好理解的Java内存虚假共享(False Sharing)性能损耗以及解决方案
虚假共享(False Sharing)也有人翻译为伪共享
参考 https://en.wikipedia.org/wiki/False_sharing
在计算机科学中,虚假共享是一种性能降低的使用模式,它可能出现在具有由高速缓存机制管理的最小资源块大小的分布式一致高速缓存的系统中。当系统参与者将定期尝试访问,将永远不会被另一方改变数据,但这些数据共享与数据的高速缓存块被修改,缓存协议可能迫使一位与会者尽管缺乏逻辑必然性的整个单元重载。高速缓存系统不知道该块内的活动,并迫使第一个参与者承担真正共享资源访问所需的高速缓存系统开销。
到目前为止,该术语最常见的用法是在现代多处理器 CPU高速缓存中,其中存储器被缓存在两个字大小的一些小功率的行中(例如,64个对齐的,连续的字节)。如果两个处理器对可存储在一行中的同一存储器地址区域中的独立数据进行操作,则系统中的高速缓存一致性机制可能会在每次数据写入时强制整个线路穿过总线或互连,从而除了浪费系统带宽之外还会导致内存停顿 。虚假共享是自动同步的缓存协议的固有工件,也可以存在于分布式文件系统或数据库等环境中,但目前的流行仅限于RAM缓存。
示例
struct foo {
int x;
int y;
};
static struct foo f;
/* The two following functions are running concurrently: */
int sum_a(void)
{
int s = 0;
for (int i = 0; i < 1000000; ++i)
s += f.x;
return s;
}
void inc_b(void)
{
for (int i = 0; i < 1000000; ++i)
++f.y;
}在这里,sum_a可能需要不断地从主存储器(而不是从缓存)重新读取x,即使inc_b并发修改y是无关紧要的。
如果你还是不能理解虚假共享不要紧看下面的例子
理解虚假分享
为了更好地理解这一点,我们假设一个假设的情况:
有三位画家。每个人都有他自己的木板,他们在上面绘画,每个板有三个部门,分别是1区,2区和3区。
画家只能画出这三个部门中的一个。当画家描绘他的木板的一个部分时,另外两个板也必须改变以反映第一个画家所做的事情。
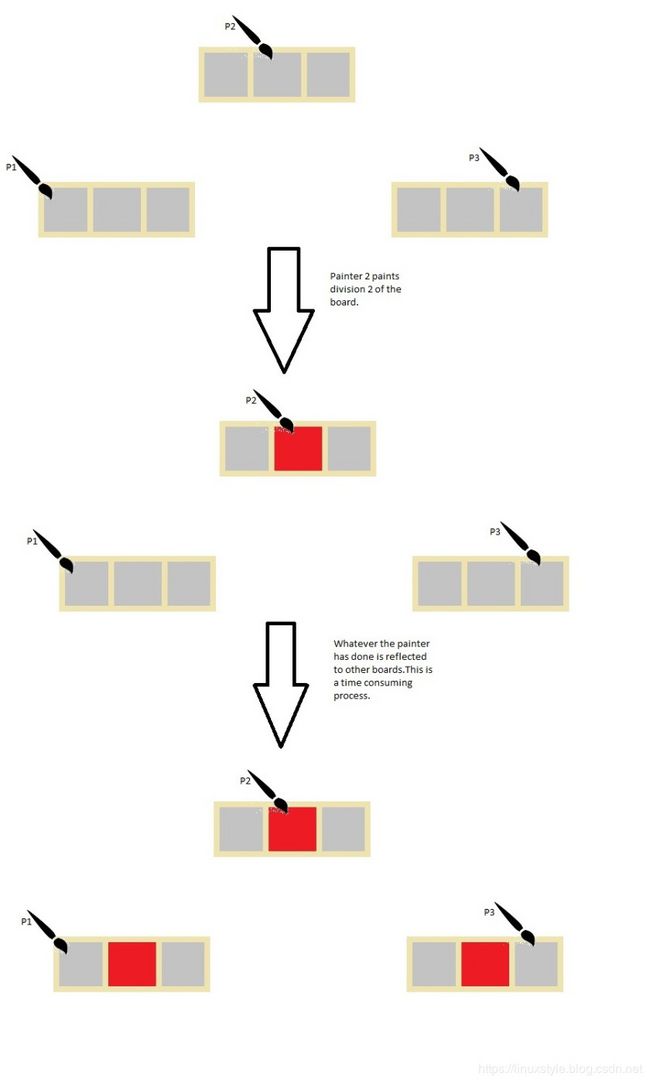
这里的木板类似于缓存块,画家类似于并发线程,绘画类似于写入活动。
请记住,此更新在逻辑上是不必要的,因为每个画家使用的分区不与其他画家使用的分区相交。可以做的是在所有画家完成绘画之后,最后可以更新木板。但这不是我们的计算机架构的工作方式。这是因为管理高速缓存机制的组件不知道实际更新了高速缓存块的哪个分区。它标记整个块为脏。强制内存更新以维持缓存一致性。与高速缓存块中的写入活动相比,这是非常昂贵的计算。
只有当写入进程和两个并行线程具有交叉缓存块时才会出现此问题。现在解决此问题的唯一方法是确保两个并行线程具有不同的缓存块。
参考:虚假分享
要实现线程数量的线性可伸缩性,我们必须确保没有两个线程同时写入同一个变量或缓存行。可以在代码级别跟踪写入同一变量的两个线程。为了能够知道自变量是否共享相同的缓存行,我们需要知道内存布局,或者我们可以使用工具告诉我们。英特尔VTune就是这样一个分析工具。下面,将解释如何为Java对象布置内存以及如何填充缓存行以避免错误共享。
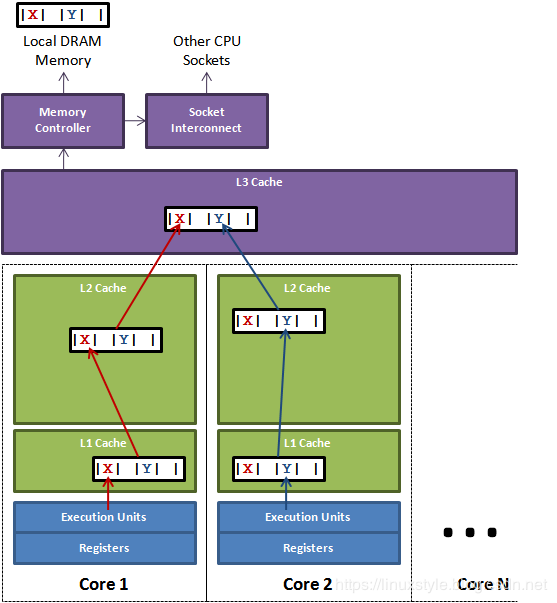
上图演示虚假共享的问题。
在核心1(Core1)上运行的线程想要更新变量X,而核心2(Core2)上的线程想要更新变量Y。
