Verilog流水线CPU设计(超详细)
上篇:Verilog单周期CPU设计(超详细)
本篇完整工程下载链接
实验 流水线CPU
- 一、设计目的与要求
- 1.1 实验内容
- 1.2 实验要求
- 1.3 实验创新
- 二、课程设计器材
- 2.1 硬件平台
- 2.2 软件平台
- 三、CPU逻辑设计总体方案
- 3.1 数据通路
- 3.2 MIPS指令格式
- 3.3 流水线CPU结构设计图
- 3.4 流水线CPU逻辑流程图
- 3.5 变量命名
- 四、冒险解决策略
- 4.1 数据冒险
- 4.1.1 寄存器堆的写操作提前半个时钟周期
- 4.1.2内部前推
- 4.1.3 lw指令的数据冒险
- 4.2 控制冒险
- 4.2.1 缩短分支的延迟
- 五、 模块详细设计
- 5.1取指令部分(IF)
- 5.1.1 PCAdd4
- 5.1.2 PC
- 5.1.3 INSTMEM
- 5.1.4 MUX4X32
- 5.1.5 REG_ifid
- 5.2指令译码部分(ID)
- 5.2.1 CONUNIT
- 5.2.2 MUX2X5
- 5.2.3 EXT16T32
- 5.2.4 REGFILE
- 5.2.5 REG_idex
- 5.3 执行部分(EX)
- 5.3.1 SHIFTER32_L2
- 5.3.2 MUX4X32
- 5.3.3 MUX2X32
- 5.3.4 ALU
- 5.3.5 CLA_32
- 5.3.6 REG_exmem
- 5.4存储器访问部分(MEM)
- 5.4.1 DATAMEMß
- 5.4.2 REG_memwb
- 5.5寄存器堆写回部分(WB)
- 5.5.1 MUX2X32
- 5.6 顶层模块
- 5.7 仿真模块
- 六、 仿真模拟分析
- 6.1 仿真波形图
- 6.2 指令代码分析
- 6.3阻塞分析
- 七、 结论和体会
- 7.1体会感悟
- 7.2对本实验过程及方法、手段的改进建议
- PS
一、设计目的与要求
1.1 实验内容
- 本实例所设计CPU的指令格式的拟定。
- 基本功能部件的设计与实现。
- CPU各主要功能部件的设计与实现。
- CPU的封装。
- 了解提高CPU性能的方法。
- 掌握流水线MIPS微处理器的工作原理。
- 理解数据冒险、控制冒险的概念以及流水线冲突的解决方法。
- 掌握流水线MIPS微处理器的测试方法。
1.2 实验要求
- 至少支持add、sub、and、or、addi、andi、ori、lw、sw、beq、bne十一条指令。
- 采用5级流水线技术,具有数据前推机制。
1.3 实验创新
- 寄存器堆的写操作提前半个时钟周期。
- 完成Lw指令的数据冒险的解决。
- 完成控制冒险的解决。
二、课程设计器材
2.1 硬件平台
无
2.2 软件平台
- 操作系统:Win 10。
- 开发平台:Vivado 2017.2。
- 编程语言:VerilogHDL硬件描述语言。
三、CPU逻辑设计总体方案
流水线是数字系统中一种提高系统稳定性和工作速度的方法,广泛应用于高档CPU的架构中。根据MIPS处理器的特点,将整体的处理过程分为取指令(IF)、指令译码(ID)、执行(EX)、存储器访问(MEM)和寄存器会写(WB)五级,对应多周期的五个处理阶段。一个指令的执行需要5个时钟周期,每个时钟周期的上升沿来临时,此指令所代表的一系列数据和控制信息将转移到下一级处理。

图3-1 流水线
3.1 数据通路
(1) IF级:取指令部分。
包括指令储存器和PC寄存器及其更新模块,负责根据PC寄存器的值从指令存储器中取出指令编码和对PC的值进行更新。
(2) ID级:指令译码部分。
根据独处的指令编码形成控制信号和读寄存器堆输出的寄存器的值。
流水线冒险检测也在该级进行,冒险检测电路需要上一条指令的MemRead,即在检测到冒险条件成立时,冒险检测电路产生stall信号清空ID/EX寄存器,插入一个流水线气泡。
(3) EX级:执行部分。
根据指令的编码进行算数或者逻辑运算或者计算条件分支指令的跳转目标地址。
此外LW、SW指令所用的RAM访问地址也是在本级上实现。控制信号有ALUCode、ALUSrcA、ALUScrB和RegDst,根据这些信号确定ALU操作、选择两个ALU操作数A、B,并确定目标寄存器。另外,数据转发也在该级完成。数据转发控制电路产生ForwardA和ForwardB两组控制信号。
(4) MEM级:存储器访问部分。
只有在执行LW、SW指令时才对存储器进行读写,对其他指令只起到一个周期的作用。该级只需存储器写操作允许信号MemWrite。
(5) WB级:寄存器堆写回部分。
该级把指令执行的结果回写到寄存器文件中。
该级设置信号MemtoReg和寄存器写操作允许信号RegWrite,其中MemtoReg决定写入寄存器的数据来自于MEM级上的缓冲值或来自于MEM级上的存储器。


图3.1-1 数据通路
3.2 MIPS指令格式
MIPS指令系统结构有MIPS-32和MIPS-64两种。本实验的MIPS指令选用MIPS-32。以下所说的MIPS指令均指MIPS-32。
MIPS的指令格式为32位。图3-3给出了MIPS指令的3种格式。

图3-2 MIPS指令格式
本实验只选取了11条典型的MIPS指令来描述CPU逻辑电路的设计方法。表3-1列出了本实验的所涉及到的11条MIPS指令。
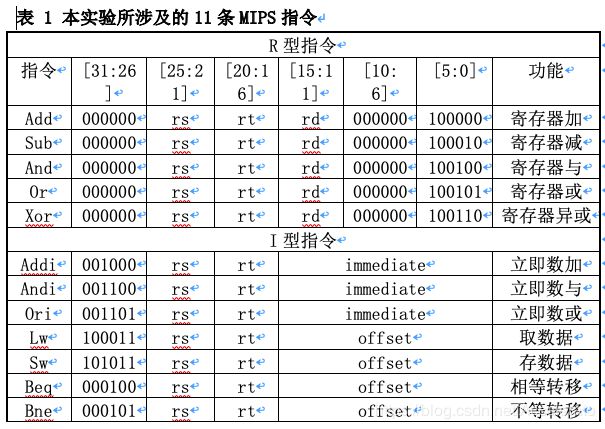
R型指令的op均为0,具体操作由func指定。rs和rt是源寄存器号,rd是目的寄存器号。移位指令中使用sa指定移位位数。
I型指令的低16位是立即数,计算时需扩展到32位,依指令的不同需进行零扩展和符号扩展。
3.3 流水线CPU结构设计图

图3-4 流水线CPU总体结构图
图3-4是一个简单的基本上能够在流水线上完成所要求设计的指令功能的数据通路和必要的控制线路图。其中指令储存在指令储存器,数据储存在数据存储器。而且实现了数据冒险和控制冒险的解决方案。但是此结构仅解决了数据冒险,没有解决控制冒险,若要想解决控制冒险,需要把EX级的移位器和计算分支目标地址的加法器前移到ID。在下文中会给出具体的解决方法。
3.4 流水线CPU逻辑流程图
根据实验原理中的流水线CPU总体结构图,我们可以清楚的知道流水线CPU的设计应包括五级。其中为了运行整个CPU还需要加入一个顶层模块(MAIN)来调用这些模块,所以自然地,这些模块为顶层模块的子模块。设计流程逻辑图如下(左边为流水线寄存器组,右边为各级模块)。
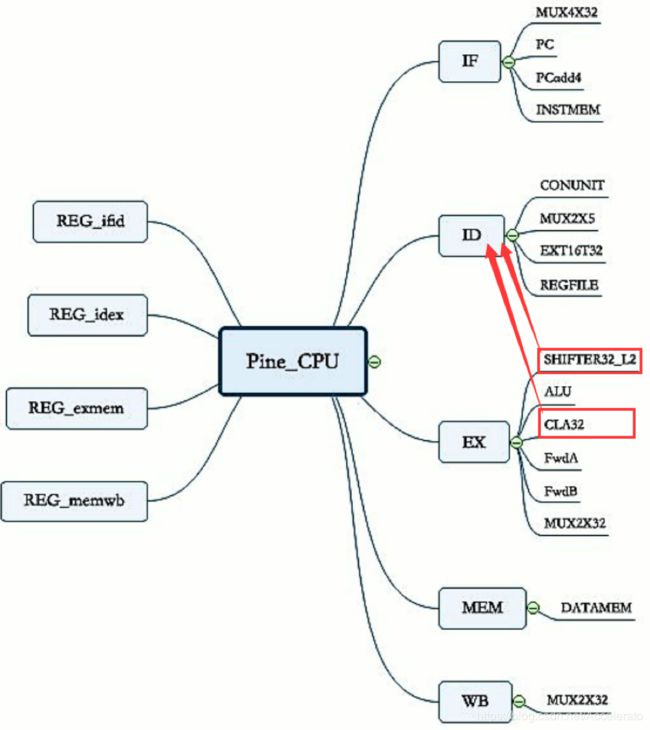
3.5 变量命名
由于在流水线中,数据和控制信息将在时钟周期的上升沿转移到下一级,所以规定流水线转移变量命名为:名称_流水线级名称。
四、冒险解决策略
4.1 数据冒险
在基本流水线中相邻两条指令的前一条指令还没有更新目的寄存器时,后一条指令就已经先读取了该寄存器的旧值,使得指令的计算结果出现错误。这样相关的问题就称为数据冒险。下面给出本实验所使用的解决方法。
4.1.1 寄存器堆的写操作提前半个时钟周期
在未提前半周期时CPU中,指令在时钟周期结束时的上升沿将ID级寄存器的值锁存进ID/EX,或将ALU的计算结果更新寄存器的值。但是寄存器的读、写的操作时间实际上只有时钟周期的一半。因此可以把寄存器堆的写操作提前到时钟周期中间的下降沿完成。那么后半个时钟周期就可以将写入之后的值读出。这样做后,同一级的数据冒险得到解决。
4.1.2内部前推
运算指令的结果在EX级结束时,就已经锁存在EX/MEM的Rd中,然而寄存器的值在ID结束时就已经锁存在ID/EX,但在EX级才真正使用这些值。
所以为了支持内部前推,需在ALU的两个输入端之前,分别增加一个多路选择器和相应的数据通路,并检测处于EX级指令的两个源操作寄存器号是否和处于MEM级或WB级指令的目的寄存器号相等。下面给出检测条件。
- [条件a] E_Rs == EX/MEM.Rd,
判断EX级指令的rs字段是否和MEM级指令的目的寄存器号相同 - [条件b] E_Rs == MEM/WB.Rd,
判断EX级指令的rs字段是否和WB级指令的目的寄存器号相同 - [条件c] (E_Rt == EX/MEM.Rd) & ((E_Inst == I_add) | (E_Inst == I_sub) | (E_Inst == I_and) | (E_Inst == I_or) | (E_Inst == sw) | (E_Inst == beq) | (E_Inst == bne))
