参考书籍:算法设计与分析——C++语言描述(第二版)
算法问题求解基础
1. 算法概述
算法(algorithm)是求解一类问题的任意一种特殊的方法。教严格的说法是,一个算法是对特定问题求解步骤的一种描述,它是指令的有限序列。
算法具有下面五个特征:
- 输入(input):算法有零个或多个输入量
- 输出(output):算法至少产生一个输出量
- 确定性(definiteness):算法的每一条指令都有确切的定义,没有二义性
- 能行性(effectiveness):算法的每一条指令必须足够基本,他们可以通过已经实现的基本运算执行有限次来实现
- 有穷性(finiteness):算法必须总能在执行有限步之后终止
概括地说,算法是由一系列明确定义的基本指令序列所描述的,求解特定问题的过程。它能够对合法的输入,在有限时间内产生所要求的输出。
如果取消有穷性限制,则只能称为计算过程(computational procedure)
欧几里德算法
- 欧几里德算法又称辗转相除法,用于计算两个整数mm和nn(0≤m<n的最大公约数,记为gcd(m,n)0≤m
#include
if(m == 0) {
return n;
} else {
int tmp;
while(m>0) {
tmp = n%m;
n = m;
m = tmp;
}
return n;
}
}
int Rgcd(int m, int n)
{
//递归形式
if(m == 0) {
return n;
} else {
return Rgcd(n%m, ma);
}
}
int main()
{
int m, n, r1, r2;
scanf("%d%d", &m, &n);
if(n>m) {
r1 = gcd(m,n);
r2 = Rgcd(m,n);
} else {
r1 = gcd(n,m);
r2 = Rgcd(n,m);
}
printf("GCD of m and n: %d\n", r1);
printf("GCD of m and n: %d\n", r2);
return 0;
} 一个好的算法应具有以下4个特性
- 正确性(correctness):算法的执行结果应当满足预先规定的功能和性能要求
- 简明性(simplicity):算法应思路清晰、层次分明、容易理解、利于编码和调试
- 效率(efficiency):算法应有效使用存储空间,并具有高的时间效率
- 最优性(optimality):算法的执行时间已达到求解该问题所需时间的下限
2. 算法设计与分析
算法一般分两类:精确算法和启发式算法。一个精确算法(exact algorithm)总能保证求得问题的解。而一个启发式算法(heuristic algorithm)通过使用某种规则、简化或智能猜测来减少问题的求解时间。
算法问题求解过程: 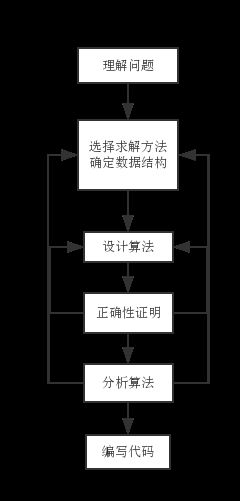
3. 递归和归纳
递归(recursive)定义是一种直接或间接引用自身的定义方法。一个合法的递归定义包括两个部分:基础情况(base case)和递归部分。
当一个算法采用递归方式定义时便成为递归算法,一个递归算法是指直接或间接调用自身的算法。递归本质上也是一种循环的算法结构,它把较复杂的计算逐次归结为较简单情形的计算,直至归结到最简单情形的计算,并最终得到计算结果为止。
递归数据结构:使用递归方式定义的数据结构称为递归数据结构(recursive data structure)。
使用归纳法进行证明的过程由两部分组成:
(1)基础情况(base case)确认被证明的结论在某种\某些基础情况下是正确的
(2)归纳步骤(induction step)这一步又可分成两子步:首先进行归纳假设,假定当问题实例的规模小于某个量k时,结论成立;然后使用这个假设证明对问题规模为k的实例,结论成立。至此结论得证。
练习
1. 逆序输出正整数的各位数(递归算法求解)
2. 汉诺塔问题
3. 排序产生算法
4. 给出n!n!的递归定义式,并设计一个递归函数计算n!n!
5. 写一个递归算法和一个迭代算法计算二项式系数:Cmn=Cmn−1+Cm−1n−1=n!m!(n−m)!Cnm=Cn−1m+Cn−1m−1=n!m!(n−m)!