不幸的是,这两个变量位于同一缓存行中。每个线程都将竞争对缓存行的所有权,以便可以更新。如果核心1获得所有权,那么缓存子系统将需要使核心2的相应缓存行置为无效。当Core 2获得所有权并执行其更新时,将告知核心1使其缓存行的副本无效。这将通过L3缓存来回乒乓,会极大的影响性能。如果竞争核心在不同的套接字上并且还必须跨越套接字互连,那么将进一步加剧性能问题。
Java内存布局
对于基于Hotspot的JVM比如现在的OpenJDK和OracleJDK,所有对象都有一个2个字的header。首先是“标记(mark)”字,其由用于散列码的24位和用于诸如锁定状态的标志的8位组成,或者它可以被交换用于锁定对象。第二个是对象类的引用。数组有一个额外的单词,用于表示数组的大小。为了提高性能,每个对象都与8字节的粒度边界对齐。因此,为了在打包时有效,根据大小(以字节为单位)将对象字段从声明顺序重新排序为以下顺序:
doubles (8) and longs (8)
ints (4) and floats (4)
shorts (2) and chars (2)
booleans (1) and bytes (1)
references (4/8)
重复子类字段 有了这些知识,我们可以在7个长度的任何字段之间填充缓存行。为了显示性能影响,让我们花几个线程来更新自己独立的计数器。这些计数器将长期波动,可以看到它们的比较数据。
package linuxstyle.blog.csdn.net;
public final class FalseSharing implements Runnable {
public final static long ITERATIONS = 500L * 1000L * 1000L;
public final static int NUM_THREADS = 4; // change
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static {
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
}
private final int arrayIndex;
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong {
public long p1, p2, p3, p4, p5, p6; // comment out
public volatile long value = 0L;
}
}
输出如下:
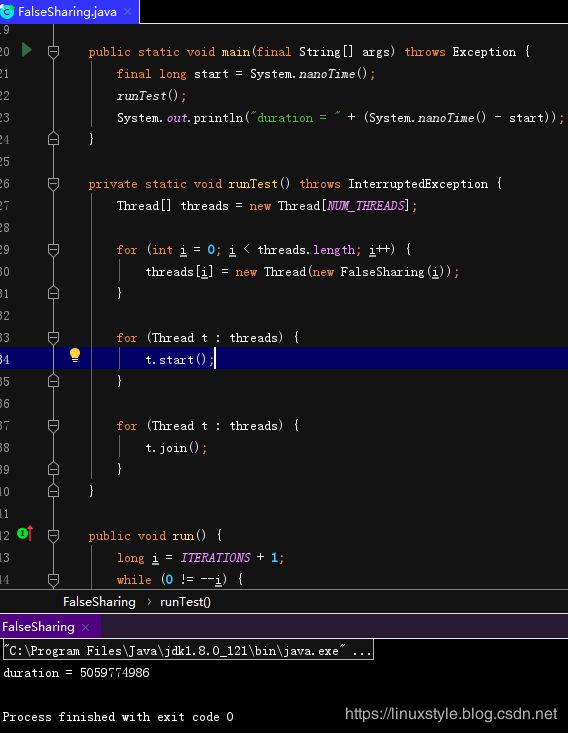
结果
运行上面的代码,同时增加线程数并添加/删除缓存行填充,得到如下图所示的结果。这是测量4核测试运行的持续时间。
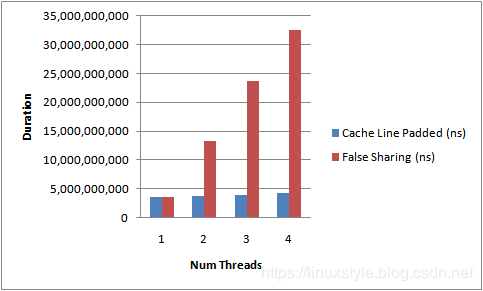
通过增加完成测试所需的执行时间可以清楚地看出错误共享的影响。如果没有缓存行争用,我们就可以通过线程实现近似线性扩展。
这不是一个完美的测试,因为我们无法确定VolatileLongs将在内存中的位置。它们是独立的对象。但是经验表明,同时分配的对象往往位于同一位置。
需要注意的是上面的解决办法是有争议的参考:知道你的Java对象内存布局
理论上,理论和实践是相同的
这是几年前的一篇优秀文章,它告诉大家Java应该如何布局你的对象,总结一下:
- 对象在内存中对齐8个字节(如果A%K == 0,则地址A为K对齐)
- 所有字段都是类型对齐的(long / double是8对齐,整数/ float 4,short / char 2)