判断EX级指令的rt字段是否和MEM级指令的目的寄存器号相同 - [条件d] (E_Rt == MEM/WB.Rd) & ((E_Inst == I_add) | (E_Inst == I_sub) | (E_Inst == I_and) | (E_Inst == I_or) | (E_Inst == sw) | (E_Inst == beq) | (E_Inst == bne))
判断EX级指令的rt字段是否和WB级指令的目的寄存器号相同
同时应该考虑以下几种特殊情况。
- 某些指令可能不写回寄存器,例如sw和beq指令,或者某些指令的写信号被关闭。所以还需检测处于MEM级或WB级指令的寄存器堆写使能信号M_Wreg或W_Wreg是否有效。
- 寄存器$0始终为0,不必考虑在$0上产生的数据冒险,即第三条指令分别与第一条、第二条指令存在数据冒险。按照执行逻辑,当第三条指令处于EX级时应选择处于MEM级的第二条指令的前推。而不能选择第一条前推。所以在判断逻辑模块的代码实现时,应先判断相邻两条指令是否存在数据冒险。
4.1.3 lw指令的数据冒险
内部前推有显而易见的局限性,因为内部前推必须要求前一条指令在EX结束时更新,但是LW指令最早只能在WB级读出寄存器的值。因此无法及时提供给下一条指令的EX级使用。
分析流水线时序图,可以发现lw指令的下一条指令,需要阻塞一个时钟周期,才能确保该指令能获得正确的操作数值,下面给出具体解决方法。
检测是否存在lw指令的数据冒险。
检测单元仍放置于CONUNIT部件内,且Reg2reg信号可以唯一区分lw指令和其他指令。检测条件可写为:
((Rs == E_Rd) | (Rt == E_Rd)) & (E_Reg2reg == 0) & (E_Rd != 0) & (E_Wreg == 1)
暂停流水线的实现:
我们可以通过插入气泡来暂停流水线,也即是关闭PC寄存器和IF/ID流水线寄存器组的写使能信号,而且将ID/EX流水线寄存器组的Clrn端口信号清零。
4.2 控制冒险
在处理beq和bne指令时,条件分支指令或者跳转指令的后续指令有可能在目标地址形成之前或分支条件形成之前就已经进入流水线。这样相关的问题就称为控制冒险。下面给出本实验所使用的解决方法。
4.2.1 缩短分支的延迟
流水线中,尽早完成分支的决策,可以减少性能损失假设图 中M_Z信号和分支目标地址的输出阶段从MEM级前移到EX级,那么图 中(下图)的指令序列只需要被阻塞2个时钟周期就能解决控制冒险因为正确的目标地址在EX级形成,EX级结束时就更新了PC寄存器。
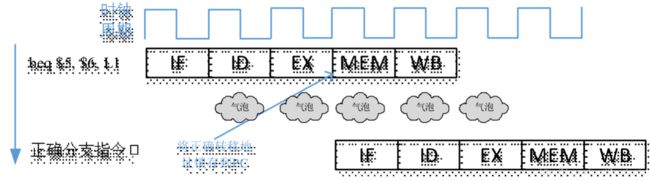
图4.2-1 分支指令
之后通过如下四步解决控制冒险:
- 在条件分支指令处于EX级时,判断分支条件是否成立
- 若成立,则控制部件CONUNIT的STALL端口(流水线阻塞)输出高电平,IF/ID和ID/EX流水线寄存器组的Clrn端口输入为低电平
- 在该时钟周期结束时,IF/ID和ID/EX流水线寄存器组的内容清0,即变为两条空指令
- 这样在下一个时钟周期开始时,正确的目标指令处于IF级,ID级和EX级都是编码为全0的空指令,条件分支指令进入到MEM级
五、 模块详细设计
5.1取指令部分(IF)
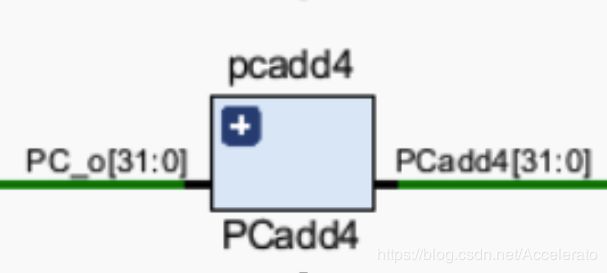
5.1.1 PCAdd4
-
所处位置
-
-
模块功能
作为PC寄存器的更新信号。 -
实现思路
由于每条指令32位,所以增加一个32位加法器,固定与32位的立即数4进行相加,且得到的结果在当前时钟信号的上升沿更新进PC寄存器。 -
引脚及控制信号
IF_Addr:当前指令地址,输入端口(IF内循环)
IF_PCadd4:下一条指令地址,输出端口 -
主要实现代码
1.PCAdd4
module PCadd4(PC_o,PCadd4);
input [31:0] PC_o;//偏移量
output [31:0] PCadd4;//新指令地址
CLA_32 cla32(PC_o,4,0, PCadd4, Cout);
endmodule
1.CLA_32
module CLA_32(X, Y, Cin, S, Cout);
input [31:0] X, Y;
input Cin;
output [31:0] S;
output Cout;
wire Cout0, Cout1, Cout2, Cout3, Cout4, Cout5, Cout6;
CLA_4 add0 (X[3:0], Y[3:0], Cin, S[3:0], Cout0);
CLA_4 add1 (X[7:4], Y[7:4], Cout0, S[7:4], Cout1);
CLA_4 add2 (X[11:8], Y[11:8], Cout1, S[11:8], Cout2);
CLA_4 add3 (X[15:12], Y[15:12], Cout2, S[15:12], Cout3);
CLA_4 add4 (X[19:16], Y[19:16], Cout3, S[19:16], Cout4);
CLA_4 add5 (X[23:20], Y[23:20], Cout4, S[23:20], Cout5);
CLA_4 add6 (X[27:24], Y[27:24], Cout5, S[27:24], Cout6);
CLA_4 add7 (X[31:28], Y[31:28], Cout6, S[31:28], Cout);
Endmodule
1.CLA_4
module CLA_4(X, Y, Cin, S, Cout);
input [3:0] X;
input [3:0] Y;
input Cin;
output [3:0] S;
output Cout;
and get_0_0_0(tmp_0_0_0, X[0], Y[0]);
or get_0_0_1(tmp_0_0_1, X[0], Y[0]);
and get_0_1_0(tmp_0_1_0, X[1], Y[1]);
or get_0_1_1(tmp_0_1_1, X[1], Y[1]);
and get_0_2_0(tmp_0_2_0, X[2], Y[2]);
or get_0_2_1(tmp_0_2_1, X[2], Y[2]);
and get_0_3_0(tmp_0_3_0, X[3], Y[3]);
or get_0_3_1(tmp_0_3_1, X[3], Y[3]);
and get_1_0_0(tmp_1_0_0, ~tmp_0_0_0, tmp_0_0_1);
xor getS0(S0, tmp_1_0_0, Cin);
and get_1_1_0(tmp_1_1_0, ~tmp_0_1_0, tmp_0_1_1);
not get_1_1_1(tmp_1_1_1, tmp_0_0_0);
nand get_1_1_2(tmp_1_1_2, Cin, tmp_0_0_1);
nand get_2_0_0(tmp_2_0_0, tmp_1_1_1, tmp_1_1_2);
xor getS1(S1, tmp_1_1_0, tmp_2_0_0);
and get_1_2_0(tmp_1_2_0, ~tmp_0_2_0, tmp_0_2_1);
not get_1_2_1(tmp_1_2_1, tmp_0_1_0);
nand get_1_2_2(tmp_1_2_2, tmp_0_1_1, tmp_0_0_0);
nand get_1_2_3(tmp_1_2_3, tmp_0_1_1, tmp_0_0_1, Cin);
nand get_2_1_0(tmp_2_1_0, tmp_1_2_1, tmp_1_2_2, tmp_1_2_3);
xor getS2(S2, tmp_1_2_0, tmp_2_1_0);
and get_1_3_0(tmp_1_3_0, ~tmp_0_3_0, tmp_0_3_1);
not get_1_3_1(tmp_1_3_1, tmp_0_2_0);
nand get_1_3_2(tmp_1_3_2, tmp_0_2_1, tmp_0_1_0);
nand get_1_3_3(tmp_1_3_3, tmp_0_2_1, tmp_0_1_1, tmp_0_0_0);
nand get_1_3_4(tmp_1_3_4, tmp_0_2_1, tmp_0_1_1, tmp_0_0_1, Cin);
nand get_2_2_0(tmp_2_2_0, tmp_1_3_1, tmp_1_3_2, tmp_1_3_3, tmp_1_3_4);
xor getS3(S3, tmp_1_3_0, tmp_2_2_0);
not get_1_4_0(tmp_1_4_0, tmp_0_3_0);