6. 给定一个字符串s和一个字符x,编写递归算法实现下列功能:
(1)检查x是否在s中
(2)计算x在s中出现的次数
(3)删除s中所有的x
7. 写一个C++函数求解:给定正整数n,确定n是否是它所有因子之和
8. S是有n个元素的集合,S的幂集是S所有可能的子集组成的集合。例如, S=a,b,c,则S的幂集=(),(a),(b),(c),(a,b),(a,c),(b,c),(a,b,c)S=a,b,c,则S的幂集=(),(a),(b),(c),(a,b),(a,c),(b,c),(a,b,c)。写一个C++递归函数,以S为输入,输出S的幂集。
算法分析基础
1. 算法复杂度
一个好的算法应具有一下4个重要特性
- 正确性(correctness):算法的执行结果应当满足预先规定的功能和测试要求
- 简明性(simplicity):算法应思路清晰、层次分明、容易理解、利于编码和调试
- 效率(efficiency):算法应有效使用存储空间,并具有高的时间效率
- 最优性(optimality):算法的执行时间已达到求解该类问题所需的时间下界
程序健壮性(robustness):是指当输入不合法数据时,程序应能做适当处理而不至于引起严重后果。其含义是:当程序万一遇到意外时,能按某种预定方式做出适当处理。正确性和健壮性是相互补充的。
影响程序运行时间的因素主要有
- 程序所依赖的算法:算法自身的好坏对运行时间的影响是根本的和起决定作用的
- 问题规模和输入数据:输入数据规模、输出数据规模、数据的数值大小和输入数据的状态
- 计算机系统性能:计算机硬件系统性能(如CPU速度)、计算机软件系统性能(如操作系统、编译器)
算法的时间复杂度:一个算法的时间复杂度(time complexity)是指算法运行所需的时间。
算法的空间复杂度:一个算法的空间复杂度(space complexity)是指算法运行所需的存储空间。程序运行所需要的存储空间包括以下两部分:(1)固定空间需求(fixed space requirement),(2)可变空间需求(variable space requirement)。
2. 渐进表示法
大OO记号(渐近上界记号)
设函数f(n)f(n)和g(n)g(n)是定义在非负整数集合上的正函数,如果存在两个正常数cc和n0n0,使得当n≥n0n≥n0时,有f(n)≤cg(n)f(n)≤cg(n),则记作f(n)=O(g(n))f(n)=O(g(n)),称为大O记号(big Oh notation)。意义:该算法的运行时间不会超过g(n)的某个常数倍。
ΩΩ记号(渐近下界记号)
设函数f(n)f(n)和g(n)g(n)是定义在非负整数集合上的正函数,如果存在两个正常数cc和n0n0,使得当n≥n0n≥n0时,有f(n)≥cg(n)f(n)≥cg(n),则记作f(n)=Ω(g(n))f(n)=Ω(g(n)),称为ΩΩ记号(omega notation)。意义:该算法至少需要g(n)的某个常数倍大小的时间量。
ΘΘ记号(紧渐近界记号)
设函数f(n)f(n)和g(n)g(n)是定义在非负整数集合上的正函数,如果存在两个正常数c1c1、c2c2和n0n0,使得当n≥n0n≥n0时,有c1g(n)≤f(n)≤c2g(n)c1g(n)≤f(n)≤c2g(n),则记作f(n)=Θ(g(n))f(n)=Θ(g(n)),称为ΘΘ 记号(Theta notation)。意义:该算法实际运行时间大约为g(n)的某个常数倍大小的时间量。
小o记号(非紧上界记号)
f(n)=o(g(n))f(n)=o(g(n))当且仅的f(n)=O(g(n))f(n)=O(g(n))且f(n)≠Ω(g(n))f(n)≠Ω(g(n))。意义:该算法的运行时间f(n)的阶比g(n)低。
ωω记号(非紧下界记号)
如果对于任何正常数c>0c>0都存在正整数n0>0n0>0,使得当n≥n0n≥n0时有f(n)>cg(n)f(n)>cg(n)(等价于n→∞n→∞t时,f(n)/g(n)→∞f(n)/g(n)→∞),则称函数f(n)f(n)当nn充分大时的阶比g(n)g(n)高,记做f(n)=ω(g(n))f(n)=ω(g(n))。
算法按时间复杂度分类
算法按计算时间分为两类:凡渐进时间复杂度为多项式时间限界的算法称为多项式时间算法(polynomial time algorithm),而渐进时间复杂度为指数函数限界的算法称为指数时间算法(exponential time algorithm)
常见多项式时间算法的渐进时间复杂度之间的关系:
