Spring Cloud Sleuth服务链路追踪(mysql存储链路数据)(Finchley版本)
在Spring Cloud Sleuth服务链路追踪(Finchley版本)中,我们使用Spring Cloud Sleuth和zipkin的整合实现了服务链路的追踪,但是遗憾的是链路数据存储在内存中,无法持久化。zipkin的持久化可以结合Elasticsearch,MySQL实现。本节在Spring Cloud Sleuth服务链路追踪(Finchley版本)的基础上整合MySQL进行链路数据的持久化。本节示例工程如下:
| 服务 | 端口 | 服务说明 |
|---|---|---|
| eureka | 8761 | 服务注册于发现 |
| provider | 8800 | 服务提供者 |
| consumer | 8801 | 服务消费者 |
| chainMonitor | 8770 | 链路追踪服务端,mysql存储链路数据 |
在这里我们只需对chainMonitor进行部分修改即可,其它服务不用做更改。
1.添加依赖支持mysql存储链路数据
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>priv.simongroupId>
<artifactId>chainmonitorartifactId>
<version>0.0.1-SNAPSHOTversion>
<packaging>jarpackaging>
<name>chainmonitorname>
<description>Demo project for Spring Bootdescription>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.0.5.RELEASEversion>
<relativePath/>
parent>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<java.version>1.8java.version>
<spring-cloud.version>Finchley.SR1spring-cloud.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
<version>2.11.5version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-serverartifactId>
<version>2.11.5version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-storage-mysqlartifactId>
<version>2.11.5version>
dependency>
<dependency>
<groupId>io.zipkin.zipkin2groupId>
<artifactId>zipkin-storage-mysql-v1artifactId>
<version>2.11.5version>
dependency>
<dependency>
<groupId>org.jooqgroupId>
<artifactId>jooqartifactId>
<version>3.11.4version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-dbcp2artifactId>
<version>2.3.0version>
dependency>
dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-dependenciesartifactId>
<version>${spring-cloud.version}version>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
由于Spring Boot 2.0之后官方不再建议自定义zipkin,建议使用官方提供的zipkin.jar包,将springboot升级至2.0后,发现zipkin2使用mysql做日志存储会出错,需要添加以下依赖:
<dependency>
<groupId>org.jooqgroupId>
<artifactId>jooqartifactId>
<version>3.11.4version>
dependency>
另外启动的时候发现,zipkin使用Spring Boot 2.0 默认的数据库连接池hikaricp会有问题,无法启动,这里改成了dbcp2数据库连接池:
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-dbcp2artifactId>
<version>2.3.0version>
dependency>
2.配置文件
server:
port: 8770
spring:
application:
name: chainmonitor
datasource:
url: jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
initialization-mode: always
continue-on-error: true
schema: classpath:/zipkin.sql
dbcp2:
#初始化连接:连接池启动时创建的初始化连接数量
initial-size: 50
#从连接池获取一个连接时,最大的等待时间,连接池会等待N毫秒,等待不到,则抛出异常
max-wait-millis: 60000
#最大空闲连接:连接池中容许保持空闲状态的最大连接数量,超过的空闲连接将被释放,如果设置为负数表示不限制
max-idle: 100
#通过这个池创建连接的默认自动提交状态。如果不设置,则setAutoCommit 方法将不被调用
default-auto-commit: true
#通过这个池创建连接的默认只读状态
default-read-only: false
#指明在从池中租借对象时是否要进行验证有效,如果对象验证失败,则对象将从池子释放,然后我们将尝试租借另一个
test-on-borrow: true
type: org.apache.commons.dbcp2.BasicDataSource
jpa:
database: mysql
show-sql: true
hibernate:
ddl-auto: update
properties:
hibernate:
dialect: org.hibernate.dialect.MySQL5Dialect
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
management:
metrics:
web:
server:
auto-time-requests: false
zipkin:
storage:
type: mysql
zipkin持久化数据需要建立三张表用于存储数据,这三张表会在服务启动的时候创建。其中
spring:
datasource:
schema: classpath:/zipkin.sql
指定创建表的语句在资源文件夹下。
3.sql语句
CREATE TABLE IF NOT EXISTS zipkin_spans ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL, `id` BIGINT NOT NULL, `name` VARCHAR(255) NOT NULL, `parent_id` BIGINT, `debug` BIT(1), `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate'; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations'; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds'; ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames'; ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range'; CREATE TABLE IF NOT EXISTS zipkin_annotations ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds'; ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames'; ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces'; ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job'; CREATE TABLE IF NOT EXISTS zipkin_dependencies ( `day` DATE NOT NULL, `parent` VARCHAR(255) NOT NULL, `child` VARCHAR(255) NOT NULL, `call_count` BIGINT, `error_count` BIGINT ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`); 4. 测试
- 依次启动服务:eureka->provider->consumer->chainMonitor,此时发现数据库已经创建了三张表,并且chainMonitor访问正常
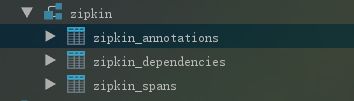
- 访问provider或consumer服务,表中插入了数据

- 重启chainMonitor服务,可以查询到链路数据,持久化成功
github下载示例代码