nand get_1_4_1(tmp_1_4_1, tmp_0_3_1, tmp_0_2_0);
nand get_1_4_2(tmp_1_4_2, tmp_0_3_1, tmp_0_2_1, tmp_0_1_0);
nand get_1_4_3(tmp_1_4_3, tmp_0_3_1, tmp_0_2_1, tmp_0_1_1, tmp_0_0_0);
nand get_1_4_4(tmp_1_4_4, tmp_0_3_1, tmp_0_2_1, tmp_0_1_1, tmp_0_0_1, Cin);
nand getCout(Cout, tmp_1_4_0, tmp_1_4_1, tmp_1_4_2, tmp_1_4_3,tmp_1_4_4);
assign S = {S3,S2,S1,S0};
endmodule
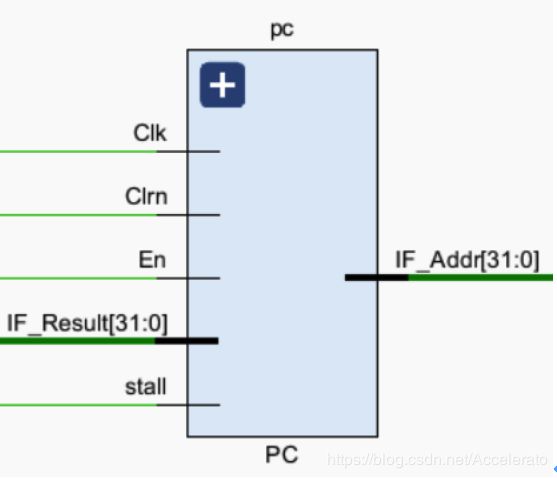
5.1.2 PC
-
所处位置
-
模块功能
用于给出指令在指令储存器中的地址,且当发生数据冒险时,需要保持PC寄存器不变。 -
实现思路
为实现稳定输出,在时钟信号的上升沿更新。在发生Lw指令的数据冒险和控制冒险时,PC寄存器应该消除错误指令,而且需要在此周期关闭PC寄存器。 -
引脚及控制信号
En:控制PC寄存器的开启和关闭状态,外部输入信号。
stall:判断是否发生Lw指令数据冒险,输入信号。
Clk:时钟周期,输入信号
Clrn:当存在Lw指令的数据冒险和控制冒险时为零,输入信号。
IF_Result目标地址,输入信号。
IF_Addr:指令地址,输出信号。 -
主要实现代码
module PC(IF_Result,Clk,En,Clrn,IF_Addr,stall);
input [31:0]IF_Result;
input Clk,En,Clrn,stall;
output [31:0] IF_Addr;
wire En_S;
assign En_S=En&~stall;
D_FFEC32 pc(IF_Result,Clk,En_S,Clrn,IF_Addr);
endmodule
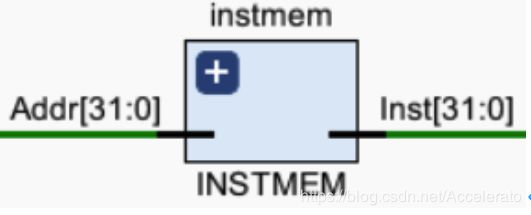
5.1.3 INSTMEM
-
所处位置
-
模块功能
依据当前pc,读取指令寄存器中相对应地址Addr[6:2]的指令。 -
实现思路
将pc的输入作为敏感变量,当pc发生改变的时候,则进行指令的读取,根据相关的地址,输出指令寄存器中相对应的指令,且在设计指令的时候,要用到12条给出的指令且尽量合理。 -
引脚及控制信号
IF_Addr:指令地址,输入信号
IF_Inst:指令编码,输出信号 -
主要实现代码
module INSTMEM(Addr,Inst);//指令存储器
input[31:0]Addr;
output[31:0]Inst;
wire[31:0]Rom[31:0];
assign Rom[5'h00]=32'h20010008;//addi $1,$0,8 $1=8 001000 00000 00001 0000000000001000
assign Rom[5'h01]=32'h3402000C;//ori $2,$0,12 $2=12
assign Rom[5'h02]=32'h00221820;//add $3,$1,$2 $3=20//数据冒险
assign Rom[5'h03]=32'h00412022;//sub $4,$2,$1 $4=4
assign Rom[5'h04]=32'h00222824;//and $5,$1,$2
assign Rom[5'h05]=32'h00223025;//or $6,$1,$2
assign Rom[5'h06]=32'h14220006;//bne $1,$2,6//00010100001000010000000000000110
assign Rom[5'h07]=32'h00221820;//add $3,$1,$2 $3=20
assign Rom[5'h08]=32'h00412022;//sub $4,$2,$1 $4=4
assign Rom[5'h09]=32'h10220002;// beq $1,$2,2
assign Rom[5'h0A]=32'h0800000D;// J 0D
assign Rom[5'h0B]=32'hXXXXXXXX;
assign Rom[5'h0C]=32'hXXXXXXXX;
assign Rom[5'h0D]=32'hAD02000A;// sw $2 10($8) memory[$8+10]=12
assign Rom[5'h0E]=32'h8D04000A;//lw $4 10($8) $4=12
assign Rom[5'h0F]=32'h10440002;//beq $2,$4,2//lw数据冒险
assign Rom[5'h10]=32'h20210004;//addi $1,$1,4 //00100000001000010000000000000100
assign Rom[5'h11]=32'h00222824;//and $5,$1,$2
assign Rom[5'h12]=32'h14220006;//bne $1,$2,6
assign Rom[5'h13]=32'h30470009;//andi $2,9,$7//控制冒险
assign Rom[5'h14]=32'hXXXXXXXX;
assign Rom[5'h15]=32'hXXXXXXXX;
assign Rom[5'h16]=32'hXXXXXXXX;
assign Rom[5'h17]=32'hXXXXXXXX;
assign Rom[5'h18]=32'hXXXXXXXX;
assign Rom[5'h19]=32'hXXXXXXXX;
assign Rom[5'h1A]=32'hXXXXXXXX;
assign Rom[5'h1B]=32'hXXXXXXXX;
assign Rom[5'h1C]=32'hXXXXXXXX;
assign Rom[5'h1D]=32'hXXXXXXXX;
assign Rom[5'h1E]=32'hXXXXXXXX;
assign Rom[5'h1F]=32'hXXXXXXXX;
assign Inst=Rom[Addr[6:2]];
Endmodule
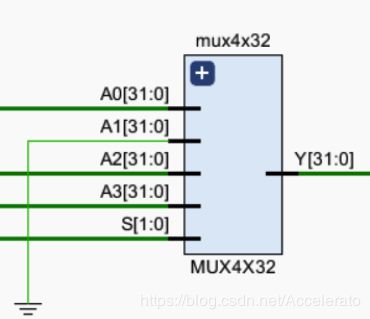
5.1.4 MUX4X32
-
所处位置
-
模块功能
实现目标地址的选择 -
实现思路
目标地址可能是PC+4,也可能是beq和bne的跳转地址或是J型跳转地址,所以采用一个32位四选一多路选择器 -
引脚及控制信号
IF_PCadd4:PC+4的地址,输入信号。
0:空位,输入信号。
mux4x32_2:beq和bne指令的跳转地址,输入信号。
0:空位,输入信号。(InstL2:J指令的跳转地址,输入信号)
Pcsrc:对地址进行选择的控制信号,输入信号
IF_Result:目标地址,输出信号 -
主要实现代码
module MUX4X32 (A0, A1, A2, A3, S, Y);
input [31:0] A0, A1, A2, A3;
input [1:0] S;
output [31:0] Y;
function [31:0] select;
input [31:0] A0, A1, A2, A3;
input [1:0] S;
case(S)
2'b00: select = A0;
2'b01: select = A1;
2'b10: select = A2;
2'b11: select = A3;
endcase
endfunction
assign Y = select (A0, A1, A2, A3, S);
endmodule
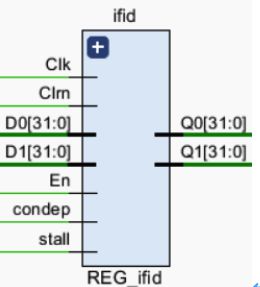
5.1.5 REG_ifid
-
所处位置
-
模块功能
寄存IF级的输出指令,分割IF级和ID级的指令或控制信号,防止相互干扰,在IF级执行结束时将指令的控制信号传递至下一级。 -
引脚及控制信号
IF_PCadd4:下一条指令地址,输入信号。
IF_Inst:本条指令编码,输入信号。
En:写使能信号,输入信号。
Clk:时钟信号,输入信号。
Clrn:清零信号,输入信号。
ID_PCadd4:下条指令地址,输出信号。
ID_Inst:本条指令编码,输出信号。
Stall:记录是否存在Lw数据冒险,输出信号。
Stall:记录是否存在控制冒险,输出信号。 -
主要实现代码
