无人驾驶汽车系统入门(二十八)——基于VoxelNet的激光雷达点云车辆检测及ROS实现
无人驾驶汽车系统入门(二十八)——基于VoxelNet的激光雷达点云车辆检测及ROS实现
前文我们提到使用SqueezeSeg进行了三维点云的分割,由于采用的是SqueezeNet作为特征提取网络,该方法的处理速度相当迅速(在单GPU加速的情况下可达到100FPS以上的效率),然而,该方法存在如下的问题:第一,虽然采用了CRF改进边界模糊的问题,但是从实践结果来看,其分割的精度仍然偏低;第二,该模型需要大量的训练集,而语义分割数据集标注困难,很难获得大规模的数据集。当然,作者在其后的文章:SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud 中给出了改进的方案,我将在后面的文章中继续解读。需要注意的是,在无人车环境感知问题中,很多情况下并不需要对目标进行精确的语义分割,只需将目标以一个三维的Bounding Box准确框出即可(即Detection),本文介绍一种基于点云的Voxel(三维体素)特征的深度学习方法,实现对点云中目标的准确检测,并提供一个简单的ROS实现,供大家参考。
VoxelNet结构
VoxelNet是一个端到端的点云目标检测网络,和图像视觉中的深度学习方法一样,其不需要人为设计的目标特征,通过大量的训练数据集,即可学习到对应的目标的特征,从而检测出点云中的目标,如下:
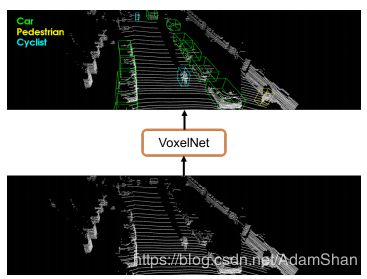
VoxelNet的网络结构主要包含三个功能模块:(1)特征学习层;(2)卷积中间层;(3) 区域提出网络( Region Proposal Network,RPN)。
特征学习网络
特征学习网络的结构如下图所示,包括体素分块(Voxel Partition),点云分组(Grouping),随机采样(Random Sampling),多层的体素特征编码(Stacked Voxel Feature Encoding),稀疏张量表示(Sparse Tensor Representation)等步骤,具体来说:
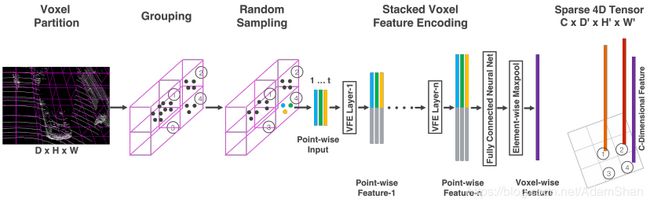
体素分块
这是点云操作里最常见的处理,对于输入点云,使用相同尺寸的立方体对其进行划分,我们使用一个深度、高度和宽度分别为 ( D , H , W ) (D, H, W) (D,H,W)的大立方体表示输入点云,每个体素的深高宽为 ( v D , v H , v W ) (v_D, v_H, v_W) (vD,vH,vW) ,则整个数据的三维体素化的结果在各个坐标上生成的体素格(voxel grid)的个数为: ( D v D , H v H , W v W ) ( \frac{D}{v_D}, \frac{H}{v_H}, \frac{W}{v_W}) (vDD,vHH,vWW) 。
点云分组
将点云按照上一步分出来的体素格进行分组,如上图所示。
随机采样
很显然,按照这种方法分组出来的单元会存在有些体素格点很多,有些格子点很少的情况,64线的激光雷达一次扫描包含差不多10万个点,全部处理需要的计算力和内存都很高,而且高密度的点势必会给神经网络的计算结果带来偏差。所以,该方法在这里插入了一层随机采样,对于每一个体素格,随机采样固定数目的点, T T T。
多个体素特征编码(Voxel Feature Encoding,VFE)层
之后是多个体素特征编码层,简称为VFE层,这是特征学习的主要网络结构,以第一个VFE层为例说明:
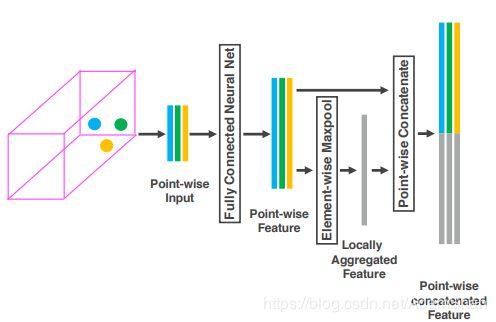
对于输入:
V = { p i = [ x i , y i , z i , r i ] ∈ R 4 } i = 1.... t V=\lbrace p_i = [ x_i,y_i,z_i,r_i ] \in \mathbb{R}^4 \rbrace_{i=1....t} V={pi=[xi,yi,zi,ri]∈R4}i=1....t
是一个体素格内随机采样的点集, t < = T t <=T t<=T, ( x i , y i , z i , r i ) ( x_i,y_i,z_i,r_i ) (xi,yi,zi,ri) 分别点的XYZ坐标以及激光束的反射强度(即intensity),我们首先计算体素内所有点的平均值 ( v x , v y , v z ) (v_x, v_y, v_z) (vx,vy,vz) 作为体素格的形心(类似于Voxel Grid Filter),那么我们就可以将体素格内所有点的特征数量扩充为如下形式:
V i n = { p ^ i = [ x i , y i , z i , r i , x i − v x , y i − v y , z i − v z ] T ∈ R 7 } i = 1... t V_{in} = \lbrace \widehat{p}_i= [x_i,y_i,z_i, r_i,x_i-v_x,y_i-v_y,z_i-v_z]^T \in \mathbb{R}^7 \rbrace_{i = 1...t} Vin={p i=[xi,yi,zi,ri,xi−vx,yi−vy,zi−vz]T∈R7}i=1...t
