python实战之Redis(RabiitMQ VS Redis,Redis上操作(String,Hash,List,Set,Sort Set),Python操作Redis,实现RPC)
上一篇:Python实战之RabiitMQ消息队列 点击跳转
目录篇:python相关目录篇 点击跳转
下一篇:主流数据库介绍 点击跳转
同类篇:python实战之Queue队列模块 点击跳转
目录
- RabiitMQ VS Redis
- 简要对比
- Redis
- 一.Linux上Redis简单安装和基本使用
- 二.使用Linux Python程序的pip进行Redis 安装
- Linux redis上试验
- 试验String操作
- 试验Hash操作
- 试验List操作
- 试验Set操作
- 试验Zset操作
- 其他常用操作
- Python操作Redis
- redis发布订阅
- redis自动持久化配置:
RabiitMQ VS Redis
本文仅针对RabbitMQ与Redis做队列应用时的情况进行对比
具体采用什么方式实现,还需要取决于系统的实际需求
简要对比
RabbitMQ
RabbitMQ是实现AMQP(高级消息队列协议)的消息中间件的一种,最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
Redis
是一个Key-Value的NoSQL数据库,开发维护很活跃,虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用。
具体对比
可靠消费
Redis:没有相应的机制保证消息的消费,当消费者消费失败的时候,消息体丢失,需要手动处理
RabbitMQ:具有消息消费确认,即使消费者消费失败,也会自动使消息体返回原队列,同时可全程持久化,保证消息体被正确消费
可靠发布
Reids:不提供,需自行实现
RabbitMQ:具有发布确认功能,保证消息被发布到服务器
高可用
Redis:采用主从模式,读写分离,但是故障转移还没有非常完善的官方解决方案
RabbitMQ:集群采用磁盘、内存节点,任意单点故障都不会影响整个队列的操作
持久化
Redis:将整个Redis实例持久化到磁盘
RabbitMQ:队列,消息,都可以选择是否持久化
消费者负载均衡
Redis:不提供,需自行实现
RabbitMQ:根据消费者情况,进行消息的均衡分发
队列监控
Redis:不提供,需自行实现
RabbitMQ:后台可以监控某个队列的所有信息,(内存,磁盘,消费者,生产者,速率等)
流量控制
Redis:不提供,需自行实现
RabbitMQ:服务器过载的情况,对生产者速率会进行限制,保证服务可靠性
出入队性能
对于RabbitMQ和Redis的入队和出队操作,各执行100万次,每10万次记录一次执行时间。
测试数据分为128Bytes、512Bytes、1K和10K四个不同大小的数据。
注:此数据来源于互联网,部分数据有误,已修正
应用场景分析
Redis:轻量级,高并发,延迟敏感
即时数据分析、秒杀计数器、缓存等
RabbitMQ:重量级,高并发,异步
批量数据异步处理、并行任务串行化,高负载任务的负载均衡等
将redis发布订阅模式用做消息队列和rabbitmq的区别:
- 可靠性
- redis :没有相应的机制保证消息的可靠消费,如果发布者发布一条消息,而没有对应的订阅者的话,这条消息将丢失,不会存在内存中;
- rabbitmq:具有消息消费确认机制,如果发布一条消息,还没有消费者消费该队列,那么这条消息将一直存放在队列中,直到有消费者消费了该条消息,以此可以保证消息的可靠消费,那么rabbitmq的消息是如何存储的呢?(后续更新);
- 实时性
- redis:实时性高,redis作为高效的缓存服务器,所有数据都存在在服务器中,所以它具有更高的实时性
- 消费者负载均衡:
- rabbitmq队列可以被多个消费者同时监控消费,但是每一条消息只能被消费一次,由于rabbitmq的消费确认机制,因此它能够根据消费者的消费能力而调整它的负载;
- redis发布订阅模式,一个队列可以被多个消费者同时订阅,当有消息到达时,会将该消息依次发送给每个订阅者;
- 持久性
- redis:redis的持久化是针对于整个redis缓存的内容,它有RDB和AOF两种持久化方式(redis持久化方式,后续更新),可以将整个redis实例持久化到磁盘,以此来做数据备份,防止异常情况下导致数据丢失。
- rabbitmq:队列,消息都可以选择性持久化,持久化粒度更小,更灵活;
- 队列监控
- rabbitmq实现了后台监控平台,可以在该平台上看到所有创建的队列的详细情况,良好的后台管理平台可以方面我们更好的使用;
- redis没有所谓的监控平台。
- 总结
- redis: 轻量级,低延迟,高并发,低可靠性;
- rabbitmq:重量级,高可靠,异步,不保证实时;
- rabbitmq是一个专门的AMQP协议队列,他的优势就在于提供可靠的队列服务,并且可做到异步,而redis主要是用于缓存的,redis的发布订阅模块,可用于实现及时性,且可靠性低的功能
Redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
redis最高一台机器每秒读取和写入:10W和8W数据
-
一.Linux上Redis简单安装和基本使用
[root@python redis-3.0.6]# yum -y install gcc gcc-c++ libstdc++-devel
[root@python ~]# cd /home/burgess/tools/
[root@python tools]# wget http://download.redis.io/releases/redis-3.0.6.tar.gz
[root@python tools]# tar xzf redis-3.0.6.tar.gz
[root@python tools]# mv redis-3.0.6 /usr/local/
[root@python tools]# cd /usr/local/redis-3.0.6/
[root@python redis-3.0.6]make
[root@python ~]# ln -s /usr/local/redis-3.0.6/src/redis-server /usr/bin/
[root@python ~]# ln -s /usr/local/redis-3.0.6/src/redis-cli /usr/bin/
启动服务端
redis-server启动客户端
redis-cli

