9.Shuffle读写源码分析
先直接上原理图吧 !
ShuffleMapTask在计算数据之后会为每一个ResultTask创建一份bucket缓存 , 以及对应的ShuffleBlockFIle磁盘文件进行储存 , 在计算完之后会将计算过的相应信息放入MapStatus , 最后发送给Driver中的DAGScheduler的MapOutputTracker , 每个ResultTask会用BlockStoreShuffleFetcher去MapOutputTracker中的MapStatus获取需要拉取的数据 , 然后通过底层的BlockManager将数据拉取过来 , 拉取过来的数据就会组成一个内部的RDD , 叫ShuffleRDD , 存入缓存 , 缓存不够存入磁盘 , 最后ResultMap对数据进行聚合生成MapPartitionRDD , 也就是我们所写程序中action操作后结果RDD
优化后的shuffle分析原理图:
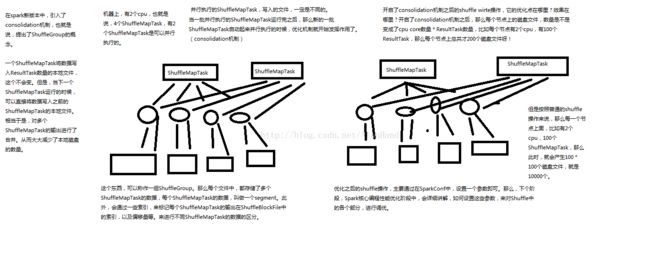
优化后的shuffle原理就是根据cpu的数量在ShuffleMap写入数据到磁盘文件时只会创建于cpu相应的文件数据 , 后面在运行新的ShuffleMapTask的时候也只会向同样的文件中写入数据 , 同时会记录下一些索引来记录哪个ShuffleMapTask计算的数据在ShuffleBlockFile中的位置 , 多个ShuffleMapTask写入的数据就叫做一个segment , 也就是说原来的100个ShuffleMapTask对应的100个ResulTask时会创建100*100个磁盘文件 , 而现在只需要cpu数量乘以ResultMap的数量之积文件数 , 减少了大量的磁盘文件读写 , 这种优化shuffle的方式只需在创建SparkContext的时候设置一个参数即可
在上一章节关于Task的源码分析最后的关于writer的代码中:
writer
.
write
(
rdd
.
iterator
(
partition
,
context
).
asInstanceOf
[
Iterator
[
_
<:
Product2
[
Any
,
Any
]]])
其实这个writer默认的情况下就是HaspShuffleWriter , 调用writer的方法源码如下:
/** Write a bunch of records to this task's output */ /** * 将每个ShuffleMapTask计算出来的新的RDD的partition数据写入本地磁盘 */ override def write(records: Iterator[_ <: Product2[K, V]]): Unit = { // 首先判断,是否需要在map端进行本地聚合 // 比如reduceByKey这样的算子操作的话它的dep.aggregator.isDegined就是true , 包括def.mapSideCombine也是true val iter = if (dep.aggregator.isDefined) { if (dep.mapSideCombine) { // 这里就会执行本地聚合,比如(Hi,1)(Hi,1)那么此时就会聚合成(Hi,2) dep.aggregator.get.combineValuesByKey(records, context) } else { records } } else { require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!") records } // 如果进行本地聚合那么就会遍历数据 , 对每个数据调用partition默认是HashPartition , 生成bucketId // 也就决定了每一份数据要写入哪个bucket for (elem <- iter) { val bucketId = dep.partitioner.getPartition(elem._1) // 获取到了bucketId之后就会调用ShuffleBlockManager.formapTask()方法来生成bucketId对应的writer,然后用writer将数据写入bucket shuffle.writers(bucketId).write(elem) } }
这里的shuffle是HushShuffleWriter的一个成员变量 , 通过shuffleBlockManager对象的forMapTask方法获取每个bucketId对应的writer , forMapTask方法源码如下:
/** * 给每个map task获取一个ShuffleWriterGroup */ def forMapTask(shuffleId: Int, mapId: Int, numBuckets: Int, serializer: Serializer, writeMetrics: ShuffleWriteMetrics) = { new ShuffleWriterGroup { shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numBuckets)) private val shuffleState = shuffleStates(shuffleId) private var fileGroup: ShuffleFileGroup = null // 重点: 对应上我们之前所说的shuffle有两种模式 , 一种是普通的,一种是优化后的 // 如果开启了consolication机制,也即使consolicationShuffleFiles为true的话那么实际上不会给每个bucket都获取一个独立的文件 // 而是为了这个bucket获取一个ShuffleGroup的writer val writers: Array[BlockObjectWriter] = if (consolidateShuffleFiles) { fileGroup = getUnusedFileGroup() Array.tabulate[BlockObjectWriter](numBuckets) { bucketId => // 首先用shuffleId, mapId,bucketId生成一个一个唯一的ShuffleBlockId // 然后用bucketId来调用shuffleFileGroup的apply()函数为bucket获取一个ShuffleFileGroup val blockId = ShuffleBlockId(shuffleId, mapId, bucketId) // 然后用BlockManager的getDisWriter()方法针对ShuffleFileGroup获取一个Writer // 这样的话如果开启了consolidation机制那么对于每一个bucket都会获取一个针对ShuffleFileGroup的writer , 而不是一个独立的ShuffleBlockFile的writer // 这样就实现了所谓的多个ShuffleMapTask的输出数据合并 blockManager.getDiskWriter(blockId, fileGroup(bucketId), serializer, bufferSize, writeMetrics) } } else { // 如果没有开启consolation机制 Array.tabulate[BlockObjectWriter](numBuckets) { bucketId => // 同样生成一个ShuffleBlockId val blockId = ShuffleBlockId(shuffleId, mapId, bucketId) // 然后调用BlockManager的DiskBlockManager , 获取一个代表了要写入本地磁盘文件的BlockFile val blockFile = blockManager.diskBlockManager.getFile(blockId) // Because of previous failures, the shuffle file may already exist on this machine. // If so, remove it. // 而且会判断这个blockFile要是存在的话还得删除它 if (blockFile.exists) { if (blockFile.delete()) { logInfo(s"Removed existing shuffle file $blockFile") } else { logWarning(s"Failed to remove existing shuffle file $blockFile") } } // 然后调用BlockManager的getDiskWriterff针对那个blockFile生成writer blockManager.getDiskWriter(blockId, blockFile, serializer, bufferSize, writeMetrics) } // 所以使用过这种普通的我shuffle操作的话对于每一个ShuffleMapTask输出的bucket都会在本地获取一个但粗的shuffleBlockFile }