接着,每一个 p ^ i \widehat{p}_i p i 都会通过一个全连接网络(Fully Connected,FC,论文中用的是FCN来简称,实际上FCN更多的被用于表示全卷积网络,所以原文此处用FCN简称实际上不妥)被映射到一个特征空间 f i ∈ R m f_i \in \mathbb{R}^m fi∈Rm ,输入的特征维度为7,输出的特征维数变成 m m m,全连接层包含了一个线性映射层,一个批标准化(Batch Normalization),以及一个非线性运算(ReLU),得到逐点的(point-wise)的特征表示。
接着我们采用最大池化(MaxPooling)对上一步得到的特征表示进行逐元素的聚合,这一池化操作是对元素和元素之间进行的,得到局部聚合特征(Locally Aggregated Feature),即 f ^ ∈ R m \widehat{f} \in \mathbb{R}^m f ∈Rm ,最后,将逐点特征和逐元素特征进行连接(concatenate),得到输出的特征集合:
V o u t = { f i o u t } i = 1... t V_{out} =\lbrace f^{out}_i \rbrace_{i = 1...t} Vout={fiout}i=1...t
对于所有的非空的体素格我们都进行上述操作,并且它们都共享全连接层(FC)的参数。我们使用符号 ( c i n , c o u t ) (c_{in}, c_{out}) (cin,cout) 来描述经过VFE以后特征的维数变化,那么显然全连接层的参数矩阵大小为:
( c i n , c o u t 2 ) (c_{in}, \frac{c_{out}}{2}) (cin,2cout)
由于VFE层中包含了逐点特征和逐元素特征的连接,经过多层VFE以后,我们希望网络可以自动学习到每个体素内的特征表示(比如说体素格内的形状信),那么如何学习体素内的特征表示呢?原论文的方法下图所示:
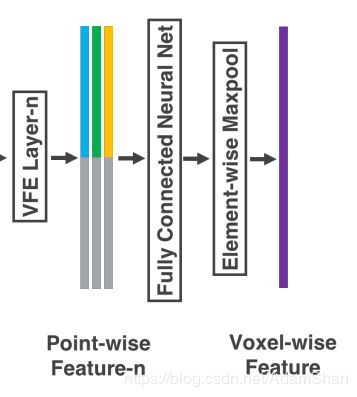
通过对体素格内所有点进行最大池化,得到一个体素格内特征表示 C C C 。
稀疏张量表示
通过上述流程处理非空体素格,我们可以得到一系列的体素特征(Voxel Feature)。这一系列的体素特征可以使用一个4维的稀疏张量来表示:
C × D ′ × H ′ × W ′ C \times D' \times H' \times W' C×D′×H′×W′
虽然一次lidar扫描包含接近10万个点,但是超过90%的体素格都是空的,使用稀疏张量来描述非空体素格在于能够降低反向传播时的内存和计算消耗。
对于具体的车辆检测问题,我们取沿着Lidar坐标系的 ( Z , Y , X ) (Z,Y,X) (Z,Y,X)方向取 [ − 3 , 1 ] × [ − 40 , 40 ] × [ 0 , 70.4 ] [−3, 1] × [−40, 40] × [0, 70.4] [−3,1]×[−40,40]×[0,70.4]立方体(单位为米)作为输入点云,取体素格的大小为:
v D = 0.4 , v H = 0.2 , v W = 0.2 v_D = 0.4, v_H = 0.2, v_W = 0.2 vD=0.4,vH=0.2,vW=0.2
那么有
D ′ = 10 , H ′ = 400 , W ′ = 352 D' = 10, H' = 400, W' = 352 D′=10,H′=400,W′=352
我们设置随机采样的 T = 35 T = 35 T=35,并且采用两个VFE层:VFE-1(7, 32) 和 VFE-2(32, 128),最后的全连接层将VFE-2的输出映射到 R 128 \mathbb{R}^{128} R128。最后,特征学习网络的输出即为一个尺寸为 ( 128 × 10 × 400 × 352 ) (128\times 10 \times 400 \times 352) (128×10×400×352) 的稀疏张量。整个特征网络的TensorFlow实现代码如下:
class VFELayer(object):
def __init__(self, out_channels, name):
super(VFELayer, self).__init__()
self.units = int(out_channels / 2)
with tf.variable_scope(name, reuse=tf.AUTO_REUSE) as scope:
self.dense = tf.layers.Dense(
self.units, tf.nn.relu, name='dense', _reuse=tf.AUTO_REUSE, _scope=scope)