- 字段按其大小的顺序打包,除了最后的引用
- 类字段永远不会混合,所以如果B扩展A,B类的对象将首先在A的字段中布局在内存中,然后是B的
- 子类字段以4字节对齐开始
- 如果类的第一个字段是long / double并且类起始点(在标题之后,或者在super之后)不是8对齐,则可以交换较小的字段以填充4字节间隙。
JVM不仅仅按照你告诉它的顺序依次对你的字段进行plok的原因也在文章中讨论,总结如下:
- 未对齐访问是不好的,因此JVM可以避免错误的布局(对内存的未对齐访问会导致各种不良副作用,包括在某些体系结构上崩溃您的进程)
- 字段的朴素布局会浪费内存,JVM重新排序字段以改善对象的整体大小
- JVM实现要求类型具有一致的布局,因此需要子类规则
那么......很好的明确规则,可能会出错?
https://gist.github.com/nitsanw/5594570#file-gistfile1-java
首先,规则不是JLS的一部分,它们只是实现细节。如果您阅读Martin Thompson关于虚假共享的文章, 您会注意到T先生有一个错误共享的解决方案,该解决方案适用于JDK 6,但不再适用于JDK 7.以下是两个版本。
下面是避免在JDK 6/7上进行错误共享:
// No false sharing on 6, but happens on 7
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6;
}
// No false sharing on 6 or 7
public static class PaddedAtomicLong extends AtomicLong
{
public volatile long p1, p2, p3, p4, p5, p6 = 7L;
}事实证明,JVM改变了它对6到7之间的字段进行排序的方式,这足以打破这个咒语。公平地说,没有上面规定的规则要求字段顺序与它们被定义的顺序相关联,但是......它需要担心并且它可以让你绊倒。
正如上述规则在我的脑海中仍然是新鲜的,LMAX 开源的Disruptor发布了Coalescing Ring Buffer。我仔细阅读了代码并发现以下内容:
public final class CoalescingRingBuffer implements CoalescingBuffer {
private volatile long nextWrite = 1; // <-- producer access (my comment)
private volatile long lastCleaned = 0; // <-- producer access (my comment)
private volatile long rejectionCount = 0;
private final K[] keys;
private final AtomicReferenceArray values;
private final K nonCollapsibleKey = (K) new Object();
private final int mask;
private final int capacity;
private volatile long nextRead = 1; // <-- consumer access (my comment)
private volatile long lastRead = 0; // <-- consumer access (my comment)
...