上面代码的注释已经很详细啦 , 就是根据是否设置consolication机制来判断是否给每一个bucket数据创建一个独立的文件 , 若设置了consolication机制的话那么就会给这个bucket数据生成一个shuffeBlockId
然后根据bucket原有的id获取到一个ShuffleFileGroup . 而最后就会针对每一个bucket都会获取这个关于ShuffleFileGroup的Writer进行数据的写 , 而不是为每一个bucket都创建一个独立的shufflerBlockFile的writer
上面是关于一个stage中最后shuffle的写操作 , 接下来就是下一个stage读取上一个stage shuffle数据的读操作:
先来看下ShuffleRDD中的compute方法 , 源码如下:
/** * Shuffle读数据的入口 */ override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = { // ResultTask或者ShuffleMapTask在执行ShuffleRDD时肯定会调用ShuffleRDD的compute方法,来计算当前这个RDD的partition的数据 // 这个就是之前的Task源码分析时结合TaskRunner所分析的 // 在这里会调用ShuffleManager的getReader()方法,获取一个HashShuffleReader , 然后调用它的read()方法拉取该ResultTask,ShuffleMapTask需要聚合的数据 val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]] SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context) .read() .asInstanceOf[Iterator[(K, C)]] }
其实就是获取了一个与HashShuffleWriter相对应的HashShuffleReader来读取bucket中的数据而已 , 我们来看看HashShuffleWriter中读取数据的方法read(),源码如下:
override def read(): Iterator[Product2[K, C]] = { val ser = Serializer.getSerializer(dep.serializer) // 这里就跟图解上面的串起来了 // ResultTask在拉取数据时其实会调用BlockStoreShuffleFetcher来从DAGScheduler的MapOutputTrackermaster中获取自己想要的数据的信息 // 底层再通过BlockManager从对应的位置拉取需要的数据 val iter = BlockStoreShuffleFetcher.fetch(handle.shuffleId, startPartition, context, ser) val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) { if (dep.mapSideCombine) { new InterruptibleIterator(context, dep.aggregator.get.combineCombinersByKey(iter, context)) } else { new InterruptibleIterator(context, dep.aggregator.get.combineValuesByKey(iter, context)) } } else { require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!") // Convert the Product2s to pairs since this is what downstream RDDs currently expect iter.asInstanceOf[Iterator[Product2[K, C]]].map(pair => (pair._1, pair._2)) }
原理就是先拿到需要拉取数据的原信息 , 通过DAGScheduler的MapOutputTracker来获取 , 然后通过BlockManager来进行网络数据的拉取 , 这之间的操作都是上面的BlockStoreShuffleFetcher的fetch()方法实现的 , 源码如下:
def fetch[T]( shuffleId: Int, reduceId: Int, context: TaskContext, serializer: Serializer) : Iterator[T] = { logDebug("Fetching outputs for shuffle %d, reduce %d".format(shuffleId, reduceId)) val blockManager = SparkEnv.get.blockManager val startTime = System.currentTimeMillis // 重点 : 首先拿到一个全局的MapOutputTrackerMaster的引用 , 然后调用其getServerStatuses方法 , 传入的两个参数要注意 // shuffleId可以代表当前这个stage的上一个stage , shuffle是分为两个stage的 , shuffle write发生在上一个stage中,shuffle read发生在当前的stage // 因此shuffleId 可以限制到上一个stage的所有ShuffleMapTask输出的mapStatus // 而reduceId就是所谓的buckedId来限制每个MapStatus中获取当前这个ResultTask需要获取的每个ShuffleMapTask的输出文件的信息 // 这里的getServerStatuses会走远程网络通信的 , 因为要获取Driver上的DAGScheduler的MapOutputTrackerMaster val statuses = SparkEnv.get.mapOutputTracker.getServerStatuses(shuffleId, reduceId) logDebug("Fetching map output location for shuffle %d, reduce %d took %d ms".format( shuffleId, reduceId, System.currentTimeMillis - startTime)) // 下面的代码就是对刚刚拉取到的信息status进行一些数据结构上的转换操作 , 比如弄成map格式的数据 val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(Int, Long)]] for (((address, size), index) <- statuses.zipWithIndex) { splitsByAddress.getOrElseUpdate(address, ArrayBuffer()) += ((index, size)) } val blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = splitsByAddress.toSeq.map { case (address, splits) => (address, splits.map(s => (ShuffleBlockId(shuffleId, s._1, reduceId), s._2))) } def unpackBlock(blockPair: (BlockId, Try[Iterator[Any]])) : Iterator[T] = { val blockId = blockPair._1 val blockOption = blockPair._2 blockOption match { case Success(block) => { block.asInstanceOf[Iterator[T]] } case Failure(e) => { blockId match { case ShuffleBlockId(shufId, mapId, _) => val address = statuses(mapId.toInt)._1 throw new FetchFailedException(address, shufId.toInt, mapId.toInt, reduceId, e) case _ => throw new SparkException( "Failed to get block " + blockId + ", which is not a shuffle block", e) } } } } // 重点 : ShuffleBlockFetcherIterator构造以后在其内部就直接根据拉取到的硬盘上的具体位置信息 // 通过BlockManager去远程的ShuffleMapTask所在节点的BlockManager去拉取数据 val blockFetcherItr = new ShuffleBlockFetcherIterator( context, SparkEnv.get.blockManager.shuffleClient, blockManager, blocksByAddress, serializer, SparkEnv.get.conf.getLong("spark.reducer.maxMbInFlight", 48) * 1024 * 1024) val itr = blockFetcherItr.flatMap(unpackBlock) // 最后将拉取到的数据进行一些转化和封装返回 val completionIter = CompletionIterator[T, Iterator[T]](itr, { context.taskMetrics.updateShuffleReadMetrics() }) new InterruptibleIterator[T](context, completionIter) { val readMetrics = context.taskMetrics.createShuffleReadMetricsForDependency() override def next(): T = { readMetrics.incRecordsRead(1) delegate.next() } } }
重点是MapOutputTrackerMaster的getServerStatuses方法中的shuffleId和reduceId , shuffleId代表的是上一个stage中shuffle产生的所有MapStatus数据 ,而reduceId其实就是bucketId , 代表的是当前这个stage中MapResultTask获取的数据文件信息
我们在进入MapOutputTrackerMaster的getServerStatuses方法继续深入 , 源码如下:
/** * Called from executors to get the server URIs and output sizes of the map outputs of * a given shuffle. */ def getServerStatuses(shuffleId: Int, reduceId: Int): Array[(BlockManagerId, Long)] = { val statuses = mapStatuses.get(shuffleId).orNull if (statuses == null) { logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them") var fetchedStatuses: Array[MapStatus] = null // 做了线程同步 fetching.synchronized { // Someone else is fetching it; wait for them to be done // 不断去拉取shuffleId对应的数据 , 只要还没拉倒就死循环等待 while (fetching.contains(shuffleId)) { try { fetching.wait() } catch { case e: InterruptedException => } }
其实就是不断拉取shuffleId对应的数据而已
最后就是拉取ResultTaskMap的数据了 , 在ShuffleBlockFetchIterator类中的initialize()方法中 , 源码如下:
/** * 将这个方法作为入口 , 开始拉取ResultTask对应的多份数据 */ private[this] def initialize(): Unit = { // Add a task completion callback (called in both success case and failure case) to cleanup. context.addTaskCompletionListener(_ => cleanup()) // Split local and remote blocks. // 切分本地的和远程的block val remoteRequests = splitLocalRemoteBlocks() // Add the remote requests into our queue in a random order // 切分完之后进行shuffle随机排序操作 fetchRequests ++= Utils.randomize(remoteRequests) // Send out initial requests for blocks, up to our maxBytesInFlight // 循环往复 , 只要发现还有数据没有拉取完就发送请求到远程去拉取数据 // 这其中有一个参数就是max.bytes.in.flight这么一个参数,这个参数就决定了最多能拉取到多少数据到本地就要开始我们自定义的reduce算子的处理 while (fetchRequests.nonEmpty && (bytesInFlight == 0 || bytesInFlight + fetchRequests.front.size <= maxBytesInFlight)) { sendRequest(fetchRequests.dequeue()) } val numFetches = remoteRequests.size - fetchRequests.size logInfo("Started " + numFetches + " remote fetches in" + Utils.getUsedTimeMs(startTime)) // Get Local Blocks // 拉取完了远程数据之后获取本地的数据 fetchLocalBlocks() logDebug("Got local blocks in " + Utils.getUsedTimeMs(startTime)) }
以上所有就是Shuffle操作的所有详情咯 !