self.batch_norm = tf.layers.BatchNormalization(
name='batch_norm', fused=True, _reuse=tf.AUTO_REUSE, _scope=scope)
def apply(self, inputs, mask, training):
# [K, T, 7] tensordot [7, units] = [K, T, units]
pointwise = self.batch_norm.apply(self.dense.apply(inputs), training)
#n [K, 1, units]
aggregated = tf.reduce_max(pointwise, axis=1, keep_dims=True)
# [K, T, units]
repeated = tf.tile(aggregated, [1, cfg.VOXEL_POINT_COUNT, 1])
# [K, T, 2 * units]
concatenated = tf.concat([pointwise, repeated], axis=2)
mask = tf.tile(mask, [1, 1, 2 * self.units])
concatenated = tf.multiply(concatenated, tf.cast(mask, tf.float32))
return concatenated
class FeatureNet(object):
def __init__(self, training, batch_size, name=''):
super(FeatureNet, self).__init__()
self.training = training
# scalar
self.batch_size = batch_size
# [ΣK, 35/45, 7]
self.feature = tf.placeholder(
tf.float32, [None, cfg.VOXEL_POINT_COUNT, 7], name='feature')
# [ΣK]
self.number = tf.placeholder(tf.int64, [None], name='number')
# [ΣK, 4], each row stores (batch, d, h, w)
self.coordinate = tf.placeholder(
tf.int64, [None, 4], name='coordinate')
with tf.variable_scope(name, reuse=tf.AUTO_REUSE) as scope:
self.vfe1 = VFELayer(32, 'VFE-1')
self.vfe2 = VFELayer(128, 'VFE-2')
# boolean mask [K, T, 2 * units]
mask = tf.not_equal(tf.reduce_max(
self.feature, axis=2, keep_dims=True), 0)
x = self.vfe1.apply(self.feature, mask, self.training)
x = self.vfe2.apply(x, mask, self.training)
# [ΣK, 128]
voxelwise = tf.reduce_max(x, axis=1)
# car: [N * 10 * 400 * 352 * 128]
# pedestrian/cyclist: [N * 10 * 200 * 240 * 128]
self.outputs = tf.scatter_nd(
self.coordinate, voxelwise, [self.batch_size, 10, cfg.INPUT_HEIGHT, cfg.INPUT_WIDTH, 128])
卷积中间层
每一个卷积中间层包含一个3维卷积,一个BN层(批标准化),一个非线性层(ReLU),我们用:
C o n v 3 D ( c i n , c o u t , k , s , p ) Conv3D(c_{in}, c_{out}, k, s, p) Conv3D(cin,cout,k,s,p)
来描述一个卷积中间层, C o n v 3 D Conv3D Conv3D表示是三维卷积, c i n , c o u t c_{in}, c_{out} cin,cout分别表示输入和输出的通道数, k k k 是卷积核的大小,它是一个向量,对于三维卷积而言,卷积核的大小为 ( k , k , k ) (k,k,k) (k,k,k); s s s 即stride,卷积操作的步长; p p p 即padding,填充的尺寸。
对于车辆检测而言,设计的卷积中间层如下:
Conv3D(128, 64, 3,(2,1,1), (1,1,1))
Conv3D(64, 64, 3, (1,1,1), (0,1,1))
