Unet简明代码实现眼底图像血管分割
Unet是一种自编码器网络结构,常用于医学图像分割任务,比如眼底图像血管分割。这位大佬已经开源了非常棒的代码,但是这套代码比较复杂,我初学菜鸟硬是啃了好几天才啃下来。现在我代码进行重写,仅保留最必要的部分,并尽量简明,全部代码不到100行,便于初学者快速看懂能用。
1.任务简介
本任务基于DRIVE数据集,将眼底图像中的血管树给分离出来。DRIVE数据集包含40张眼底图像,尺寸为565×584,其中20张为训练集,20张测试集,40张图片都给出了专家标注结果。数据集下载可自行百度,或者官网下载。
本代码包含以下几个部分:
数据加载及预处理:把图片分割成若干48×48的小图片,由于原图尺寸不能被48整除,这里先把原图尺寸resize为576×576。和大佬开源代码不同,这里没有使用随机选取的方式,而只使用原图分割出来的全部小图,相当于没有用数据增强,这样总共得到训练集2880个,训练精度比原作者使用190000个稍低一些,但训练速度会快很多,便于快速运行和调参。如果需要提高精度,可自行设计数据增强方法。
Unet模型:模型输入的张量形状为(?,1,48,48),输出为(?,2340,2)。?表示训练集的样本数,本例中为2880。
训练:把原作者代码中的SGD改为Adam,效果有提升。
推理:也需要先把待预测图像分割成48×48的小图,输入模型,然后把结果整理还原为完整图像,再和专家标注结果进行对比。代码中以测试集第一张图片为例,可自行修改为其他眼底图片路径。
2.完整代码
import numpy as np
import cv2
from PIL import Image
import matplotlib.pyplot as plt
import os
from keras.models import Model
from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, UpSampling2D, Reshape, core, Dropout
from keras.optimizers import Adam, SGD
from keras.callbacks import ModelCheckpoint, LearningRateScheduler
from keras import backend as K
img_x, img_y = (576, 576)
dx = 48
filelst = os.listdir('DRIVE/training/images/')
filelst = ['DRIVE/training/images/'+v for v in filelst]
imgs = [cv2.imread(file) for file in filelst]
filelst = os.listdir('DRIVE/training/1st_manual/')
filelst = ['DRIVE/training/1st_manual/'+v for v in filelst]
manuals = [np.asarray(Image.open(file)) for file in filelst]
imgs = [cv2.resize(v,(img_x, img_y)) for v in imgs]
manuals = [cv2.resize(v,(img_x, img_y)) for v in manuals]
X_train = np.array(imgs)
Y_train = np.array(manuals)
X_train = X_train.astype('float32')/255.
Y_train = Y_train.astype('float32')/255.
X_train = X_train[...,1] # the G channel
X_train = np.array([[X_train[:,v*dx:(v+1)*dx, vv*dx:(vv+1)*dx] for v in range(img_y//dx)] for vv in range(img_x//dx)]).reshape(-1,dx,dx)[:,np.newaxis,...]
Y_train = np.array([[Y_train[:,v*dx:(v+1)*dx, vv*dx:(vv+1)*dx] for v in range(img_y//dx)] for vv in range(img_x//dx)]).reshape(-1,dx*dx)[...,np.newaxis]
temp = 1-Y_train
Y_train = np.concatenate([Y_train,temp],axis=2)
def unet_model(n_ch,patch_height,patch_width):
inputs = Input(shape=(n_ch,patch_height,patch_width))
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(inputs)
conv1 = Dropout(0.2)(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv1)
pool1 = MaxPooling2D((2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool1)
conv2 = Dropout(0.2)(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv2)
pool2 = MaxPooling2D((2, 2))(conv2)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool2)
conv3 = Dropout(0.2)(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv3)
up1 = UpSampling2D(size=(2, 2))(conv3)
up1 = concatenate([conv2,up1],axis=1)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(up1)
conv4 = Dropout(0.2)(conv4)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv4)
up2 = UpSampling2D(size=(2, 2))(conv4)
up2 = concatenate([conv1,up2], axis=1)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(up2)
conv5 = Dropout(0.2)(conv5)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv5)
conv6 = Conv2D(2, (1, 1), activation='relu',padding='same',data_format='channels_first')(conv5)
conv6 = core.Reshape((2,patch_height*patch_width))(conv6)
conv6 = core.Permute((2,1))(conv6)
conv7 = core.Activation('softmax')(conv6)
model = Model(inputs=inputs, outputs=conv7)
return model
model = unet_model(X_train.shape[1],X_train.shape[2],X_train.shape[3])
model.summary()
checkpointer = ModelCheckpoint(filepath='best_weights.h5', verbose=1, monitor='val_acc',
mode='auto', save_best_only=True)
model.compile(optimizer=Adam(lr=0.001), loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=64, epochs=20, verbose=2,shuffle=True, validation_split=0.2,
callbacks=[checkpointer])
imgs = cv2.imread('DRIVE/test/images/01_test.tif')[...,1] #the G channel
imgs = cv2.resize(imgs,(img_x, img_y))
manuals = np.asarray(Image.open('DRIVE/test/1st_manual/01_manual1.gif'))
X_test = imgs.astype('float32')/255.