module REG_ifid(D0,D1,En,Clk,Clrn,Q0,Q1,stall,condep);
input [31:0] D0,D1;
input En,Clk,Clrn;
input stall,condep;
output [31:0] Q0,Q1;
wire En_S,Clrn_C;
assign En_S=En&~stall;
assign Clrn_C=Clrn&~condep;
D_FFEC32 q0(D0,Clk,En_S,Clrn_C,Q0);
D_FFEC32 q1(D1,Clk,En_S,Clrn_C,Q1);
Endmodule
5.2指令译码部分(ID)
5.2.1 CONUNIT
-
所处位置

-
模块功能
控制器是作为CPU控制信号产生的器件,通过通过解析op得到该指令的各种控制信号,使其他器件有效或无效。 -
实现思路
在单周期CONUNIT的基础上,需要增加一些功能,如判断处于ID级的指令和处于EX级或MEM级的指令是否存在数据冒险,是否存在Lw数据冒险,是否存在控制冒险。 -
引脚及控制信号
M_Op;MEM级指令的OP字段,输入信号。
M_Z;MEM级指令的Z值。stall
ID_Inst[31:26]:Op,输入信号。
ID_Inst[5:0]:Func,输入信号。
Z:零标志信号,对Pcsrc有影响,输入信号。
Regrt:控制输入寄存器的Wr端口,输出信号。
Se:控制扩展模块,输出信号。
Wreg:控制寄存器端的写使能信号,输出信号。
Aluqb:控制ALU的Y端口的输入值,输出信号。
Aluc:控制ALU的计算种类,输出信号。
Wmem:控制数据存储器的写使能信号,输出信号。
Pcsrc:控制目标指令地址,输出信号。
Reg2reg:控制REHFILE更新值的来源,输出信号。
ID_Inst[25:21]:ID指令的rs字段,输入信号。
ID_Inst[20:16]:ID指令的rt字段,输入信号。
E_Rd[4:0]:EX级输出的目的寄存器号,输入信号。
M_Rd[4:0]:MEM级输出的目的寄存器号,输入信号。
E_Wreg:EX级的写使能信号,输入信号。
M_Wreg:MEM级写使能信号,输入信号。
FwdA[1:0]:判断是否在rs寄存器发生数据冒险,输出信号。
FwdB[1:0]:判断是否在rt寄存器发生数据冒险,输出信号。
E:写使能信号,外部输入信号 -
主要实现代码
module CONUNIT(E_Op,Op,Func,Z,Regrt,Se,Wreg,Aluqb,Aluc,Wmem,Pcsrc,Reg2reg,Rs,Rt,E_Rd,M_Rd,E_Wreg,M_Wreg,FwdA,FwdB,E_Reg2reg,stall,condep);
input [5:0]Op,Func,E_Op;
input Z;
input E_Wreg,M_Wreg,E_Reg2reg;
input [4:0]E_Rd,M_Rd,Rs,Rt;
output Regrt,Se,Wreg,Aluqb,Wmem,Reg2reg,stall,condep;
output [1:0]Pcsrc,Aluc;
output reg [1:0]FwdA,FwdB;
wire R_type=~|Op;
wire I_add=R_type&Func[5]&~Func[4]&~Func[3]&~Func[2]&~Func[1]&~Func[0];
wire I_sub=R_type&Func[5]&~Func[4]&~Func[3]&~Func[2]&Func[1]&~Func[0];
wire I_and=R_type&Func[5]&~Func[4]&~Func[3]&Func[2]&~Func[1]&~Func[0];
wire I_or=R_type&Func[5]&~Func[4]&~Func[3]&Func[2]&~Func[1]&Func[0];
wire I_addi=~Op[5]&~Op[4]&Op[3]&~Op[2]&~Op[1]&~Op[0];
wire I_andi=~Op[5]&~Op[4]&Op[3]&Op[2]&~Op[1]&~Op[0];
wire I_ori=~Op[5]&~Op[4]&Op[3]&Op[2]&~Op[1]&Op[0];
wire I_lw=Op[5]&~Op[4]&~Op[3]&~Op[2]&Op[1]&Op[0];
wire I_sw=Op[5]&~Op[4]&Op[3]&~Op[2]&Op[1]&Op[0];
wire I_beq=~Op[5]&~Op[4]&~Op[3]&Op[2]&~Op[1]&~Op[0];
wire I_bne=~Op[5]&~Op[4]&~Op[3]&Op[2]&~Op[1]&Op[0];
wire E_beq=~E_Op[5]&~E_Op[4]&~E_Op[3]&E_Op[2]&~E_Op[1]&~E_Op[0];
wire E_bne=~E_Op[5]&~E_Op[4]&~E_Op[3]&E_Op[2]&~E_Op[1]&E_Op[0];
wire I_J=~Op[5]&~Op[4]&~Op[3]&~Op[2]&Op[1]&~Op[0];
wire E_Inst = I_add|I_sub|I_and|I_or|I_sw|I_beq|I_bne;
assign Regrt = I_addi|I_andi|I_ori|I_lw|I_sw|I_beq|I_bne|I_J;
assign Se = I_addi|I_lw|I_sw|I_beq|I_bne;
assign Wreg = I_add|I_sub|I_and|I_or|I_addi|I_andi|I_ori|I_lw;
assign Aluqb = I_add|I_sub|I_and|I_or|I_beq|I_bne|I_J;
assign Aluc[1] = I_and|I_or|I_andi|I_ori;
assign Aluc[0] = I_sub|I_or|I_ori|I_beq|I_bne;
assign Wmem = I_sw;
assign Pcsrc[1] = (E_beq&Z)|(E_bne&~Z)|I_J;
assign Pcsrc[0] = I_J;
assign Reg2reg = I_add|I_sub|I_and|I_or|I_addi|I_andi|I_ori|I_sw|I_beq|I_bne|I_J;
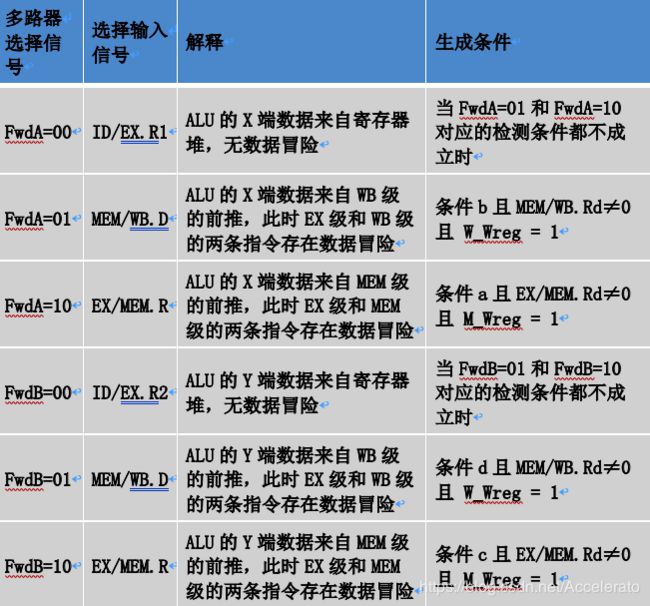
always@(E_Rd,M_Rd,E_Wreg,M_Wreg,Rs,Rt)begin
FwdA=2'b00;
if((Rs==E_Rd)&(E_Rd!=0)&(E_Wreg==1))begin
FwdA=2'b10;
end else begin
if((Rs==M_Rd)&(M_Rd!=0)&(M_Wreg==1))begin
FwdA=2'b01;
end
end
end
always@(E_Rd,M_Rd,E_Wreg,M_Wreg,Rs,Rt)begin
FwdB=2'b00;
if((Rt==E_Rd)&(E_Rd!=0)&(E_Wreg==1))begin
FwdB=2'b10;
end else begin
if((Rt==M_Rd)&(M_Rd!=0)&(M_Wreg==1))begin
FwdB=2'b01;
end
end
end
assign stall=((Rs==E_Rd)|(Rt==E_Rd))&(E_Reg2reg==0)&(E_Rd!=0)&(E_Wreg==1);
assign condep=(E_beq&Z)|(E_bne&~Z);
endmodule
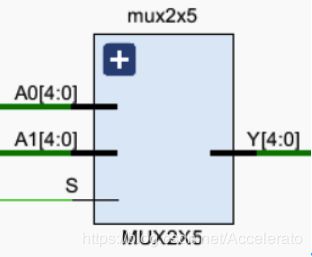
5.2.2 MUX2X5
-
所处位置
-
模块功能
R型指令和I行指令的Wr信号不同,所以需要一个5位二选一选择器进行
选择。 -
实现思路
R型指令Wr选择rd信号,I型指令Wr选择rt信号。 -
引脚及控制信号
ID_Inst[15:11],:R型指令的rd信号,输入信号
ID_Inst[20:16]:I型指令的rt信号,输入信号
Regrt:选择指令的控制信号,输入信号
ID_Wr:Wr信号,输出信号 -
主要实现代码
module MUX2X5(A0,A1,S,Y);
input [4:0] A0,A1;
input S;
output [4:0] Y;
function [4:0] select;
input [4:0] A0,A1;
input S;
case(S)
0:select=A0;
1:select=A1;
endcase
