OpenStack技术和实战详解


谈到OpenStack,大家对其多多少少都有所了解,其常见的服务包括Nova、Swift、Glance、Keystone、Neutron、Cinder、Horizon、Ceilometer、Heat、Trove、TripleO、Sahara等等。
Nova:提供Compute(计算服务),主要的作用是管理虚拟机实例的整个生命周期,根据用户需求来提供虚拟服务。
Glance:提供 Image Service(镜像管理服务),镜像服务器是一套虚拟机镜像发现、注册、检索系统,但它不提供镜像文件的存储功能。
Swift:提供Object Storage(对象存储服务),存储数量到一定级别,而且是非结构化数据,通常才会有使用对象存储的需求。镜像文件通常存储在Swift中。
其中Ceilometer为计量服务,能把OpenStack内部发生的几乎所有的事件都收集起来,然后为计费和监控以及其他服务提供数据支持,今天我们主要谈的也是Ceilometer服务。
Ceilometer模块主要负责OpenStack的“计量”、“监控”以及“告警”功能。
计量主要负责和计费相关的指标度量采集和存储;
监控主要负责和非计费相关的指标、状态的采集和存储;
告警可分为性能相关的告警分析产生以及通过插件在openstack各服务运行时及时产生的故障。
Ceilometer功能是以数据库和消息队列为中心的数据采集、订阅分析和存储、分发一系列活动。Ceilometer主要组成部分有:
ceilometer-api: 向用户展示聚合后的数据
ceilometer-polling:使用polling plug-in去获取数据
ceilometer-agent-central:调用不同的组件的API以监控某种资源是否存在(L版本后不使用)
ceilometer-agent-compute:监控Hypervisor或者libvirt以获取实例的性能数据,并通过MQ发布出去(L版本后不再使用)
ceilometer-agent-ipmi:利用服务器上的IPMI传感器获取物理机信息(L版本后不再使用)
ceilometer-agent-notification:从MQ获取其他组件的消息
ceilometer-collector:从MQ获取ceilometer其他agent的信息,并将这些数据分配到不同的数据库。
ceilometer-alarm-X:告警相关
除了ceilometer-agent-compute和ceilometer-agent-ipmi,其他组件都要部署在一个或者多个控制节点,ceilometer高度依赖MQ服务,包括组件之间和组件内部。Ceilometer的主要功能是数据收集和数据处理。
Ceilometer的数据采集方式主要分为Poll和Push方式两种。

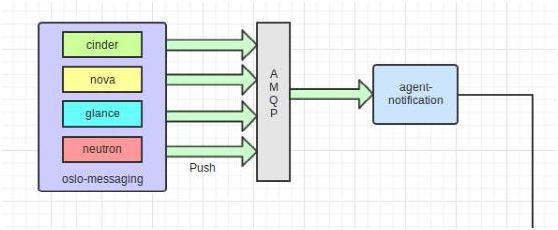
其中Push方式主要采集为OpenStack中各个组件模块中无法定时主动获取的事件消息,例如,虚拟机的创建,镜像的上传等等。该种方式的消息的采集依赖各个组件在事件发生时,依赖Ceilometer提供的消息机制将事件消息上报至消息队列当中。
然后由Ceilometer-Collector中的notification-agent收集消息队列中的事件消息,然后交由指定的Pipeline将消息转换为指定的采样数据(Samples),转换之后的采样数据会被重新发送至消息队列当中,然后由Collector收集处理并存入数据库当中(MongoDB)。主要架构如下图:
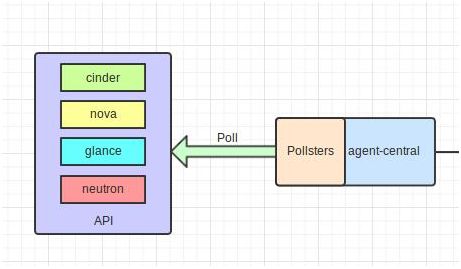
Poll方式主要采集OpenStack中的各个组件的统计数据和计算节点中的实时数据(该数据也是可以被随时统计获取的)。
在Controller节点上,Poll方式主要是启动相应的轮询进程(Pollsters),依靠轮询进程定期调用组件模块的APIs获取各个组件的数据信息。然后将数据交由Pipeline进行处理,最后由Collector处理存储。此过程与上述Push方式一致。
在Compute节点上,Poll方式也是启动相应的轮询进程(Pollsters),依靠轮询进程定期查询相应的信息,只是在数据采集方式上,采用虚拟机的相关驱动获取虚拟机的信息,目前主要的部署方案都是采用KVM-QEMU实现虚拟化,因此,底层信息获取上,采用的为LibVirt操纵虚拟机,同时也是通过LibVirt获取虚拟机的相关信息。当数据被采集之后,其之后的处理流程与上述两种方式都是一致的。
前面的数据采集工作完成之后,采集来的数据会交由Pipeline进行数据处理,Pipeline主要实现的是一个数据处理链的功能。Pipeline会根据不同的配置将0个或一个或多个Transformers组装成为一条数据处理链,在这条数据处理链的末端,会被装配一个Publisher。
当数据进入这条数据处理链后,会被Transformers加工处理,然后由Publisher发送至消息队列当中,由Collector收集。
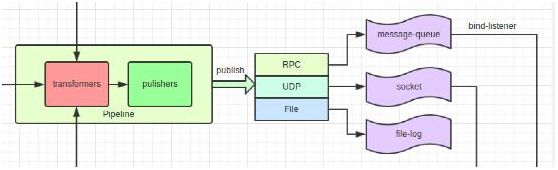
Collector会时刻监听着消息队列,从消息队列中获取监控数据,然后将数据存入MongoDB中进行持久化。
OpenStack不但是开源私有云的实际标准,而且已经广泛的应用在各个行业,包括社区版和厂商企业版。
在OpenStack大规模部署,特性丰富,并逐步走向商用的过程中,有很多经验和方法论值得参考和借鉴。笔者基于实战和网络资料,对OpenStack及相关知识进行了梳理,整理成书(OpenStack技术和实战详解),供学习者学习和参考。





点击阅读原文链接获取(OpenStack技术和实战详解)电子书详细信息。
相关阅读:
如果使用Docker还需要OpenStack吗?
OpenStack关键技术知识科普
温馨提示:
请搜索“ICT_Architect”或“扫一扫”二维码关注公众号,点击原文链接获取更多技术文章。

求知若渴, 虚心若愚