Y_test = manuals.astype('float32')/255.
X_test = np.array([[X_test[v*dx:(v+1)*dx, vv*dx:(vv+1)*dx] for v in range(img_y//dx)] for vv in range(img_x//dx)]).reshape(-1,dx,dx)[:,np.newaxis,...]
model.load_weights('best_weights.h5')
Y_pred = model.predict(X_test)
Y_pred = Y_pred[...,0].reshape(img_x//dx,img_y//dx,dx,dx)
Y_pred = [Y_pred[:,v,...] for v in range(img_x//dx)]
Y_pred = np.concatenate(np.concatenate(Y_pred,axis=1),axis=1)
Y_pred = cv2.resize(Y_pred,(Y_test.shape[1], Y_test.shape[0]))
plt.figure(figsize=(6,6))
plt.imshow(Y_pred)
plt.figure(figsize=(6,6))
plt.imshow(Y_test)
3.运行结果
Epoch 7/20
- 1s - loss: 0.1522 - acc: 0.9509 - val_loss: 0.1013 - val_acc: 0.9660
Epoch 00007: val_acc improved from 0.96389 to 0.96602, saving model to best_weights.h5
......
这里给出测试集中第一张01_test.tif)
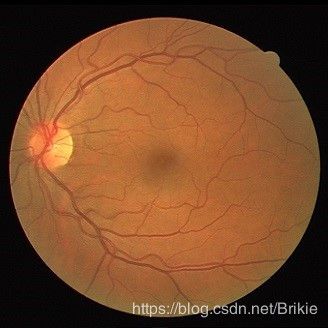
其标注结果01manual1.gif :
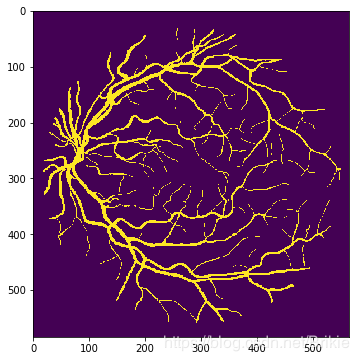
预测结果为:
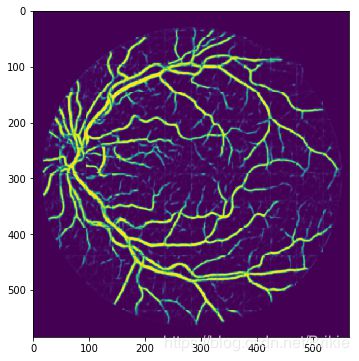
4.进一步讨论:
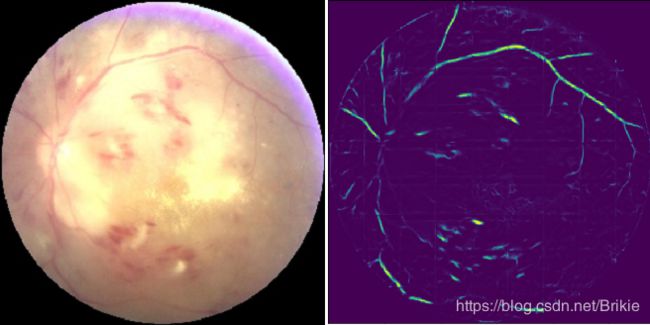
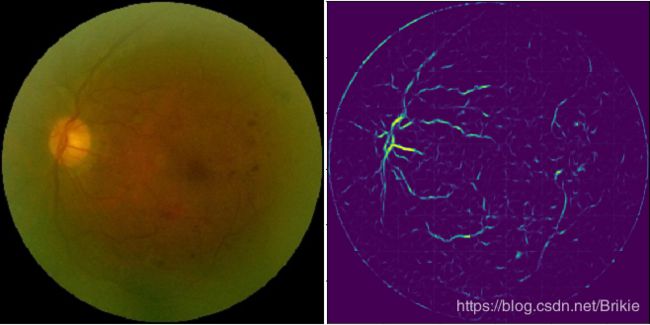
从上面的结果看,预测和标注值还是比较一致的,隐约可看到小图片的拼接线,如果小图片尺寸更改为64×64,拼接线会轻的多。下面用全部40张(包含测试集)进行训练,然后来处理一些其他眼底图像数据集的图片。这里选择了odir2019的几张图片。可以看出,血管分割的效果还是比较好的,但是有出血点或者屈光介质严重浑浊情况下效果会降低(训练集中没有这些情况)。