-
二.使用Linux Python程序的pip进行Redis 安装
[root@python redis-3.0.6]# pip3 install redis
通过windows的python程序的pip进行 Redis安装

Linux redis上试验
由于从自己的笔记颜色区分就直接切图,太多了
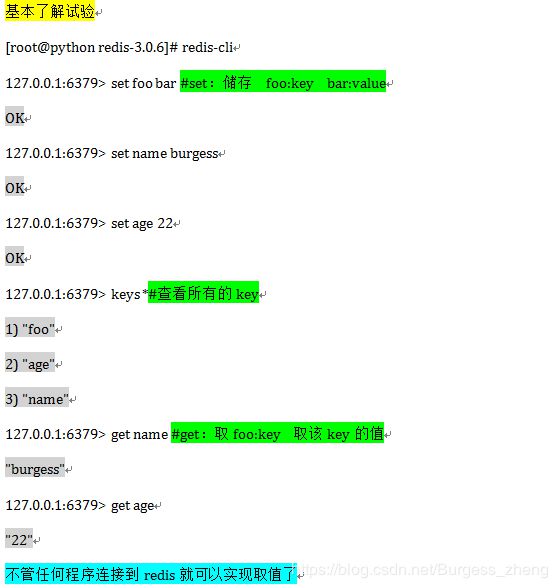

-
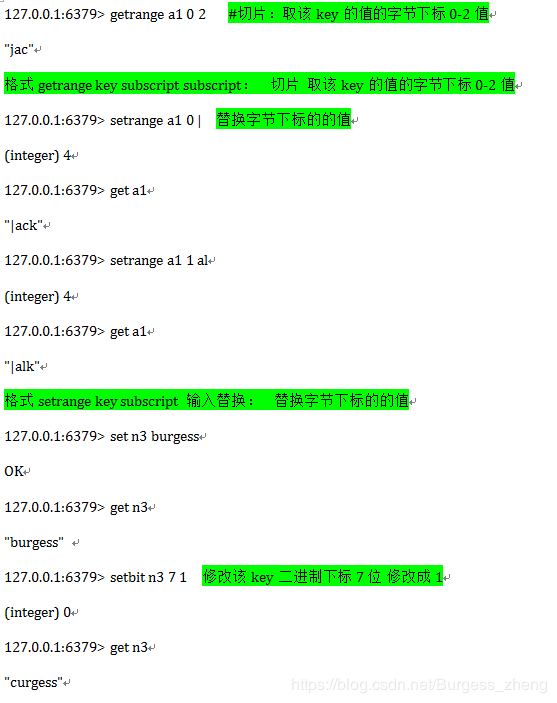
试验String操作
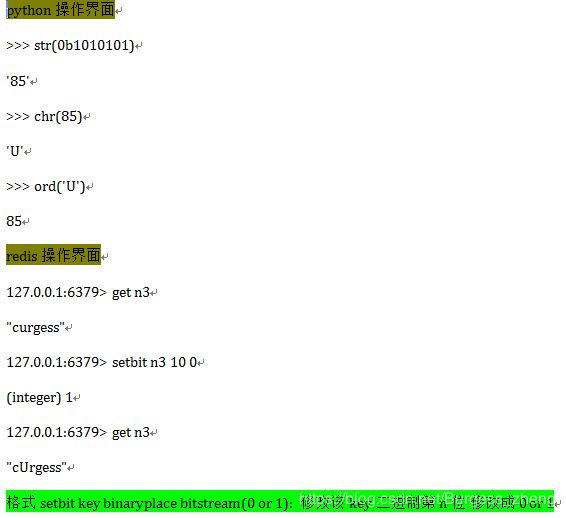
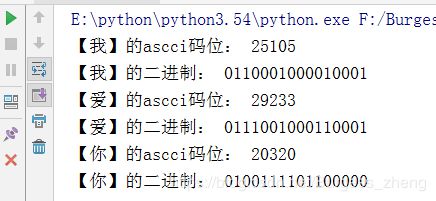
插入:中文转二进制实现(扩展)
执行结果:
