python 实现逻辑斯谛回归(logistic regression)
有用请点赞,没用请差评。
欢迎分享本文,转载请保留出处。
logistic regression模型的原理可以参考这两篇博客:
https://www.jianshu.com/p/4cf34bf158a1
https://blog.csdn.net/c406495762/article/details/77723333
这两篇博客在训练模型时采用的公式是:
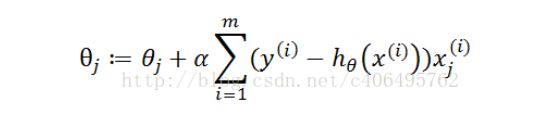

,也就是代码中的实现方法二,另外自己也根据李航《统计学习方法》上面的对数似然函数推导了梯度公式,如下:

采用的数据集是只有两类label(0,1)的MNIST数据集:https://download.csdn.net/download/big_pai/11166917
# -*- coding:utf-8 -*-
# logistic regression,逻辑斯谛回归,极大似然估计模型。算法参考李航《统计学习方法》
#author:Tomator
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
class Logistic_regression(object):
def __init__(self,learn_rate,max_interation):
self.learn_rate=learn_rate
self.max_interation=max_interation
self.w=None
# 第一种实现方法,参考李航《统计学习方法》
def train(self,train_vector,train_label):
train_nums,train_feture_nums=train_vector.shape
print("train_data",train_nums,train_feture_nums)
train_label=train_label.reshape(train_nums,1)
train_label = np.tile(train_label, (1, train_feture_nums))
self.w=np.zeros(train_feture_nums)
interations=1
# while interations < self.max_interation:
while interations < self.max_interation:
alpha_y=np.exp(np.dot(self.w,train_vector.T)) / (1 + np.exp(np.dot(self.w,train_vector.T)))
alpha_y=alpha_y.reshape((train_nums,1))
alpha_y=np.tile(alpha_y,(1,train_feture_nums))
# print(alpha_y.shape,train_label.shape)
alpha_w=np.sum(train_label*train_vector-train_vector*alpha_y)
self.w=self.w+alpha_w
# print(self.w.shape)
interations+=1
self.w=self.w.reshape((1,train_feture_nums))
return self.w
def predict(self, vector):
# vector=vector.reshape((784,1))
exp_wx=np.exp(np.dot(self.w,vector.T))
predict_1=exp_wx/(1+exp_wx)
predict_2=1/(1+exp_wx)
# print("predict",predict_1,predict_2)
if predict_1 > predict_2:
return 0
else:
return 1
# 第二种实现方法
def sigmoid(self,z):
return 1.0 / (1 + np.exp(-z))
def train2(self, train_vector, train_label):
train_nums, train_feture_nums = train_vector.shape
print("train_data", train_nums, train_feture_nums)
self.w = np.zeros(train_feture_nums)
print(self.w.shape)
interations = 1
while interations < self.max_interation:
v = np.dot(self.w, train_vector.T)
error = train_label - self.sigmoid(v)
# print(train_label.shape,error.shape)
self.w += self.learn_rate * np.dot(error, train_vector)
# print(self.w.shape)
interations += 1
return self.w
def predict2(self, x):
PT = self.sigmoid(np.dot(self.w,x.T))
if PT > 1 - PT:
return 1
else:
return 0
if __name__ == "__main__":
np.seterr(divide='ignore', invalid='ignore')
"""
调用pandas的read_csv()方法时,默认使用C engine作为parser engine,而当文件名中含有中文的时候,用C engine在部分情况下就会出错。所以在调用read_csv()方法时指定engine为Python就可以解决问题了。
"""
data=pd.read_csv("D:\\python3_anaconda3\\学习\\机器学习\\机器学习数据集\\MNIST数据集——两类label\\train_binary.csv",skiprows=1,engine='python')
data = data.values[1:,:]
data=np.array(data)
# 划分训练集和测试集
train_data,test_data = train_test_split(data,test_size=0.3, random_state=0)
# CSV文件的第一行为表头,转换成numpy数组时要剔除
train_vector=train_data[:,1:]
train_label=train_data[:,0]
test_vector=test_data[:,1:]
test_label=test_data[:,0]
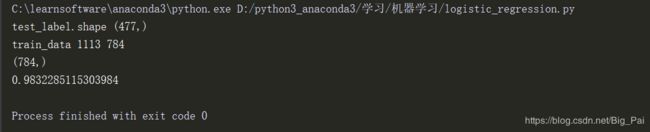
print("test_label.shape",test_label.shape)
logistic=Logistic_regression(learn_rate=0.00001,max_interation=5000)
logistic.train(train_vector,train_label)
score=0
for vector,label in zip(test_vector,test_label):
if logistic.predict(vector) == label:
score+=1
print(score/len(test_label))
第一种实现方法的输出结果,训练时间较慢。
第二种实现方法的输出结果,速度较快。