endfunction
assign Y=select(A0,A1,S);
endmodule
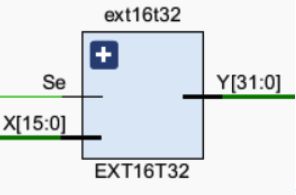
5.2.3 EXT16T32
-
所处位置
-
模块功能
I指令的addi需要对立即数进行符号拓展,andi和ori需要对立即数进行零扩展,所以需要一个扩展模块。 -
实现思路
采用一个16位扩展成32位的扩展模块EXT16T32,实现零扩展和符号扩展。 -
引脚及控制信号
ID_Inst[15:0]:I型指令的立即数字段,输入信号。
Se:选择零扩展或是符号扩展的控制模块,输入信号。
ID_EXTIMM:扩展后的立即数,输出信号。 -
主要实现代码
module EXT16T32 (X, Se, Y);
input [15:0] X;
input Se;
output [31:0] Y;
wire [31:0] E0, E1;
wire [15:0] e = {16{X[15]}};
parameter z = 16'b0;
assign E0 = {z, X};
assign E1 = {e, X};
MUX2X32 i(E0, E1, Se, Y);
endmodule
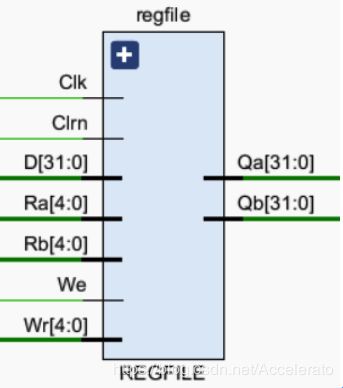
5.2.4 REGFILE
-
所处位置
-
模块功能
给出要读取的两个寄存器编号和要写入的寄存器编号,然后由Qa和Qb端口更新Ra和Rb端口的输入编号分别输入其值。 -
实现思路
由32个寄存器组成,增加两个端口用于接收要读取的两个寄存器编号,另一个端口用于接收要写入的寄存器的编号。且在时钟上升沿将D写入。 -
引脚及控制信号
ID_Inst[25:21]:读取寄存器编号1,输入信号。
ID_Inst[20:16]:读取寄存器编号2或立即数,输入信号。
D:寄存器更新值,输入信号。
W_Wr:写入寄存器编号3,输入信号。
W_Wreg:写使能信号,为0的时候不能写入,D值不更新,为1的时候能写入,D值更新,输入信号。
Clk:时钟周期,输入信号。
Clrn:清零信号,输入信号。
ID_Qa:输出寄存器1的值,输入信号。
ID_Qb:输出寄存器2的值,输入信号。 -
主要实现代码
module REGFILE(Ra,Rb,D,Wr,We,Clk,Clrn,Qa,Qb);
input [4:0]Ra,Rb,Wr;
input [31:0]D;
input We,Clk,Clrn;
output [31:0]Qa,Qb;
wire [31:0]Y_mux,Q31_reg32,Q30_reg32,Q29_reg32,Q28_reg32,Q27_reg32,Q26_reg32,Q25_reg32,Q24_reg32,Q23_reg32,Q22_reg32,Q21_reg32,Q20_reg32,Q19_reg32,Q18_reg32,Q17_reg32,Q16_reg32,Q15_reg32,Q14_reg32,Q13_reg32,Q12_reg32,Q11_reg32,Q10_reg32,Q9_reg32,Q8_reg32,Q7_reg32,Q6_reg32,Q5_reg32,Q4_reg32,Q3_reg32,Q2_reg32,Q1_reg32,Q0_reg32;
DEC5T32E dec(Wr,We,Y_mux);
REG32 A(D,Y_mux,Clk,Clrn,Q31_reg32,Q30_reg32,Q29_reg32,Q28_reg32,Q27_reg32,Q26_reg32,Q25_reg32,Q24_reg32,Q23_reg32,Q22_reg32,Q21_reg32,Q20_reg32,Q19_reg32,Q18_reg32,Q17_reg32,Q16_reg32,Q15_reg32,Q14_reg32,Q13_reg32,Q12_reg32,Q11_reg32,Q10_reg32,Q9_reg32,Q8_reg32,Q7_reg32,Q6_reg32,Q5_reg32,Q4_reg32,Q3_reg32,Q2_reg32,Q1_reg32,Q0_reg32);
MUX32X32 select1(Q0_reg32,Q1_reg32,Q2_reg32,Q3_reg32,Q4_reg32,Q5_reg32,Q6_reg32,Q7_reg32,Q8_reg32,Q9_reg32,Q10_reg32,Q11_reg32,Q12_reg32,Q13_reg32,Q14_reg32,Q15_reg32,Q16_reg32,Q17_reg32,Q18_reg32,Q19_reg32,Q20_reg32,Q21_reg32,Q22_reg32,Q23_reg32,Q24_reg32,Q25_reg32,Q26_reg32,Q27_reg32,Q28_reg32,Q29_reg32,Q30_reg32,Q31_reg32,Ra,Qa);
MUX32X32 select2(Q0_reg32,Q1_reg32,Q2_reg32,Q3_reg32,Q4_reg32,Q5_reg32,Q6_reg32,Q7_reg32,Q8_reg32,Q9_reg32,Q10_reg32,Q11_reg32,Q12_reg32,Q13_reg32,Q14_reg32,Q15_reg32,Q16_reg32,Q17_reg32,Q18_reg32,Q19_reg32,Q20_reg32,Q21_reg32,Q22_reg32,Q23_reg32,Q24_reg32,Q25_reg32,Q26_reg32,Q27_reg32,Q28_reg32,Q29_reg32,Q30_reg32,Q31_reg32,Rb,Qb);
Endmodule
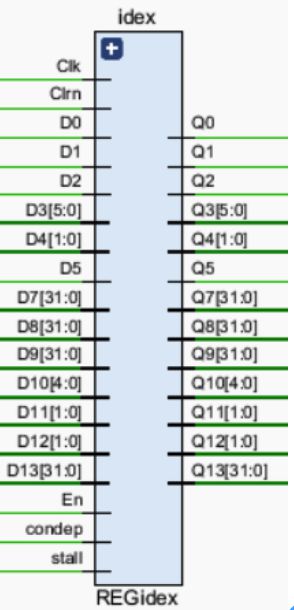
5.2.5 REG_idex
-
所处位置
-
模块功能
寄存ID级的输出指令,分割ID级和EX级的指令或控制信号,防止相互干扰,在ID级执行结束时将指令的控制信号传递至下一级。 -
引脚及控制信号
Wreg,Reg2reg,Wmem,ID_Inst[31:26],Aluc,Aluqb,ID_PCadd4,ID_Qa,ID_Qb,ID_EXTIMM,ID_Wr,En,Clk,Clrn,E_Wreg,E_Reg2reg,E_Wmem,E_Op,E_Aluc,E_Aluqb,E_PC,E_R1,E_R2,E_I,E_Rd,FwdA,FwdB,E_FwdA,E_FwdB,stall -
主要实现代码
module REGidex(D13,D0,D1,D2,D3,D4,D5,D7,D8,D9,D10,En,Clk,Clrn,Q0,Q1,Q2,Q3,Q4,Q5,Q7,Q8,Q9,Q10,D11,D12,Q11,Q12,stall,Q13,condep);
input [31:0] D7,D8,D9,D13;
input [5:0]D3;
input [4:0]D10;
input [1:0]D4,D11,D12;
input D0,D1,D2,D5;
input En,Clk,Clrn,stall,condep;
wire Clrn_SC;
assign Clrn_SC=Clrn&~stall&~condep;
output [31:0] Q7,Q8,Q9,Q13;
output [5:0] Q3;
output [4:0]Q10;
output [1:0]Q4,Q11,Q12;
output Q0,Q1,Q2,Q5;
D_FFEC q0(D0,Clk,En,Clrn_SC,Q0);
D_FFEC q1(D1,Clk,En,Clrn_SC,Q1);
D_FFEC q2(D2,Clk,En,Clrn_SC,Q2);
D_FFEC6 q3(D3,Clk,En,Clrn_SC,Q3);
D_FFEC2 q4(D4,Clk,En,Clrn_SC,Q4);
D_FFEC q5(D5,Clk,En,Clrn_SC,Q5);
// D_FFEC32 q6(D6,Clk,En,Clrn_SC,Q6);
D_FFEC32 q7(D7,Clk,En,Clrn_SC,Q7);
D_FFEC32 q8(D8,Clk,En,Clrn_SC,Q8);
D_FFEC32 q9(D9,Clk,En,Clrn_SC,Q9);
D_FFEC5 q10(D10,Clk,En,Clrn_SC,Q10);
D_FFEC2 q11(D11,Clk,En,Clrn_SC,Q11);
D_FFEC2 q12(D12,Clk,En,Clrn_SC,Q12);
D_FFEC32 q13(D13,Clk,En,Clrn_SC,Q13);