插入:巨牛逼的应用场景二进制统计用户数量和查看那些用户在线,假如新浪微博在线用户很多,做数据分析,统计用户在线数量,和那些用户在线
为什么效率高?只需要2亿这个数字就可以统计如此庞大的用户数量,且可以知道谁在线 而且基本不占用资源,如操作一条命令一样
1字节8位 1000字节 1KB 1000KB =1M = 1000*1000=1000000 字节
10M=1千万字节*8=8000二进制位 30M就可以就可以存2.4亿个用户的在线列表
如果通过数据库统计,就要最少几百M的问题且慢
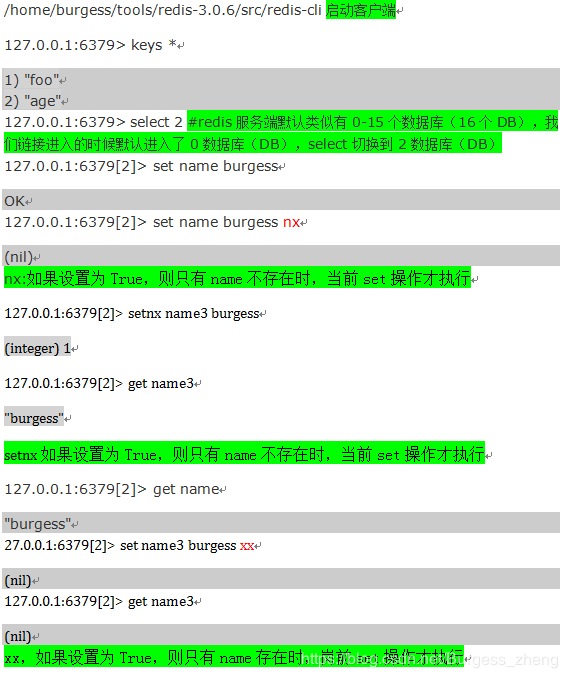
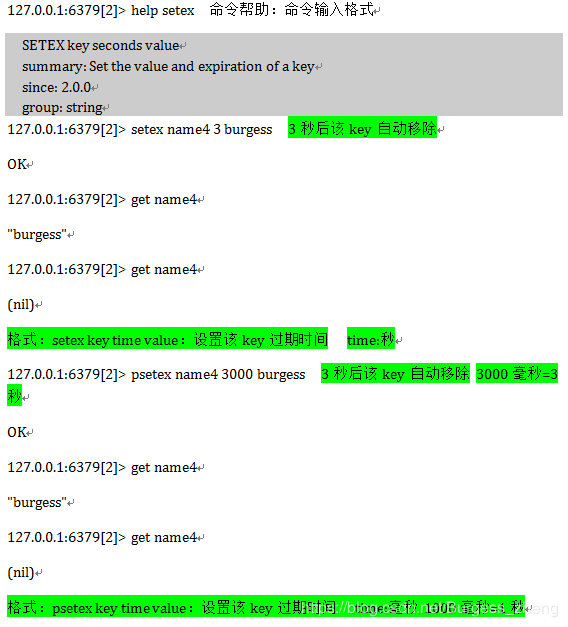
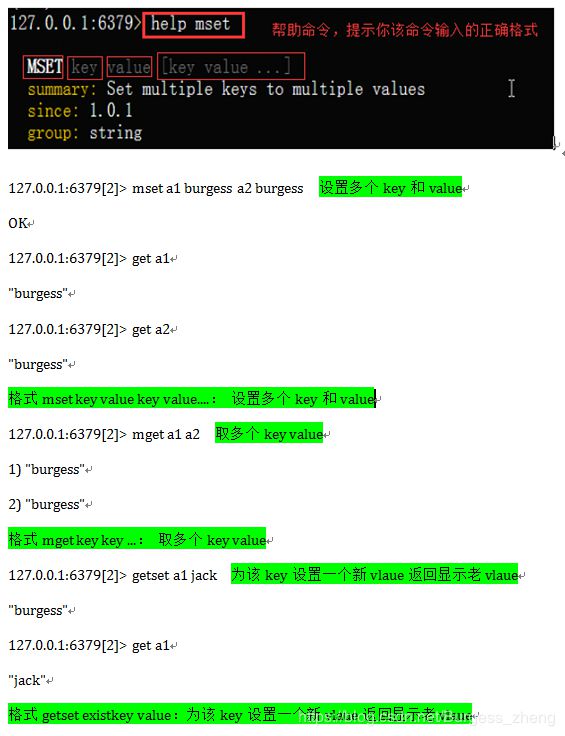






