Mysql InnoDB索引原理
Mysql InnoDB索引原理

索引这个概念说出来好像大家都知道,但是又有多少人能说出个所以然来呢?
本文的目的希望让读者能够掌握索引的基本概念,做到知其然也知其所以然,接下来笔者将从以下两个角度为你阐述Mysql索引。
何为索引
使用索引的正确姿势
Mysql索引是什么
A data structure that provides a fast lookup capability for rows of a table, typically by forming a tree structure (B-tree) representing all the values of a particular column or set of columns.
—引用自mysql官方文档
简单来说索引是一种数据结构(通常是树结构B-tree),这个数据结构中存放着特定的列或列集,以提供快速的查找功能。
举一个例子来帮助大家理解,图书的目录,目录即索引,读者根据你想要查看的内容(索引),从目录中找到对应的页码(数据指针),定位到最终内容。
索引类型
Mysql的索引由储存引擎实现,不同的储存引擎支持的索引可能会不一样,本文只讲解最常见的索引类型B-Tree索引(这里的B是Balance的缩写)。
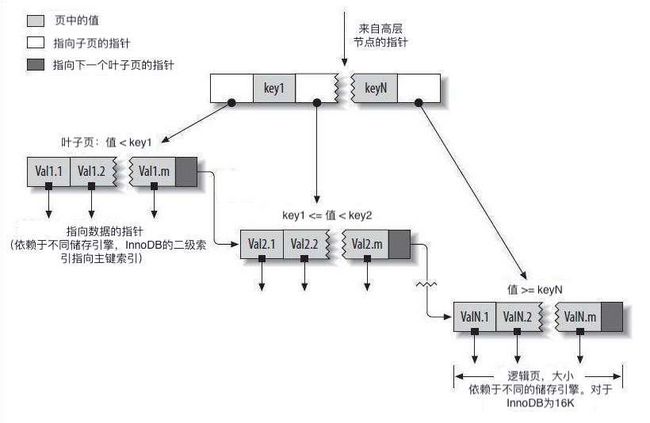
B-Tree由根节点(图中未画出)、普通节点和叶子节点构成,普通节点存放指向下一节点的指针,具体指向数据的指针则存放在叶子结点中(所有叶子结点都在最后一层)。
B-Tree索引之所以能够加快数据的访问速度,是因为在查找数据时不需要去一行行的查找并比较数据(全表扫描),而是从树的根节点开始比较查找,根据要查找的值一级一级的去比较节点页的值拿到下级指针(定义了子节点中值的上限和下限),最终找到索引所在的叶子页并拿到数据指针。
聚簇索引
实际上不是一种索引类型,其本质就是B-Tree索引,区别在于其叶子节点的存放的数据,叶子节点将不会存放指向数据的指针,而是直接存放数据行即每个叶子节点就是一行数据,即聚簇索引是InnoDB真正储存数据的地方。
InnoDB通过主键来聚集数据,默认聚簇索引索引的列为主键,如果没有定义主键,InnoDB会选择一个默认的非空索引代替,如果没有这样的索引,InnoDB会隐式的定义一个主键作为聚簇索引。
二级索引
可以理解为普通的B-Tree索引,非聚簇索引,这里唯一要明确的一点是二级索引叶子节点中储存的“行指针”其本质是主键,即聚簇索引中的键。所以当使用二级索引查询时需要进行二次查询,先从二级索引获取主键,再使用主键从聚簇索引中获取数据行(这里排除覆盖索引的情况)。
简单的例子
看了上面的聚簇索引和二级索引,相信很多读者还是存在一定的认知模糊,下面通过一个《高性能Mysql》中关于InnoDB数据分布的例子来帮助大家,更好的认识聚簇索引和二级索引究竟如何工作。
下面是这个例子的表结构,layout_test表中有两个int类型字段,其中col1列作为主键,同时为col2列生成普通索引。
CREATE TABLE layout_test (
col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