Endmodule
5.3 执行部分(EX)
5.3.1 SHIFTER32_L2
-
所处位置
-
模块功能
使用32位移位器SHIFTER32,固定左移两位即可 -
实现思路
一个固定左移两位的移位器 -
引脚及控制信号
E_I:指令中的偏移量,输入信号
E_I_L2:偏移量左移后的结果,输出信号 -
主要实现代码
module SHIFTER32_L2(X,Sh);
input [31:0] X;
output [31:0] Sh;
parameter z=2'b00;
assign Sh={X[29:0],z};
endmodule
5.3.2 MUX4X32
-
所处位置
-
模块功能
在内部前推的工作中,ALU的两个输入端都需要选择来自
ID/EX寄存器或者EX/MEM寄存器或者MEM/WB寄存器所锁存的值 -
实现思路
通过控制模块的控制信号FwdA和FwdB来选择。输出信号输入同级的ALU进行计算。 -
引脚及控制信号
1)
E_R1;来自Qa端口的信号,输入信号。
D;来自WB级的信号,输入信号
M_R;来自MEM级的信号,输入信号。
0;空信号。
E_FwdA;选择信号。
Alu_X:作为ALU中X端的信号,输出信号。
2)
E_R2:来自Qb端口的信号,输入信号。
D:;来自WB级的信号,输入信号。
M_R: 来自MEM级的信号,输入信号。
0:空信号
E_FwdB:选择信号
E_NUM:,选择的寄存器锁存的值和立即数做选择,后输作为ALU中Y端的信号,输出信号。
-
主要实现代码
module MUX4X32 (A0, A1, A2, A3, S, Y);
input [31:0] A0, A1, A2, A3;
input [1:0] S;
output [31:0] Y;
function [31:0] select;
input [31:0] A0, A1, A2, A3;
input [1:0] S;
case(S)
2'b00: select = A0;
2'b01: select = A1;
2'b10: select = A2;
2'b11: select = A3;
endcase
endfunction
assign Y = select (A0, A1, A2, A3, S);
endmodule
5.3.3 MUX2X32
-
所处位置
-
模块功能
ALU的Y端输入信号种类根据指令的不同而不同 -
实现思路
在执行R型指令时,ALU的Y端输入信号可能来自Qb,在进行内部前推后变成FwdA端信号。在执行I型指令的addi,andi和ori指令时时,ALU的Y端输入信号来自EXT16T32,所以需要一个二选一选择器。 -
引脚及控制信号
E_I: 来自EXT16T32的信号,输入信号。
E_NUM: 来自FwdB端口的信号,输入信号。
E_Aluqb: 控制信号。
Y: 输入ALU进行后续计算的信号,输出信号。 -
主要实现代码
module MUX2X32(A0,A1,S,Y);
input [31:0] A0,A1;
input S;
output [31:0] Y;
function [31:0] select;
input [31:0] A0,A1;
input S;
case(S)
0:select=A0;
1:select=A1;
endcase
endfunction
assign Y=select(A0,A1,S);
endmodule
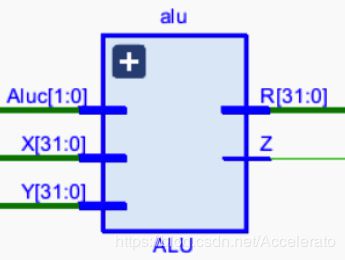
5.3.4 ALU
-
所处位置
-
模块功能
算数逻辑部件,需要实现加,减,按位与,按位或。 -
实现思路
需要2位控制信号控制运算类型,核心部件是32位加法器ADDSUB_32。 -
引脚及控制信号
Alu_X:寄存器1的值。来自REG_idex,输入信号。
Y:寄存器2的值或立即数,输入信号。
E_Aluc:控制信号。
E_R:输入寄存器端口D的计算结果,输出信号。
E_Z:当值为1时代表两个输入信号值相等,当值为0时代表两个输入信号不等,输出信号。 -
主要实现代码
module ALU(X,Y,Aluc,R,Z);//ALU代码
input [31:0]X,Y;
input [1:0]Aluc;
output [31:0]R;
output Z;
wire[31:0]d_as,d_and,d_or,d_and_or;
ADDSUB_32 as(X,Y,Aluc[0],d_as);
assign d_and=X&Y;
assign d_or=X|Y;
MUX2X32 select1(d_and,d_or,Aluc[0],d_and_or);
MUX2X32 seleted(d_as,d_and_or,Aluc[1],R);
assign Z=~|R;
endmodule
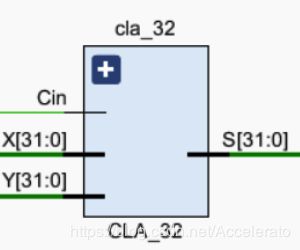
5.3.5 CLA_32
-
所处位置
-
模块功能
在beq和bne指令时如果发生地址的跳转,需要使用32位加法器,跳转地址是pc+4的地址和立即数之和的结果。 -
实现思路
输入信号是pc+4,和左移后的立即数,结果作为beq和bne的跳转地址。 -
引脚及控制信号
E_PC:REG_idex寄存的PCadd4的值,输入信号。
E_I_L2:左移后的立即数,输入信号。
0:进位信号,初始为0,输入信号。
EX_PC:作为beq和bne的跳转地址,输出信号。
Cout: 进位信息,输出信号。 -
主要实现代码
module CLA_32(X, Y, Cin, S, Cout);
input [31:0] X, Y;
input Cin;
output [31:0] S;
output Cout;
wire Cout0, Cout1, Cout2, Cout3, Cout4, Cout5, Cout6;
CLA_4 add0 (X[3:0], Y[3:0], Cin, S[3:0], Cout0);
CLA_4 add1 (X[7:4], Y[7:4], Cout0, S[7:4], Cout1);
CLA_4 add2 (X[11:8], Y[11:8], Cout1, S[11:8], Cout2);
CLA_4 add3 (X[15:12], Y[15:12], Cout2, S[15:12], Cout3);
CLA_4 add4 (X[19:16], Y[19:16], Cout3, S[19:16], Cout4);
CLA_4 add5 (X[23:20], Y[23:20], Cout4, S[23:20], Cout5);
CLA_4 add6 (X[27:24], Y[27:24], Cout5, S[27:24], Cout6);
CLA_4 add7 (X[31:28], Y[31:28], Cout6, S[31:28], Cout);
endmodule
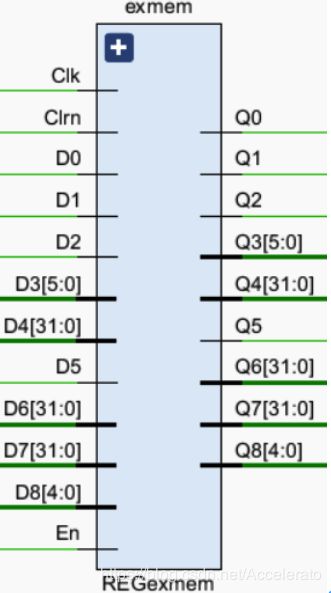
5.3.6 REG_exmem
-
所处位置
-
模块功能
寄存EX级的输出指令,分割EX级和MEM级的指令或控制信号,防止相互干扰,在EX级执行结束时将指令的控制信号传递至下一级。 -
引脚及控制信号
E_Wreg,E_Reg2reg,E_Wmem,E_Op,EX_PC,E_Z,E_R,E_R2,E_Rd,En,Clk,Clrn,M_Wreg,M_Reg2reg,M_Wmem,M_Op,M_PC,M_Z,M_R,M_S,M_Rd -
主要实现代码
module REGexmem(D0,D1,D2,D3,D4,D5,D6,D7,D8,En,Clk,Clrn,Q0,Q1,Q2,Q3,Q4,Q5,Q6,Q7,Q8);
input [31:0] D4,D6,D7;
input [5:0]D3;
input [4:0]D8;
input D0,D1,D2,D5;
input En,Clk,Clrn;
output [31:0] Q4,Q6,Q7;
output [5:0] Q3;
output [4:0]Q8;
output Q0,Q1,Q2,Q5;
D_FFEC q0(D0,Clk,En,Clrn,Q0);
D_FFEC q1(D1,Clk,En,Clrn,Q1);
D_FFEC q2(D2,Clk,En,Clrn,Q2);
D_FFEC6 q3(D3,Clk,En,Clrn,Q3);
D_FFEC32 q4(D4,Clk,En,Clrn,Q4);
D_FFEC q5(D5,Clk,En,Clrn,Q5);
D_FFEC32 q6(D6,Clk,En,Clrn,Q6);