Conv3D(64, 64, 3, (2,1,1), (1,1,1))
卷积中间层的TensorFlow代码如下:
def ConvMD(M, Cin, Cout, k, s, p, input, training=True, activation=True, bn=True, name='conv'):
temp_p = np.array(p)
temp_p = np.lib.pad(temp_p, (1, 1), 'constant', constant_values=(0, 0))
with tf.variable_scope(name) as scope:
if(M == 2):
paddings = (np.array(temp_p)).repeat(2).reshape(4, 2)
pad = tf.pad(input, paddings, "CONSTANT")
temp_conv = tf.layers.conv2d(
pad, Cout, k, strides=s, padding="valid", reuse=tf.AUTO_REUSE, name=scope)
if(M == 3):
paddings = (np.array(temp_p)).repeat(2).reshape(5, 2)
pad = tf.pad(input, paddings, "CONSTANT")
temp_conv = tf.layers.conv3d(
pad, Cout, k, strides=s, padding="valid", reuse=tf.AUTO_REUSE, name=scope)
if bn:
temp_conv = tf.layers.batch_normalization(
temp_conv, axis=-1, fused=True, training=training, reuse=tf.AUTO_REUSE, name=scope)
if activation:
return tf.nn.relu(temp_conv)
else:
return temp_conv
# convolutinal middle layers
temp_conv = ConvMD(3, 128, 64, 3, (2, 1, 1),
(1, 1, 1), self.input, name='conv1')
temp_conv = ConvMD(3, 64, 64, 3, (1, 1, 1),
(0, 1, 1), temp_conv, name='conv2')
temp_conv = ConvMD(3, 64, 64, 3, (2, 1, 1),
(1, 1, 1), temp_conv, name='conv3')
temp_conv = tf.transpose(temp_conv, perm=[0, 2, 3, 4, 1])
temp_conv = tf.reshape(temp_conv, [-1, cfg.INPUT_HEIGHT, cfg.INPUT_WIDTH, 128])
区域提出网络(RPN)
RPN实际上是目标检测网络中常用的一种网络,下图是VoxelNet中使用的RPN:
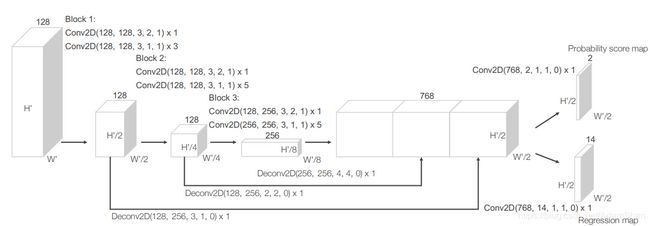
如图所示,该网络包含三个全卷积层块(Block),每个块的第一层通过步长为2的卷积将特征图采样为一半,之后是三个步长为1的卷积层,每个卷积层都包含BN层和ReLU操作。将每一个块的输出都上采样到一个固定的尺寸并串联构造高分辨率的特征图。最后,该特征图通过两种二维卷积被输出到期望的学习目标:
- 概率评分图(Probability Score Map )
- 回归图(Regression Map)
使用TensorFlow实现该RPN如下(非完整代码,完整代码请见文末链接)):
def Deconv2D(Cin, Cout, k, s, p, input, training=True, bn=True, name='deconv'):
temp_p = np.array(p)
temp_p = np.lib.pad(temp_p, (1, 1), 'constant', constant_values=(0, 0))
paddings = (np.array(temp_p)).repeat(2).reshape(4, 2)
pad = tf.pad(input, paddings, "CONSTANT")
with tf.variable_scope(name) as scope:
temp_conv = tf.layers.conv2d_transpose(
pad, Cout, k, strides=s, padding="SAME", reuse=tf.AUTO_REUSE, name=scope)
if bn:
temp_conv = tf.layers.batch_normalization(
