c)", rather than as CSV lines
values.write_text("file:///path/to/the/result/file")
广播变量
-
使用广播变量,能够在使用普通输入参数的基础上,使得一个数据集同时被多个并行的操作所使用。这对于实现辅助数据集,或者是基于数据的参数化法非常有用。这样,数据集就可以以集合的形式被访问。
-
注册广播变量:广播数据集可通过调用with_broadcast_set(DataSet,String)函数,按照名字注册广播变量。
-
访问广播变量:通过对调用self.context.get_broadcast_variable(String)可获取广播变量。
class MapperBcv(MapFunction):
def map(self, value):
factor = self.context.get_broadcast_variable("bcv")[0][0]
return value * factor
# 1. The DataSet to be broadcasted
toBroadcast = env.from_elements(1, 2, 3)
data = env.from_elements("a", "b")
# 2. Broadcast the DataSet
data.map(MapperBcv()).with_broadcast_set("bcv", toBroadcast)
- 确保在进行广播变量的注册和访问时,应当采用相同的名字(示例中的”bcv”)。
注意:由于广播变量的内容被保存在每个节点的内部存储中,不适合包含过多内容。一些简单的参数,例如标量值,可简单地通过参数化rich function来实现。
并行执行
- 该章节将描述如何在Flink中配置程序的并行执行。一个Flink程序可以包含多个任务(操作,数据源和数据池)。一个任务可以被划分为多个可并行运行的部分,每个部分处理输入数据的一个子集。并行运行的实例数量被称作它的并行性或并行度degree of parallelism (DOP)。
在Flink中可以为任务指定不同等级的并行度。
运行环境级
- Flink程序可在一个运行环境execution environment的上下文中运行。一个运行环境为其中运行的所有操作,数据源和数据池定义了一个默认的并行度。运行环境的并行度可通过对某个操作的并行度进行配置来修改。
一个运行环境的并行度可通过调用set_parallelism()方法来指定。例如,为了将WordCount示例程序中的所有操作,数据源和数据池的并行度设置为3,可以通过如下方式设置运行环境的默认并行度。
env = get_environment()
env.set_parallelism(3)
text.flat_map(lambda x,c: x.lower().split()) \
.group_by(1) \
.reduce_group(Adder(), combinable=True) \
.output()
env.execute()
系统级
- 通过设置位于./conf/flink-conf.yaml.文件的parallelism.default属性,改变系统级的默认并行度,可设置所有运行环境的默认并行度。具体细节可查阅Configuration文档。
执行方法
- 为了在Flink中运行计划任务,到Flink目录下,运行/bin文件夹下的pyflink.sh脚本。对于python2.7版本,运行pyflink2.sh;对于python3.4版本,运行pyflink3.sh。包含计划任务的脚本应当作为第一个输入参数,其后可添加一些另外的python包,最后,在“-”之后,输入其他附加参数。
./bin/pyflink<2/3>.sh