D_FFEC32 q7(D7,Clk,En,Clrn,Q7);
D_FFEC5 q8(D8,Clk,En,Clrn,Q8);
endmodule
5.4存储器访问部分(MEM)
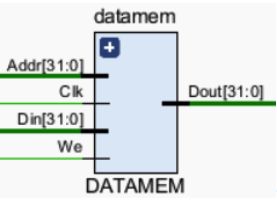
5.4.1 DATAMEMß
-
所处位置
-
模块功能
数据存储器,通过控制信号,对数据寄存器进行读或者写操作,并且此处模块额外合并了输出DB的数据选择器,此模块同时输出写回寄存器组的数据DB。 -
实现思路
由于需要支持取数/存数指令,所以要在指令储存器的基础上增加写入数据的数据写入端口,写使能信号。又因为写操作在时钟信号的上升沿,所以要增加时钟信号。 -
引脚及控制信号
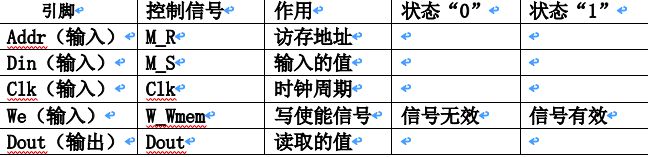
当We为1时,进行sw指令操作,此时Din端口输入信号实际为rt,Addr端口输入信号为rs和偏移量相加的地址,在时钟周期上升沿将rt的值写入改地址的储存单元。
当We为0时,进行lw指令操作,此时Addr端口输入信号为rs和偏移量相加的地址,Dout为读取该地址储存器的内容。 -
主要实现代码
module DATAMEM(Addr,Din,Clk,We,Dout);
input[31:0]Addr,Din;
input Clk,We;
output[31:0]Dout;
reg[31:0]Ram[31:0];
assign Dout=Ram[Addr[6:2]];
always@(posedge Clk)begin
if(We)Ram[Addr[6:2]]<=Din;
end
integer i;
initial begin
for(i=0;i<32;i=i+1)
Ram[i]=0;
end
endmodule
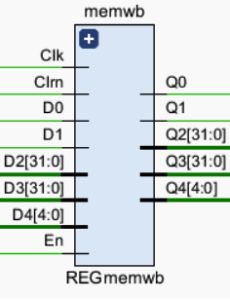
5.4.2 REG_memwb
-
所处位置
-
模块功能
数据存储器,通过控制信号,对数据寄存器进行读或者写操作,并且此处模块额外合并了输出DB的数据选择器,此模块同时输出写回寄存器组的数据DB。 -
引脚及控制信号
M_Wreg,M_Reg2reg,M_R,Dout,M_Rd,En,Clk,Clrn,W_Wreg,W_Reg2reg,W_D,W_C,W_Wr -
主要实现代码
module REGmemwb(D0,D1,D2,D3,D4,En,Clk,Clrn,Q0,Q1,Q2,Q3,Q4);
input D0,D1;
input [31:0] D2,D3;
input [4:0] D4;
input En,Clk,Clrn;
output Q0,Q1;
output [31:0] Q2,Q3;
output [4:0] Q4;
D_FFEC q0(D0,Clk,En,Clrn,Q0);
D_FFEC q1(D1,Clk,En,Clrn,Q1);
D_FFEC32 q2(D2,Clk,En,Clrn,Q2);
D_FFEC32 q3(D3,Clk,En,Clrn,Q3);
D_FFEC5 q4(D4,Clk,En,Clrn,Q4);
Endmodule
5.5寄存器堆写回部分(WB)
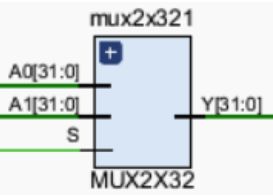
5.5.1 MUX2X32
-
所处位置
-
模块功能
对写入寄存器的数据进行选择 -
实现思路
在lw指令中,需要将DATAMEM中选中储存器的值保存到REGFILE的寄存器中,而其他会更新REGFILE的指令的更新信号来自于ALU的R输出端。所以需要一个二选一选择器进行选择。 -
引脚及控制信号
W_C:DATAMEM的输出值,输入信号
W_D:ALU的输出值,输入信号
W_Reg2reg:控制信号
D:写入R寄存器堆D端的信号,输出信号 -
主要实现代码
module MUX2X32(A0,A1,S,Y);
input [31:0] A0,A1;
input S;
output [31:0] Y;
function [31:0] select;
input [31:0] A0,A1;
input S;
case(S)
0:select=A0;
1:select=A1;
endcase
endfunction
assign Y=select(A0,A1,S);
endmodule
5.6 顶层模块
-
所处位置

-
模块功能
实现CPU的封装,设计输出信号使得在方正时便于观察其波形图 -
实现思路
调用各个下层模块并将他们的输入和输出连接到一起。 -
引脚及控制信号
CLk:时钟周期,外部输入信号。
Clrn:清零信号,外部输入信号。
En:写使能信号,外部输入信号。 -
主要实现代码
module MAIN(Clk,En,Clrn,IF_ADDR,EX_X,EX_Y,EX_R);
input Clk,En,Clrn;
output[31:0] IF_ADDR,EX_R,EX_X,EX_Y;
wire [31:0] IF_Result,IF_Addr,IF_PCadd4,IF_Inst,D,ID_Qa,ID_Qb,ID_PCadd4,ID_Inst;
wire [31:0] E_R1,E_R2,E_I,E_I_L2,Y,E_R,EX_PC,M_PC,M_R,M_S,Dout,W_D,W_C,ID_EXTIMM,Alu_X,E_NUM,ID_EXTIMM_L2,ID_PC;
wire[5:0] E_Op;
wire [4:0] ID_Wr,W_Wr,E_Rd,M_Rd;
wire [1:0]Aluc,Pcsrc,E_Aluc,FwdA,FwdB,E_FwdA,E_FwdB;
wire Regrt,Se,Wreg,Aluqb,Reg2reg,Wmem,Z;
wire E_Wreg,E_Reg2reg,E_Wmem,E_Aluqb,Cout,M_Wreg,M_Reg2reg,M_Wmem,W_Wreg,W_Reg2reg,stall,condep;
//IF
MUX4X32 mux4x32(IF_PCadd4,0,EX_PC,0,Pcsrc,IF_Result);
PC pc(IF_Result,Clk,En,Clrn,IF_Addr,stall);
PCadd4 pcadd4(IF_Addr,IF_PCadd4);
INSTMEM instmem(IF_Addr,IF_Inst);
REG_ifid ifid(IF_PCadd4,IF_Inst,En,Clk,Clrn,ID_PCadd4,ID_Inst,stall,condep);
//ID
CONUNIT conunit(E_Op,ID_Inst[31:26],ID_Inst[5:0],Z,Regrt,Se,Wreg,Aluqb,Aluc,Wmem,Pcsrc,Reg2reg,ID_Inst[25:21],ID_Inst[20:16],E_Rd,M_Rd,E_Wreg,M_Wreg,FwdA,FwdB,E_Reg2reg,stall,condep);
MUX2X5 mux2x5(ID_Inst[15:11],ID_Inst[20:16],Regrt,ID_Wr);
EXT16T32 ext16t32(ID_Inst[15:0],Se,ID_EXTIMM);//ID_EXTIMM对应E_I
REGFILE regfile(ID_Inst[25:21],ID_Inst[20:16],D,W_Wr,W_Wreg,Clk,Clrn,ID_Qa,ID_Qb);
SHIFTER32_L2 shifter2(ID_EXTIMM,ID_EXTIMM_L2);//控制冒险
CLA_32 cla_32(ID_PCadd4,ID_EXTIMM_L2,0,ID_PC,Cout);//ID_PCadd4对应E_PC
REGidex idex(ID_PC,Wreg,Reg2reg,Wmem,ID_Inst[31:26],Aluc,Aluqb,ID_Qa,ID_Qb,ID_EXTIMM,ID_Wr,En,Clk,Clrn,E_Wreg,E_Reg2reg,E_Wmem,E_Op,E_Aluc,E_Aluqb,E_R1,E_R2,E_I,E_Rd,FwdA,FwdB,E_FwdA,E_FwdB,stall,EX_PC,condep);
//EX
//SHIFTER32_L2 shifter2(E_I,E_I_L2);
MUX4X32 mux4x32_ex_1(E_R1,D,M_R,0,E_FwdA,Alu_X);
MUX4X32 mux4x32_ex_2(E_R2,D,M_R,0,E_FwdB,E_NUM);
MUX2X32 mux2x321(E_I,E_NUM,E_Aluqb,Y);
ALU alu(Alu_X,Y,E_Aluc,E_R,Z);