-
试验Hash操作
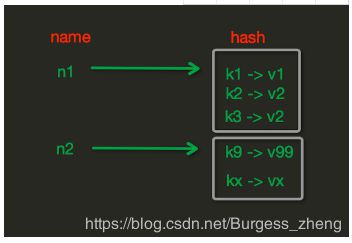
Hash操作,redis中Hash在内存中的存储格式如下图:






-
试验List操作
redis中的List在在内存中按照一个name对应一个List来存储。如图:



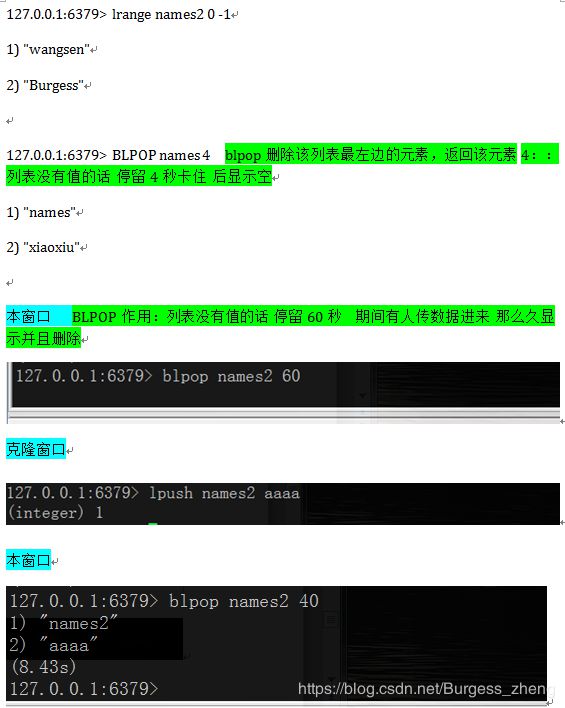


-
试验Set操作
Set集合就是不允许重复的列表




-
试验Zset操作
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。



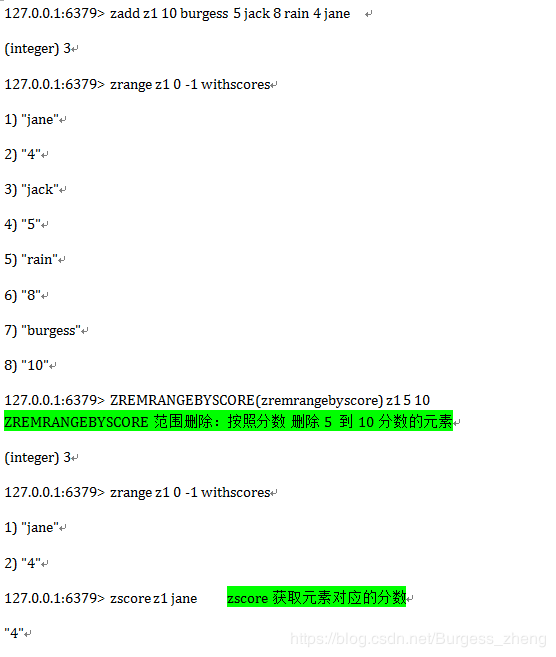
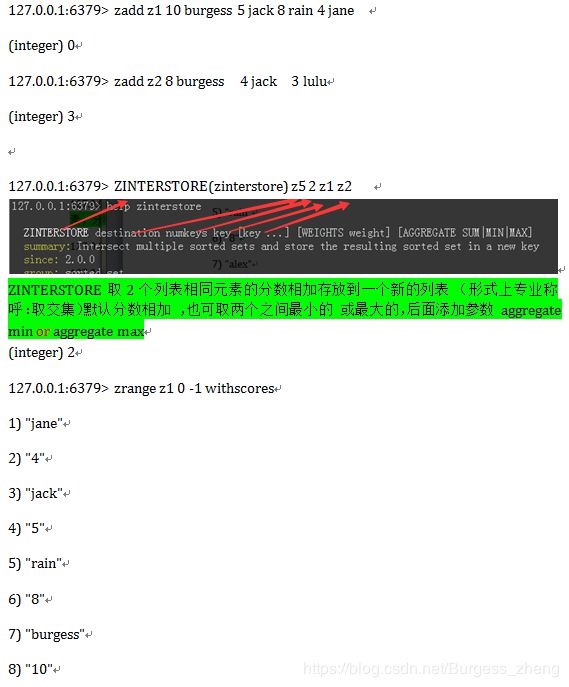

-
其他常用操作

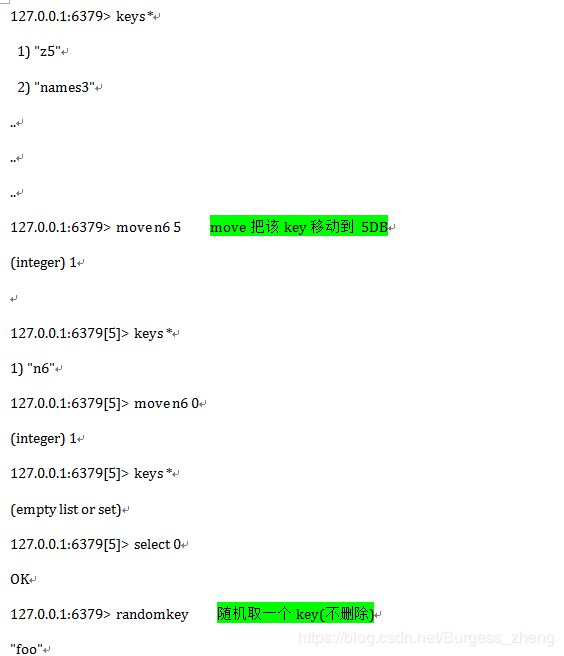


Python操作Redis
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
__author__ = "Burgess Zheng" # !/usr/bin/env python # -*- coding:utf-8 -*- import redis ##r = redis.Redis(host='10.0.0.150', port=6379, db=0, password=’’) r = redis.Redis(host='10.0.0.150', port=6379) r.set('foo', 'Bar') print(r.get('foo'))执行结果:
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
__author__ = "Burgess Zheng" # !/usr/bin/env python # -*- coding:utf-8 -*- import redis ##pool = redis.ConnectionPool(host='localhost', port=6379, db=0, password=’’) pool = redis.ConnectionPool(host='localhost', port=6379) r = redis.Redis(connection_pool=pool) r.set('foo', 'Bar') print(r.get('foo'))执行结果:
3.redis管道通过python小实验
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作
__author__ = "Burgess Zheng" # !/usr/bin/env python # -*- coding:utf-8 -*- import time import redis ##pool = redis.ConnectionPool(host='localhost', port=6379, db=0, password=’’) pool = redis.ConnectionPool(host='0.0.0.0', port=6379)#新建连接池 r = redis.Redis(connection_pool=pool)#实例化一个连接 # pipe = r.pipeline(transaction=False) pipe = r.pipeline(transaction=True)#生成一个管道 pipe.set('name', 'burgess')#设置key 和value 装进管道 pipe.set('role', 'sb')#设置key和value 装进管道 pipe.execute()#管道执行执行结果

