Django之Model操作之select_related和prefetch_related【ORM篇八】
上一篇:Django之Model操作之单表及跨表(双下划线)的3种不同方式获取数据【ORM篇七】 点击跳转
目录篇:Django之model操作ORM目录篇 点击跳转
下一篇:Django之Model操作汇总【ORM汇总篇九】 点击跳转
目录
- 实战跳转:
- 简单理解示例:
在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能。本文通过一个简单的例子详解这两个函数的作用。虽然QuerySet的文档中已经详细说明了,但本文试图从QuerySet触发的SQL语句来分析工作方式,从而进一步了解Django具体的运作方式
实战跳转:
实战Django之Model操作之 select_related 查询的优化(一)点击跳转
实战Django之Model操作之 prefetch_related()查询的优化(二)点击跳转
实战Django之Model操作之select_related 和 prefetch_related最佳实践(三)点击跳转
上面在csdn上看见别人已经写过select_related和prefetch_related的实例演示,由于写得非常好,就懒得自己在实战,都差不多,但是有些欠缺说明就在这里说下:(如果跳转的实战看不是很理解的话,该文章最下有简单详解,可以看下)
1.一个queryset对象是没有进行sql操作,只有被调用的时候才进行sql操作
2.查看调用后以及循环在调用外键的queryset对象的sql次数以及原sql代码我们可以使用django_debug_toolbar
没有使用select_related:4次sql操作(单表对象1次,外键3次调用)。如上
使用select_related:同样的对象只链接一次sql操作。如下
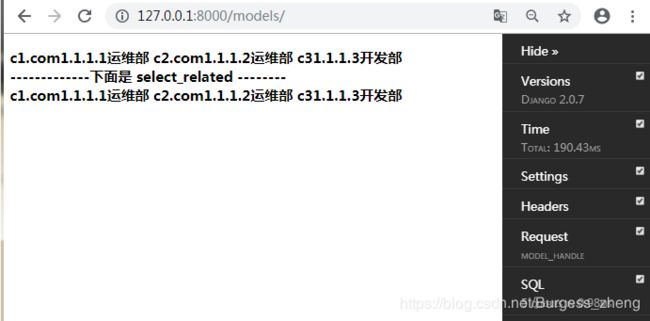


select_related()总结
1.select_related主要针一对一和多对一关系进行优化。
2.select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。
3.可以通过可变长参数指定需要select_related的字段名。也可以通过使用双下划线“__”连接字段名来实现指定的递归查询。没有指定的字段不会缓存,没有指定的深度不会缓存,如果要访问的话Django会再次进行SQL查询。
4.也可以通过depth参数指定递归的深度,Django会自动缓存指定深度内所有的字段。如果要访问指定深度外的字段,Django会再次进行SQL查询。
5.也接受无参数的调用,Django会尽可能深的递归查询所有的字段。但注意有Django递归的限制和性能的浪费。
6.Django >= 1.7,链式调用的select_related相当于使用可变长参数。Django < 1.7,链式调用会导致前边的select_related失效,只保留最后一个
prefetch_related()总结
1.prefetch_related主要针一对多和多对多关系进行优化。
2.prefetch_related通过分别获取各个表的内容,然后用Python处理他们之间的关系来进行优化。
3.可以通过可变长参数指定需要select_related的字段名。指定方式和特征与select_related是相同的。
4.在Django >= 1.7可以通过Prefetch对象来实现复杂查询,但低版本的Django好像只能自己实现。
5.作为prefetch_related的参数,Prefetch对象和字符串可以混用。
6.prefetch_related的链式调用会将对应的prefetch添加进去,而非替换,似乎没有基于不同版本上区别。
7.可以通过传入None来清空之前的prefetch_related
简单理解示例:
select_related原理解析及使用
#假如有用户表(10用户) 和 用户类型表 使用了ForeignKey进行关联
obj = mode.User.object.all() #拿到了用户表执行了1次sql语句
for row in obj
row.外键_id.类型表字段(caption)
#这样循环调用foreignkey: ==执行了10次sql语句
#总共就执行了11次sql#如果用户表同时也和部门表进行foreignkey进行关联
for row in obj
row.外键_id(类型表).类型表字段(caption)
row.外键_id(部门表).类型表字段(caption)
#就等于执行了21次sql
#得到结论:如果foreignkey多个表,这样性能就非常之低#解决:使用select_related
model.User.objects.all().select_related()
model.User.objects.all().select_related('外键字段')#记住括号不能加普通字段