temp_conv, axis=-1, fused=True, training=training, reuse=tf.AUTO_REUSE, name=scope)
return tf.nn.relu(temp_conv)
# rpn
# block1:
temp_conv = ConvMD(2, 128, 128, 3, (2, 2), (1, 1),
temp_conv, training=self.training, name='conv4')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv5')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv6')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv7')
deconv1 = Deconv2D(128, 256, 3, (1, 1), (0, 0),
temp_conv, training=self.training, name='deconv1')
# block2:
temp_conv = ConvMD(2, 128, 128, 3, (2, 2), (1, 1),
temp_conv, training=self.training, name='conv8')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv9')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv10')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv11')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv12')
temp_conv = ConvMD(2, 128, 128, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv13')
deconv2 = Deconv2D(128, 256, 2, (2, 2), (0, 0),
temp_conv, training=self.training, name='deconv2')
# block3:
temp_conv = ConvMD(2, 128, 256, 3, (2, 2), (1, 1),
temp_conv, training=self.training, name='conv14')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv15')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv16')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv17')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv18')
temp_conv = ConvMD(2, 256, 256, 3, (1, 1), (1, 1),
temp_conv, training=self.training, name='conv19')
deconv3 = Deconv2D(256, 256, 4, (4, 4), (0, 0),
temp_conv, training=self.training, name='deconv3')
# final:
temp_conv = tf.concat([deconv3, deconv2, deconv1], -1)
# Probability score map, scale = [None, 200/100, 176/120, 2]
p_map = ConvMD(2, 768, 2, 1, (1, 1), (0, 0), temp_conv,
training=self.training, activation=False, bn=False, name='conv20')
# Regression(residual) map, scale = [None, 200/100, 176/120, 14]
r_map = ConvMD(2, 768, 14, 1, (1, 1), (0, 0),
temp_conv, training=self.training, activation=False, bn=False, name='conv21')
损失函数