-
redis发布订阅
我们学了rabbitMQ 1对多的广播
1对多的广播 学名:发布订阅 redis发布订阅和rabbitMQ 发布订阅效果是一样的
代码不一样而已
5、发布订阅
发布者:服务器
订阅者:Dashboad和数据处理
试验redis发布和订阅
help端
__author__ = "Burgess Zheng" #!/usr/bin/env python -*- coding:utf-8 -*- import redis class RedisHelper: def __init__(self): ## pool = redis.ConnectionPool(host='localhost', port=6379, db=0, password=’’) ## self.__conn = redis.Redis(connection_pool=pool) self.__conn = redis.Redis(host='0.0.0.0') self.chan_sub = 'fm104.5' self.chan_pub = 'fm104.5' #初始化连接redis服务器 一个发布 一个是订阅 def public(self, msg):#发布的方法 self.__conn.publish(self.chan_pub, msg) #连接redis服务器.发布:key:self.chan_pub value:msg #self.chan_pub = 'fm104.5' #由于publiser 发布了'hello' #相当于是redis里操作等于 publish fm104.5 hello return True def subscribe(self):#订阅的方法 pub = self.__conn.pubsub()#开始订阅 pub.subscribe(self.chan_sub)#连接到订阅的频道 pub.parse_response()#准备接收 return pub发布端
__author__ = "Burgess Zheng" # !/usr/bin/env python # -*- coding:utf-8 -*- from redis_helper.RedisHelper import RedisHelper obj = RedisHelper()#实例化一个实例 obj.public('hello') #调用服务器的RedisHelper类的public方法 #hello字符串作为传参接收端
__author__ = "Burgess Zheng" # !/usr/bin/env python # -*- coding:utf-8 -*- from redis_helper.RedisHelper import RedisHelper obj = RedisHelper()#实例化一个实例 redis_sub = obj.subscribe()#调用父类的dubscribe方法进行赋值 while True:#不断循环 msg = redis_sub.parse_response() #阻塞的 #启动父类的dubscribe方法的parse_response功能 # 简单理解就是接收数据 赋值给mgs print(msg)执行结果

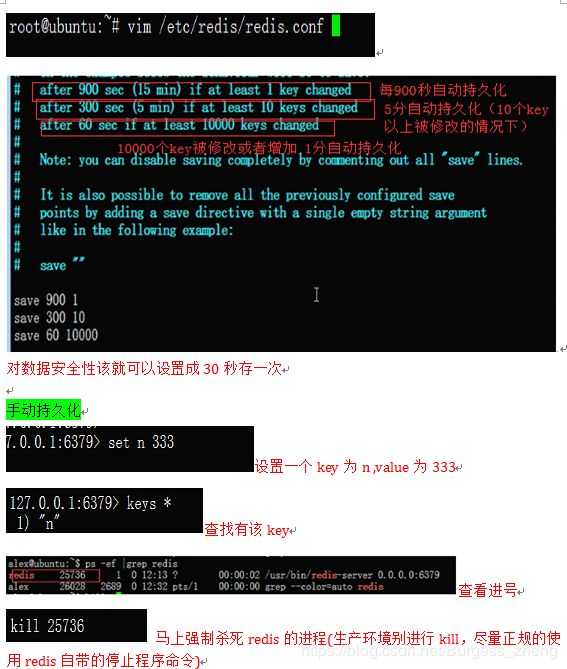
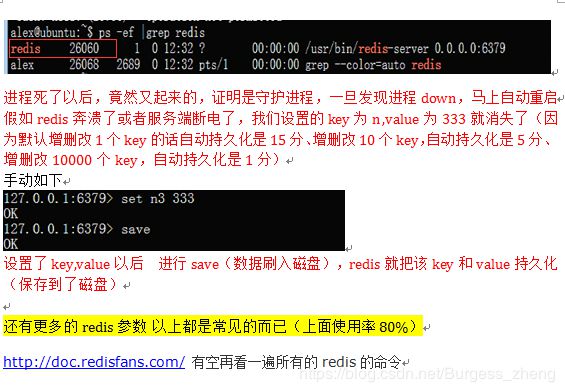
redis自动持久化配置:
上一篇:Python实战之RabiitMQ消息队列 点击跳转
目录篇:python相关目录篇 点击跳转
下一篇:主流数据库介绍 点击跳转
同类篇:python实战之Queue队列模块 点击跳转