从0开始搭建完整的电影推荐系统网站一(Python+Django)
读研这么久搞了不少推荐算法相关的东西,但重心都放在算法研究和实现上了。所以一直想做一个完整的带有人机交互的推荐网站,可惜的是之前能找到的资料都是JAVA WEB,对环境要求高,而且用的技术栈太多,相当繁琐,导致一直没有成功。最近终于在网上看到一本神书《Practical Recommender Systems; Kim Falk;January 2019》。不仅有算法,还有前后端实现。所以,中央决定了,就让我来写个利用Django做WEB框架的电影推荐系统。(PYTHON3+DJANGO)
一.项目整体结构
1.Main Page(主页)
- 卡牌式展示电影的区域
- 每个电影的详情介绍
- 要有个人推荐功能
- 要有基于电影类型分类的列表
2.详情页
- 电影海报
- 电影描述
- 电影评分
3.类别页
- 有和主页一样的结构
- 基于类别的专门的推荐

具体来说,MovieGEEKS是前端交互用的。Analytics是连接作用,监控其他部分,后面再说。collector是用来收集用户信息的(收集隐私的,哈哈哈),数据放到evidence数据库中。Recs是核心,提供推荐给网站。Recommendation builder是预先计算的推荐(离线推荐?暂时这么翻译吧)。大概主页长这样: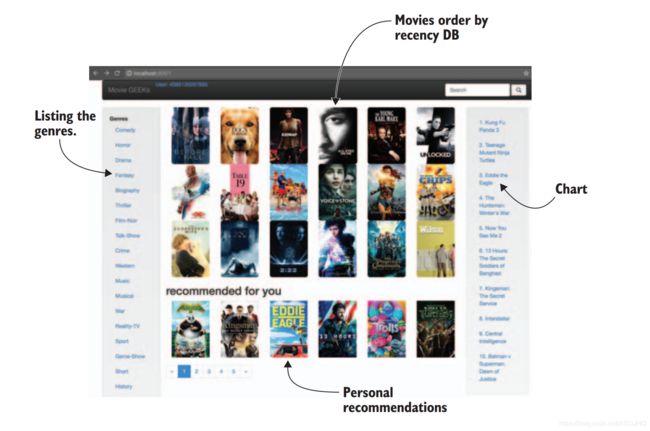
好!到此大概对整体框架有个感觉了。
二. 创建项目
我用Pycharm先创建一个Django项目,起名为MovieAngelSite


三. 创建应用
创建app,movieangel
在terminal里输入:
python manage.py startapp movieangel
四. 定义模型类
- 有一个数据表,就有一个模型类与之对应
- 打开models.py文件,定义模型类
- 引入包from django.db import models
- 模型类继承自models.Model类
- 说明:不需要定义主键列,在生成时会自动添加,并且值为自动增长
- 当输出对象时,会调用对象的str方法
- 自动生成的表名为app名和模型的小写名称的组合(用下划线_组合)
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
from django.db import models
# Create your models here.
class Genre(models.Model):
name = models.CharField(max_length=64)
def __str__(self):
return self.name
class Movie(models.Model):
movie_id = models.CharField(max_length=16, unique=True, primary_key=True)
title = models.CharField(max_length=128)
year = models.IntegerField(null=True)
genres = models.ManyToManyField(Genre, related_name='movies', db_table='movie_genre')
def __str__(self):
return self.title
五. 生成数据表
- 激活模型:编辑settings.py文件,将movieangel应用加入到installed_apps中
- 修改USE_TZ = False