);
layout_test表的聚簇索引部分
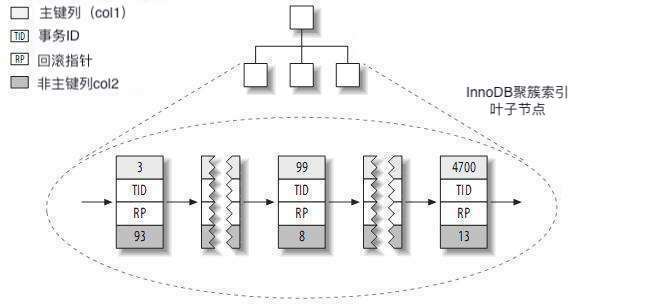
简单讲解一下上图:
1.首先大家可以先忽略其中的事务ID和回滚指针,因为这和理解索引部分暂时没有关系,有兴趣的读者可以另行了解。
2.上图只是包含了聚簇索引的叶子节点部分,可以看到叶子节点中并没有储存数据指针,而是储存了主键col1和剩下的列col2,即每一个叶子节点我们可以理解成一条数据记录。比如第一个节点:主键列col1值为3、剩余列col2值为93其包含了这条记录的所有数据。
3.这里我想吐槽一下这个例子,其实蛮容易让人误解的,如果再新增一个col3列的话,其实能更方便的将聚簇索引和二级索引区分开来,这里我们假设有col3,那么上图的每个叶子节点都将多一个col3列的值。
**layout_test表的二级索引col2**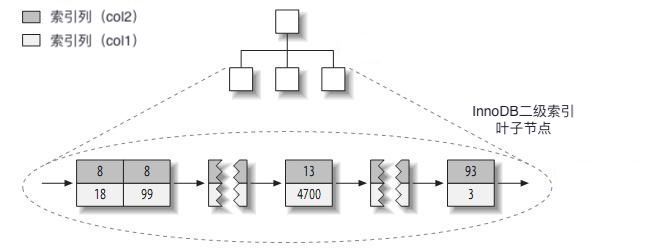
1.图1-3很简单也很好理解,这里简单说明一下,二级索引中每个叶子节点存放了两种数据,分别是索引键即col2,和主键col1。上图最后一个叶子节点:93是col2的值,3则是主键col1。
2.这里还是跟上面一样,如果表layout_test还有个col3列,上图不会有任何的变化,二级索引每个叶子节点只会存储索引键和主键。
借助上面的例子,用两个分别以col1和col2字段作为查询条件的SQL,为大家演示InnoDB的聚簇索引是如何工作的。
#以col1作为查询条件
SELECT col1, col2, col3 FROM layout_test WHERE col1 = 3;
#以col2作为查询条件
SELECT col1, col2, col3 FROM layout_test WHERE col2 = 93;
为了防止“覆盖索引”让大家引起歧义,这里假设还有一个col3字段。
**第一条SQL执行:**根据主键col1 = 3,查询引擎会直接在聚簇索引中找到键为3的叶子节点。即图1-2的第一个叶子节点,其中包含了键col1,和剩余的字段col2和col3。
**第二条SQL执行:**根据主键col2 = 93,查询引擎会从二级索引中查找键为93的叶子节点。即图1-3中的最后一个叶子节点,从中拿到主键3,然后再根据主键从聚簇索引中查找。即二次查询。(这里解释一下为什么需要假设一个字段col3,因为如果只有两个字段的话,其实只要查一次二级索引就可以拿到所有数据了,二级索引中已经包含了键col2和主键col1,这就是覆盖索引可以加速查询的道理,因为不需要再去查一遍聚簇索引,性能自然高)
写在最后
索引这个概念,细讲可能花一本书版本都讲不完,如何正确使用索引就留在下一篇跟大家分享。这里只是很粗浅的跟大家介绍了关于InnoDB索引的概念,目的是让不熟悉索引这块知识的读者,对其有个大体的概念。对于有兴趣深入了解的读者,强烈推荐《高性能Mysql》这本书,本文的大多数观点也是来源于此。
碍于笔者所学有限,本文如有表述不当处欢迎于留言中指出。
参考材料
1.《高性能Mysql》
2. [mysql开发手册](https://dev.mysql.com/doc/