model.User.objects.all().select_related('外键字段__外键字段')
#+.select_related()等于把所有的外键的表的数据也同时拿了过来放在内存里面,这样以后for循环调用外键信息就不用在执行sql操作。
#类似于values和values_list,先拿了放在内存,没拿到的字段就操作不了
#我们都知道用户表可以和类型表进行关联 类型表也是可以跟其他的表关联
#所以也可以一次行把类型表关联的表拿过来
#总结:select_related内部执行了1次连表sql操作而已(select_related是主动做连表(跨表)操作)
如下:
model.User.objects.all().select_related() #内部执行原生连表sql一次获取本身该表和关联表的所有数据放到内存
for row in obj
row.外键_id(类型表).类型表字段(caption)
row.外键_id(部门表).类型表字段(caption)
#在进行外键提取的时候其实是在内存提取,所以不在执行sql语但是:连表(跨表)操作会有性能的消耗
比如:你单表取查询数据和你连表查询数据,性能会差很多,速度会差很多,你在连一张表速度又会差更多,所以能查到数据,但是性能不高
所以性能低了有什么解决方法吗?有:这里就引出了prefetch_related
prefetch_related原理解析及使用
select_related是主动做连表(跨表)操作(内部执行sql连表操作)
#假如有10个用户,100个用户类型,但是用户表的所有用户只是关联了其中几个类型
等于如果django使用了select_related该操作的时候内部是执行了原生连表sql如下:
执行原生连表sql: select * from User INNER JOIN UserType on User.字段 = UserType.字段
然后django拿到了sql连表的数据以后放到了内存,提出的时候就不用再进行sql了
直接是在内存拿,这样比我们之前普通多次执行sql效率就高了很多
(缺点:
1但是如果User表所有用户可能关联只是类型表其中N个类型,而类型表还有很多类型没有被关联的,也会同样被提取放在内存,占用内存空间
2.sql的连表操作比单表操作差很多
)
# 获取所有用户表
# 获取用户类型表where id in (用户表中的查到的所有用户ID)
models.UserInfo.objects.prefetch_related('外键字段')
prefetch_related(内部不执行sql连表操作,而是执行多次单表sql语句然后拼起来)
#假如有10个用户,100个用户类型,但是用户表所有用户只是关联了其中几个类型
#1.先执行原生单表sql语句拿到User表所有的数据. 放在内存
如:执行sql: select * fromUser
#在使用python代码把用户表ForeignKey该字段的所有用户关联类型表的id提取出来去重放到了内存的列表里面
#用户类型ID[1,2]
#2.在继续执行原生单表sql语句拿到UserType表所有数据
如:执行sql : select * from UserType where id in [1,2]
#[1,2]是第一次sql操作python提取出来的放在内存,这样不会提取一些没有被关联的类型
这里我们就发现了区别了 如果UserType表有100条类型 ,但是User表所有的用户只是关联了1和2的类型 ,其他类型没有关联,那么就不会被提取出来
注意:虽然是执行了2次单表sql查询,
第1次单表sql获取的是User表全部的数据
第2次单表sql是根据指定的判断获取了指定的外键表数据
看似select_relaed是1次sql查询(是连表的sql) 而prefetch_related是两次sql
次数看似select_related少 其实执行2次单表sql操作要比1次连表sql操作快多了
(优点:
1只拿用户所关联的类型表的数据,没关联的类型表的数据不会拿,不会浪费内存空间
2.多次单表查询不一定比1次连表查询慢
)
#django两次拿到的数据进行了拼接
总结:prefetch_related内部执行了多次sql单表操作然后放在内存
如下:
model.User.objects.all().prefetch_related ()#内部执行多次原生单表sql获取本身该表所有数据和指定关联数据放到内存里面
for row in obj
row.外键_id(类型表).类型表字段(caption)
row.外键_id(部门表).类型表字段(caption)
#在进行外键提取的时候其实是在内存提取,所以不在执行sql语句
select_related prefetch_related非常之重要
上一篇:Django之Model操作之单表及跨表(双下划线)的3种不同方式获取数据【ORM篇七】 点击跳转
目录篇:Django之model操作ORM目录篇 点击跳转
下一篇:Django之Model操作汇总【ORM汇总篇九】 点击跳转