- 生成迁移文件:根据模型类生成sql语句
python manage.py makemigrations
- 执行迁移:执行sql语句生成数据表
python manage.py migrate
六. 视图
- 在django中,视图对WEB请求进行回应
- 视图接收reqeust对象作为第一个参数,包含了请求的信息
- 视图就是一个Python函数,被定义在views.py中
首先,去https://www.themoviedb.org/account/signup这个网站注册下,拿到自己的api_key。 然后再文件根目录下,创建文件.prs,在里面加上
{ "themoviedb_apikey": "你的API_KEY"}
注意要加上“ ”双引号。
接着,在movieangel的views.py里加上
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import uuid, random
import json
from django.shortcuts import render
from django.views.decorators.csrf import ensure_csrf_cookie
from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger
from movieangel.models import Movie, Genre
# Create your views here.
# 默认首页
@ensure_csrf_cookie
def index(request):
genre_selected = request.GET.get('genre')
api_key = get_api_key()
if genre_selected:
selected = Genre.objects.filter(name=genre_selected)[0]
movies = selected.movies.order_by('-year', 'movie_id')
else:
movies = Movie.objects.order_by('-year', 'movie_id')
genres = get_genres()
page_number = request.GET.get("page", 1)
page, page_end, page_start = handle_pagination(movies, page_number)
context_dict = {'movies': page,
'genres': genres,
'api_key': api_key,
'session_id': session_id(request),
'user_id': user_id(request),
'pages': range(page_start, page_end),
}
return render(request, 'movieangel/index.html', context_dict)
# 分页
def handle_pagination(movies, page_number):
paginate_by = 18
paginator = Paginator(movies, paginate_by)
try:
page = paginator.page(page_number)
except PageNotAnInteger:
page_number = 1
page = paginator.page(page_number)
except EmptyPage:
page = paginator.page(paginator.num_pages)
page_number = int(page_number)
page_start = 1 if page_number < 5 else page_number - 3
page_end = 6 if page_number < 5 else page_number + 2
return page, page_end, page_start
# 获得API_KEY
def get_api_key():
# Load credentials
cred = json.loads(open(".prs").read())
return cred['themoviedb_apikey']
# 获得所有电影类型名
def get_genres():
return Genre.objects.all().values('name').distinct()
# 设置session_id
def session_id(request):
if not "session_id" in request.session:
request.session["session_id"] = str(uuid.uuid1())
return request.session["session_id"]
# 设置usr_id,没有就随机出来一个
def user_id(request):
user_id = request.GET.get("user_id")
if user_id:
request.session['user_id'] = user_id
if not "user_id" in request.session:
request.session['user_id'] = random.randint(10000000000, 90000000000)
print("ensured id: ", request.session['user_id'])
return request.session['user_id']
配置URLconf
- 在Django中,定义URLconf包括正则表达式、视图两部分
- Django使用正则表达式匹配请求的URL,一旦匹配成功,则调用应用的视图
- 注意:只匹配路径部分,即除去域名、参数后的字符串
- 在MovieAngelSite/urls.py修改为
from django.conf.urls import url,include
from django.contrib import admin
from movieangel import views
urlpatterns = [
url(r'^$', views.index, name='index'),
url(r'^movies/', include('movieangel.urls')),
url(r'^admin/', admin.site.urls),
]
加入模板
- 模板是html页面,可以根据视图中传递的数据填充值
- 创建模板的目录,static目录

- 修改settings.py文件
加入
TEMPLATE_DIR = os.path.join(BASE_DIR, 'templates')
STATIC_DIR = os.path.join(BASE_DIR, 'static')
修改
'DIRS': [TEMPLATE_DIR, ],
增加
STATICFILES_DIRS = [STATIC_DIR, ]
修改base.html
{% load staticfiles %}
MovieGEEKs
{% block head %}{% endblock head %}
{% block content %}{% endblock content %}
增加detail.html
{% extends "movieangel/base.html" %}
{% block content %}
![movie poster]() Released:
Description:
Language
Average rating
Genres
Released:
Description:
Language
Average rating
Genres
{% if movie_genres %}
| {% for genre in movie_genres %}
{{ genre.name}} |
{% endfor %}
{% endif %}
Frequently bought with these
Similar content
{% endblock content %}
增加index.html
{% extends "movieangel/base.html" %}
{% block content %}
![movie poster]() Released:
Description:
Language
Average rating
Genres
Released:
Description:
Language
Average rating
Genres
{% if movie_genres %}
| {% for genre in movie_genres %}
{{ genre.name}} |
{% endfor %}
{% endif %}
Frequently bought with these
Similar content
{% endblock content %}
增加search_result.html
{% extends "movieangel/base.html" %}
{% block head %}
{% endblock head %}
{% block content %}
{% if movies|length > 0 %}
{% else %}
No movies found
{% endif%}
{% endblock content %}
增加collector.js,这个作用和面章节会说
function add_impression(user_id, event_type, content_id, session_id, csrf_token) {
$.ajax({
type: 'POST',
url: '/collect/log/',
data: {
"csrfmiddlewaretoken": csrf_token,
"event_type": event_type,
"user_id": user_id,
"content_id": content_id,
"session_id": session_id
},
fail: function(){
console.log('log failed(' + event_type + ')')
}
})};
最后,在目录下加入:

这两个文件。
import os
import urllib.request
from tqdm import tqdm
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MovieAngelSite.settings')
import django
django.setup()
from movieangel.models import Movie, Genre
def create_movie(movie_id, title, genres):
movie = Movie.objects.get_or_create(movie_id=movie_id)[0]
title_and_year = title.split(sep="(")
movie.title = title_and_year[0]
movie.year = title_and_year[1][:-1]
if genres:
for genre in genres.split(sep="|"):
g = Genre.objects.get_or_create(name=genre)[0]
movie.genres.add(g)
g.save()
movie.save()
return movie
def download_movies():
URL = 'https://raw.githubusercontent.com/sidooms/MovieTweetings/master/latest/movies.dat'
response = urllib.request.urlopen(URL)
data = response.read()
return data.decode('utf-8')
def delete_db():
print('truncate db')
Movie.objects.all().delete()
Genre.objects.all().delete()
print('finished truncate db')
def populate():
movies = download_movies()
print('movie data downloaded')
for movie in tqdm(movies.split(sep="\n")):
m = movie.split(sep="::")
if len(m) == 3:
create_movie(m[0], m[1], m[2])
if __name__ == '__main__':
print("Starting MovieGeeks Population script...")
delete_db()
populate()
就发这个代码吧,populate_movieangel.py的
这样初步的代码差不多都有了,我们先run一下populate_movieangel,这样所有电影数据就有了,接着在terminal里打,python manage.py runserver,就可以看到网站了~
第一章开篇就这样了~后面几章在代码上不会再这么细了,有兴趣的看看github好了~