我们首先定义 { a i p o s } i = 1... N p o s { \lbrace a_i^{pos}\rbrace_{i = 1...N_{pos}}} {aipos}i=1...Npos 为正样本集合, { a j n e g } j = 1... N n e g { \lbrace a_j^{neg}\rbrace_{j = 1...N_{neg}}} {ajneg}j=1...Nneg为负样本集合,使用 ( x c g , y c g , z c g , l g , w g , h g , θ g ) (x^g_c, y^g_c, z^g_c, l^g, w^g, h^g, \theta^g) (xcg,ycg,zcg,lg,wg,hg,θg)来表示一个真实的3D标注框,其中 ( x c g , y c g , z c g ) (x^g_c, y^g_c, z^g_c) (xcg,ycg,zcg) 表示标注框中心的坐标, ( l g , w g , h g ) (l^g, w^g, h^g) (lg,wg,hg)表示标注框的长宽高, θ g \theta^g θg表示偏航角(Yaw)。相应的, ( x c a , y c a , z c a , l a , w a , h a , θ a ) (x^a_c, y^a_c, z^a_c, l^a, w^a, h^a, \theta^a) (xca,yca,zca,la,wa,ha,θa) 表示正样本框。那么回归的目标为一下七个量:
Δ x = x c g − x c a d a , Δ y = y c g − y c a d a , Δ z = z c g − z c a h a \Delta x = \frac{x^g_c - x^a_c}{d^a}, \Delta y = \frac{y^g_c - y^a_c}{d^a},\Delta z = \frac{z^g_c - z^a_c}{h^a} Δx=daxcg−xca,Δy=daycg−yca,Δz=hazcg−zca
Δ l = log l g l a , Δ w = log w g w a , Δ h = log h g h a , Δ θ = θ g − θ a \Delta l = \log\frac{l^g}{l^a}, \Delta w = \log\frac{w^g}{w^a},\Delta h = \log\frac{h^g}{h^a}, \Delta \theta = \theta^g - \theta^a Δl=loglalg,Δw=logwawg,Δh=loghahg,Δθ=θg−θa
其中:
d a = ( l a ) 2 + ( w a ) 2 d^a = \sqrt{(l^a)^2 + (w^a)^2} da=(la)2+(wa)2
是正样本框的对角线。我们定义损失函数为:
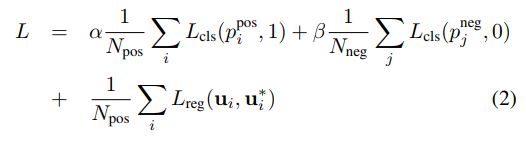
其中 p i p o s p_i^{pos} pipos和 p j n e g p_j^{neg} pjneg分别表示正样本 a i p o s a_i^{pos} aipos 和负样本 a j n e g a_j^{neg} ajneg 的Softmax输出, u i \bm{u}_i ui和 u i ∗ \bm{u}_i^* ui∗ 分别表示神经网络的正样本输出的标注框和真实标注框。损失函数的前两项表示对于正样本输出和负样本输出的分类损失(已经进行了正规化),其中 L c l s L_{cls} Lcls表示交叉熵, α \alpha α和 β \beta β是两个常数,它们作为权重来平衡正负样本损失对于最后的损失函数的影响。 L r e g L_{reg} Lreg表示回归损失,这里采用的是Smooth L1函数。
ROS实践
我们仍然使用第二十六篇博客的数据(截取自KITTI),下载地址:https://pan.baidu.com/s/1kxZxrjGHDmTt-9QRMd_kOA
我们直接采用qianguih提供的训练好的模型(参考:https://github.com/qianguih/voxelnet ,大家也可以基于该项目自己训练模型)。
安装项目依赖环境:
- python3.5+
- TensorFlow (tested on 1.4)
- opencv
- shapely
- numba
- easydict
- ROS
- jsk package
准备数据
下载上面的数据集,解压到项目(源码地址见文末)的data文件夹下,目录结构为:
data
----lidar_2d
--------0000...1.npy
--------0000...2.npy
--------.......
运行
catkin_makeroscd voxelnet/script/python3 voxelnet_ros.py & python3 pub_kitti_point_cloud.py- 注意不能使用
rosrun,因为VoxelNet代码为Python 3.x
- 注意不能使用
rqt节点图

使用Rviz可视化


存在的问题
- 实例的模型的性能不佳,由于论文作者没有开源其代码,许多参数仍然有待调整
- 速度慢,没有实现作者提出的高效策略
感兴趣的同学可以试着调整参数提高模型性能,欢迎大家留言、私信交流。