Storm开发过程中的问题与建议
(一) topology层级建议设不要设置过多
storm讲究是流式计算,spout发送数据,下游的bolt处理数据,数据的处理计算就像流水线作业一样,每一个节点完成特定的工序;但是这种流水作业的深度不易过长,比如节点A对数据进行split操作,节点B对split之后的数据进行filter过滤,这两个节点完全可以合并在一起。如果topology层级过多,消耗的资源多;节点多,丢数据的风险增大;增加处理事件的环节,不利于排错;
建议:topology的层级控制在5级以下。
(二) 合理使用shuff规则
storm中组件之间流的连接、分组关系有7种:Shuffle Grouping(随机分组)、Fields Grouping(按字段分组)、All Grouping(广播分组)、Global Grouping(全局分组)、Non Grouping(不分组)、Direct Grouping(直接分组)、Local or Shuffle Grouping(本地/随机分组)。其中常用的有:Shuffle Grouping(随机分组)、Fields Grouping(按字段分组)与Local or Shuffle Grouping(本地/随机分组)
Shuffle Grouping:随机分发,它对各个task的tuple分配的比较均匀;
Fields Grouping:它保证相同field值的tuple会去同一个task,比如storm提供的例子中wordcount必须保证相同的元素到同一个task,这时候必须用fields frouping,否则统计出来的数据是不对的;
Local or Shuffle Grouping:如果传送数据的task和接受数据的task在同一个进程之上,那么数据的传输走的是线程之间的通信,否则与shuff grouping类似,因此一般来说local or shuff grouping的性能是优于shuff grouping的(ps:worker内部传输只需要Disruptor队列就可以完成,不用网络开销和序列化开销,shuff grouping所有的数据传输走netty)
是不是说,local or shuff grouping就完美了呢?来看看一个例子,用local or shuff grouping,我开了80个线程,其中有一半的线程的excute 和emit量在2000多,而另一半excute和emit的量在13000左右,结果导致量大的线程的capacity较高,部分由于内存耗尽,worker重启