} 在介绍CoalescingRingBuffer的博客文章中找到了Nick Zeeb, 并提出了担忧,即生产者/消费者访问的字段可能会遭受错误的共享,Nick的回复:
试图对字段进行排序,以便最大限度地减少错误共享的风险。Java 7可以重新排序字段。使用Martin Thompson的PaddedAtomicLong进行了性能测试,但没有在Java 7上获得性能提升。
尼克很聪明,并不是在这里引用这些用来来批评他。引用他来表明这是令人困惑的东西(所以在某种程度上,我引用他来安慰自己与其他同样困惑的专业人士的公司)。我们怎么知道?这是我和尼克交谈后想到的一种方式:
public class FalseSharingTest {
@Test
public void test() throws NoSuchFieldException, SecurityException{
long nextWriteOffset = UnsafeAccess.unsafe.objectFieldOffset(
CoalescingRingBuffer.class.getDeclaredField("nextWrite"));
long lastReadOffset = UnsafeAccess.unsafe.objectFieldOffset(
CoalescingRingBuffer.class.getDeclaredField("lastRead"));
assertTrue(Math.abs(nextWriteOffset - lastReadOffset) >= 64);
}
}使用Unsafe我可以从对象引用中获取字段偏移量,如果2个字段小于高速缓存行,则它们可能遭受错误共享(取决于内存中的结束位置)。当然,这是验证事物的一种hackish方式,但它可以成为您构建的一部分。
热门
大约在同一时间LMAX发布了CoalescingRingBuffer,Gil Tene(Azul的CTO)发布了HdrHistogram。现在Gil非常认真,非常聪明,并且比大多数人更了解JVM(这是他的InfoQ演讲,观看它)所以我很想看看他的代码。你知道什么,一堆热门领域:
public abstract class AbstractHistogram implements Serializable {
// "Cold" accessed fields. Not used in the recording code path:
long highestTrackableValue;
int numberOfSignificantValueDigits;
int bucketCount;
int subBucketCount;
int countsArrayLength;
HistogramData histogramData;
// Bunch "Hot" accessed fields (used in the the value recording code path) here, near the end, so
// that they will have a good chance of ending up in the same cache line as the counts array reference
// field that subclass implementations will add.
int subBucketHalfCountMagnitude;
int subBucketHalfCount;
long subBucketMask;
...
}Gil在这里做的很好,他试图让相关领域在内存中挤在一起,这将提高他们在同一缓存行上结束的可能性,从而为CPU节省潜在的缓存。可悲的是,JVM还有其他计划......
所以这里有另一个工具可以帮助你理解你的内存布局,以便添加到你的工具带中:Java Object Layout 我偶然碰到了它,而不是一直想着内存布局。
注意histogramData如何跳转到botton并且subBucketMask被移到顶部,打破了我们的热门束。解决方案是丑陋但有效的,将所有字段移动到另一个毫无意义的父类:
abstract class AbstractHistogramColdFields implements Serializable {
// "Cold" accessed fields. Not used in the recording code path:
long highestTrackableValue;
int numberOfSignificantValueDigits;
int bucketCount;
int subBucketCount;
int countsArrayLength;
HistogramData histogramData;
}
public abstract class AbstractHistogram extends AbstractHistogramColdFields {
// Bunch "Hot" accessed fields (used in the the value recording code path) here, near the end, so
// that they will have a good chance of ending up in the same cache line as the counts array reference
// field that subclass implementations will add.
int subBucketHalfCountMagnitude;
int subBucketHalfCount;
long subBucketMask;
...
}优秀的JOL现已在OpenJDK下发布。它甚至比以前更好,并支持许多时髦的功能。
http://openjdk.java.net/projects/code-tools/jol/
代码工具:jol
JOL(Java Object Layout)是分析JVM中对象布局方案的微型工具箱。这些工具大量使用Unsafe,JVMTI和Serviceability Agent(SA)来解码实际的 对象布局,占用空间和引用。这使得JOL比依赖堆转储,规范假设等的其他工具更准确。
参考:
- 易于理解虚假分享
- C ++今日博客,虚假分享再次点击!
- Dobbs博士的文章:消除虚假分享
- 在尝试消除Java中的错误共享时要小心
- Bolosky,WJ和Scott,ML 1993. 虚假共享及其对共享内存性能的影响