//CLA_32 cla_32(E_PC,E_I_L2,0,EX_PC,Cout);
REGexmem exmem(E_Wreg,E_Reg2reg,E_Wmem,EX_PC,E_R,E_R2,E_Rd,En,Clk,Clrn,M_Wreg,M_Reg2reg,M_Wmem,M_PC,M_R,M_S,M_Rd);
//MEM
DATAMEM datamem(M_R,M_S,Clk,M_Wmem,Dout);
REGmemwb memwb(M_Wreg,M_Reg2reg,M_R,Dout,M_Rd,En,Clk,Clrn,W_Wreg,W_Reg2reg,W_D,W_C,W_Wr);
//WB
MUX2X32 mux2x322(W_C,W_D,W_Reg2reg,D);
assign IF_ADDR=IF_Addr;
assign EX_R=E_R;
assign EX_X=Alu_X;
assign EX_Y=Y;
endmodule
5.7 仿真模块
- 主要实现代码
module TEST;
reg Clk;
reg En;
reg Clrn;
wire [31:0] IF_ADDR;
wire [31:0] EX_R;
wire [31:0] EX_X;
wire [31:0] EX_Y;
MAIN uut(
.Clk(Clk),
.En(En),
.Clrn(Clrn),
.IF_ADDR(IF_ADDR),
.EX_R(EX_R),
.EX_X(EX_X),
.EX_Y(EX_Y)
);
initial begin
Clk=0;Clrn=0;En=1;
#10;
Clk=1;Clrn=0;
#10;
Clrn=1;
Clk=0;
forever #20 Clk=~Clk;
end
endmodule
六、 仿真模拟分析
6.1 仿真波形图
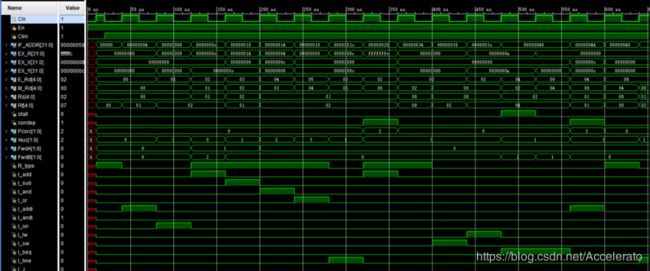
6.2 指令代码分析
1)assign Rom[5’h00]=32’h20010008;
二进制源码:001000 00000 00001 00000 00000 001000
指令含义:addi $1,$0,8
结果:$1=$0+8=8
2)assign Rom[5’h01]=32’h3402000C;//ori $2,$0,12 $2=12
二进制源码:001101 00000 00010 00000 00000 001100
指令含义:ori $2,$0,12
结果:$2=12
3)assign Rom[5’h02]=32’h00221820;
指令含义:add $3,$1,$2
结果:$3=20,输出值正确,代表一般的数据冒险得到解决。
4)assign Rom[5’h03]=32’h00412022;
指令含义:addi $1,$0,8
结果:$1=$0+8=8
5)assign Rom[5’h04]=32’h00222824;
指令含义:addi $1,$0,8
结果:$1=$0+8=8
6)assign Rom[5’h05]=32’h00223025;
指令含义:addi $1,$0,8
结果:$1=$0+8=8
7)assignRom[5’h06]=32’h14220006;
二进制源码:00010100001000010000000000000110
指令含义:bne $1,$2,6
结果:跳转到地址加6的位置
8)assign Rom[5’h07]=32’h00221820;
指令含义:add $3,$1,$2 $3=20
结果:未执行
9)assign Rom[5’h08]=32’h00412022;
指令含义:sub $4,$2,$1 $4=4
结果:未执行
10)assign Rom[5’h09]=32’h10220002;
指令含义:beq $1,$2,2
结果:未执行
11)assign Rom[5’h0A]=32’h0800000D;
指令含义:J 0D
结果:未执行
12)assign Rom[5’h0B]=32’hXXXXXXXX;
13)assign Rom[5’h0C]=32’hXXXXXXXX;
14)assign Rom[5’h0D]=32’hAD02000A;
二进制源码:001000 00000 00001 00000 00000 001000
指令含义:sw $2 10($8)
结果:memory[$8+10]=12
15)assign Rom[5’h0E]=32’h8D04000A;//
二进制源码:001000 00000 00001 00000 00000 001000
指令含义:lw $4 10($8)
结果:$4=12
16)assign Rom[5’h0F]=32’h10440002;
二进制源码:001000 00000 00001 00000 00000 001000
指令含义:beq $2,$4,2
结果:寄存器值相等,发生跳转,跳转到地址加2的地方。说明lw数据冒险得到解决。
17)assign Rom[5’h10]=32’h20210004;
二进制源码:00100000001000010000000000000100
指令含义:addi $1,$1,4
结果:未执行
18)assign Rom[5’h11]=32’h00222824;
指令含义:and $5,$1,$2
结果:未执行
19)assign Rom[5’h12]=32’h14220006;//
二进制源码:001000 00000 00001 00000 00000 001000
指令含义:bne $1,$2,6
结果:发生了跳转,说明18这条指令未执行,控制冒险得到解决。
20)assign Rom[5’h13]=32’h30470009;
指令含义:andi $2,9,$7
结果:未执行
21)assign Rom[5’h14]=32’hXXXXXXXX;
22)assign Rom[5’h15]=32’hXXXXXXXX;
23)assign Rom[5’h16]=32’hXXXXXXXX;
24)assign Rom[5’h17]=32’hXXXXXXXX;
25)assign Rom[5’h18]=32’hXXXXXXXX;
26)assign Rom[5’h19]=32’hXXXXXXXX;
27)assign Rom[5’h1A]=32’hXXXXXXXX;
28)assign Rom[5’h1B]=32’hXXXXXXXX;
29)assign Rom[5’h1C]=32’hXXXXXXXX;
30)assign Rom[5’h1D]=32’hXXXXXXXX;
31)assign Rom[5’h1E]=32’hXXXXXXXX;
32)assign Rom[5’h1F]=32’hXXXXXXXX;
6.3阻塞分析
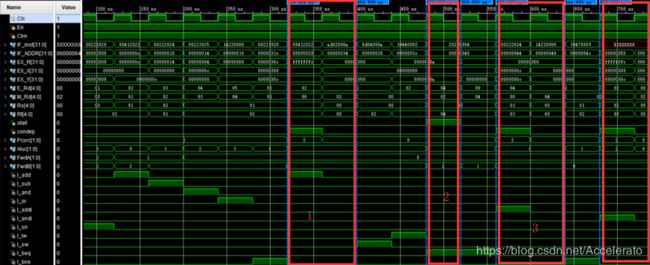
第一个红框是流水线CPU因为bne结构冒险而暂停的两个时钟周期,
第二个红框是流水线CPU因为lw数据冒险而暂停的一个时钟周期,
第三个红框是流水线PCU因为beq数据冒险而暂停的两个时钟周期
第四个红框是流水线PCU因为bne数据冒险而暂停的时钟周期。
七、 结论和体会
7.1体会感悟
通过此次的CPU设计实验,让我们对CPU内部组成以及指令在CPU部件上如何运作有了一个更深的理解。在实验过程中,我们遇到了各种问题,一开始老师布置下来的CPU任务的时候,完全是懵的,因为CPU器件和指令运算只在课本上学习,从来没有真正实践过,现在需要自己设计CPU的各个部件,而且要将指令在器件上运行,感觉很复杂。但在接下来的日子,我们没有因为不会而放弃,而是努力专心去设计好每个部件,对每个部件的功能进行模拟仿真,确保这一部件模块不出错,在设计过程中,感觉慢慢可以理清思路,也明白了下一步需要设计的东西通过此次实验,让我们对CPU有了更深的理解,而不只是纸上谈兵。其中控制冒险和Lw的数据冒险让我们头疼了很久,我们始终不能准确判断conque和stall信号的输出位置。经过整整两周的摸索,终于找到了正确的解决方案,并且顺利的设计出合理的指令,达到了预期的目的。
7.2对本实验过程及方法、手段的改进建议
1.过程中,应该每个部件都分别进行调试之后再组装在一起。
2.各部件尽量再拆分为更小的部件组合而成。
3.对控制信号的检测应该更加多元化,这样更有利于分析CPU流水线运作过程。
PS
PS: 好啦,至此位置,单周期和流水线CPU的简单实现的流程就全部交代清楚来,接下来我会将重心转向人工智能领域,短期规划是现实常见算法的pygame可视化(比如DFS,BFS,markov,Astar ,SIR,etc)一起加油吧!