(三) 使用fieldgrouping导致的数据倾斜问题
使用filedgrouping经常会出现数据倾斜的问题,就是部分线程接收的数据很多,而其他的很少。举个例子,11.11来了,某APP商家统计实时PV,假设安卓在线用户1000万,ios用户10万,现在用app_client做fieldgroup,就会出现这种情况!
怎么办?当让解决的思路很多,单原则都是一样:尽量让它们离散。我们可以app_client+app_version+province,也就是从多级多维度的角度出发,尽量使filed离散。
(四) worker数不是越多越好
worker数并不是越多越好!
每增加一个worker进程,都会讲一些原本线程之间的通信变为进程之间的网络通信,这些进程间的网络通信海需要进行序列化和反序列化操作,这些都会降低吞吐量;另外每增加一个worker进程都会额外增加多个线程(netty发送和接受的线程、心跳线程、systembolt线程以及其他系统组件对应的线程等),这些线程都会消耗系统资源,在系统资源受限的情况下,将降低业务线程的使用效率。
在task保持不变的情况下,worker减少,由于在计算过程之间不同task之间需要切换,worker较少的情况下,进程之间的切换加大,降低了吞吐量,同时worker太少,那么部署的物理节点有限,也限制了整体的性能。
(五) 数据落地视情况考虑批量写入
在很多的场合下,bolt在处理数据落地时如果来一条数据就进行数据存储或者读写是极其耗性能的,特别是在数据量大的情况下,所以一般该场合建议批量写入(读入),策略一般为定时+定量,如下为定时与定量结合的流程:
dataCache(message);//将消息放入内存dataCache
long now = System.currentTimeMillis();
if (now - lastUpdateTime > interval
|| dataCache.size() >= writeSize) {//如果到达了特定的时间或者内存的大小超过了设定的限制
doPersist();//写入数据库(hbase、redis、mysql等)
lastUpdateTime = now;
dataCache.clear();//清空内存
}
collector.ack(input);
return;(六) 优化excute
尽可能优化excute的代码,减少excute的执行时间:
1.excute少打info级别的日志,去掉system.out.println()等
2.慎用加锁
3.try catch比较消耗性能
4.一些大对象在使用完后建议设置为null
(七) 关于Ack
在启用Ack的情况下,每个处理的tuple,必须被ack或者fail,因为storm追踪每个tuple要占用内存,所以如果你不ack/fail每一个tuple,那么最终你会看到OutOfMemory错误(关于storm的ack机制和rotaingmap在ack中应用将会在后续的博文中进行解析)。
(八) 关于Storm UI的使用与调试
几个参数的含义
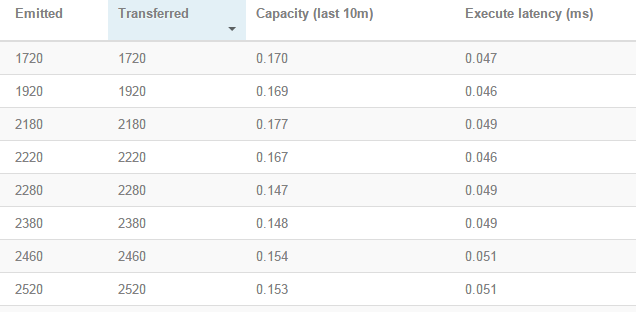
Excute latency:消息的平均处理时间,单位为ms
Process latency:消息从收到到被ack掉所花的时间,单位ms(如果没有启用acker机制,那么该值为0)
Capacity:capacity=bolt调用excute方法处理的消息数量*消息的平均时间/时间区间。ps:在王新春的《storm技术内幕与大数据实践》一书中是这样说的,如果capacity这个值越接近1,说明bolt基本一直在调用execute方法,因此并行度不够,需要扩展这个组件的Executor数量。其实,我认为,这有一点以偏概全,capacity这个参数过高有很多的情况,并不一定是thread数量不够。查看可视化的topology图,利用颜色查看任务的健康程度
蓝色表示输入员spout,bolt的颜色从绿色变化到红色,红色的程度表示bolt的健康程度,越红出问题的可能性越大,如下为一个正常的topology:

如下为一个非正常的topology,值得关注与优化:

查看worker是否重启
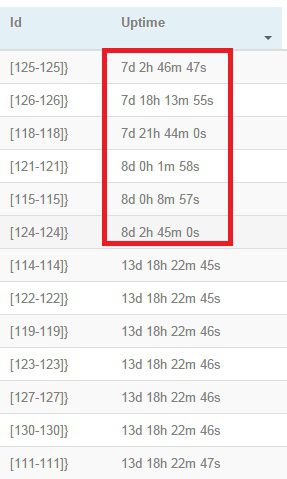
查看worker是否重启,首先查看topology的updateTime:

再进入每一个spout或者bolt,点击“Updatetime”,按照时间顺序排序,我们发现红色部分的时间与topology的updatetime相差甚多,那么对应的worker发生了重启,需要关注背后的问题,如内存溢出导致worker重启等。
4 部分节点excute数与emit数较少现象
上面所说的数据倾斜的现象就是情况之一,当然也可能有其他的原因。
5 capacity较大与处理时间较长
这种情况可以在细分为两种情况
(1)每个节点的capacity都很高
一般来说,capacity高相应的处理时间也比较长,通常情况是线程数不够,如果加大线程capacity下降到0.5以下,而处理时间还是很长的话,那就有必要仔细优化一下代码了。
(2)部分节点capacity较大与处理时间较长现象
部分节点capacity较大,而部分capacity很小。这种情形原因可能很多,我之前遇到过这样一种情况:某几个节点的hbase读写时间比较长,几百毫秒甚至几秒,其他节点读写时间正常,最后发现hadoop复用hbase,hadoop与hbase产生资源竞争,解决方法就是hbase拆分,一下子就好了,代码完全不用改。总之,这种情况很多与外界因素介入有关系,如服务器的网络、所用外部中间件或者数据库的性能等等,需要仔细排查。