常见的指数时间算法的渐进时间复杂度之间的关系为:
3. 递推关系
递推方程(recurrence equation)是自然数上一个函数T(n)T(n),它使用一个或多个小于nn的值的等式或不等式来描述,也称递推关系或递推式。递推方程必须有一个初始条件(也称边界条件)。
计算递推式通常有三种方法:迭代方法(iterating)、替换方法(substitution)和主方法(master method)。
替换方法
替换方法要去首先猜测递推式的解,然后用归纳法证明。迭代方法
迭代方法的思想是扩展递推式,将递推式先转换成一个和式,得到渐进复杂度。主方法
主定理:设a≥1a≥1和b>1b>1为常数,f(n)f(n)是一个函数,T(n)T(n)由下面的递推式定义:T(n)=aT(n/b)+f(n)T(n)=aT(n/b)+f(n)
式中,n/bn/b指⌊n/b⌋⌊n/b⌋或⌈n/b⌉⌈n/b⌉,则T(n)T(n)有如下的渐进界:(1)若对某常数ϵ>0ϵ>0,有f(n)=O(nlogab−ϵ)f(n)=O(nlogba−ϵ),则T(n)=Θ(nlogab)T(n)=Θ(nlogba);
(2)若f(n)=Θ(nlogab)f(n)=Θ(nlogba),则T(n)=Θ(nlogablogn)T(n)=Θ(nlogbalogn);
(3)若对某常数ϵ>0ϵ>0,有f(n)=Ω(nloga+ϵb)f(n)=Ω(nlogba+ϵ),且对某个常数c<1c<1和所有足够大的nn,有af(n/b)≤cf(n)af(n/b)≤cf(n),则T(n)=Θ(f(n))T(n)=Θ(f(n))。练习
- 矩阵转置
(1)设计一个C/C++程序实现一个n×mn×m的矩阵转置。原矩阵保存在二维数组中。
(2)使用全局变量count,改写矩阵转置程序,并运行修改后的程序,以确定改程序的程序步
(3)计算此程序的渐进时间复杂度 - 证明:若f(n)=amnm+am−1nm−1+⋯+a1n+a0f(n)=amnm+am−1nm−1+⋯+a1n+a0是mm次多项式,且am>0am>0,则f(n)=Ω(nm)f(n)=Ω(nm).
- 运用主定理求T(n)=2T(n/4)+n−−√,T(1)=3T(n)=2T(n/4)+n,T(1)=3的渐进界
- 矩阵转置
伸展树与跳表
伸展树
二叉搜索树(binay search tree)是一颗二叉树,它要求根的左子树上的所有结点的值都小于根的值,右子树上所有的结点的值都大于根的值,并且左右子树都是二叉搜索树。
字典(dictionary)是词条的集合,词条包括关键字(key)和其他信息。字典作为一种数据结构,主要包括搜索、插入和删除等基本运算。
字典可以用二叉搜索树来表示,但该结构容易出现退化树形,使得搜索和修改的代价增大。二叉平衡树(binary balanced tree)是一种平衡搜索树,他需要在每次插入和删除元素之后,按规则重新平衡树形,使之始终保持平衡,从而限制树的高度,避免退化。
伸展树(splay tree)是一颗二叉搜索树,但要求每访问一个元素后,将最新访问的元素移到二叉搜索树的根部,从而保证经常被访问的元素靠近根节点,而较少访问的元素位于搜索树较低的层次上。所以这是一种自调整搜索树(self-adjusting search tree)。这种将一个元素移至根部的操作称为一次伸展(splay)。
在伸展树中,虽然某次运算(搜索、插入或删除)可能很费时,需要O(n)O(n)时间,但执行一个m(m≥n)m(m≥n)次的长运算序列,花费的总时间为O(mlogn)O(mlogn)(n是树中的元素个数),每个运算的平均分摊代价为(O(logn)O(logn))。
一颗伸展树是一颗二叉搜索树。它的搜索、插入和删除运算的算法与普通的二叉搜索树完全相同,只是在每次运算执行后,需要紧跟一次伸展操作。伸展操作结束,伸展结点成为树的根节点。可以按下列方式来确定伸展树运算的伸展结点。
- 搜索运算:搜索成功的结点x为伸展结点;
- 插入操作:新插入的结点x为伸展结点;
- 删除操作:被删除的结点x的双亲为伸展结点;
- 若上述运算失败终止,则搜索过程中遇到的最后一个结点为伸展结点。
一次伸展操作由一组旋转(rotation)动作组成,可分为单一旋转(single rotation)和双重旋转(double rotation)两类。
设q是本次伸展的伸展结点,
单一旋转
若q是p的左孩子或者q是p的右孩子,则执行单一旋转。前者称为zig旋转(右旋转),后者称为zag旋转(左旋转)。经过一次单一旋转,树的高度并未减小,只是将伸展结点向上移了一层。
双重旋转
- 第一种双重旋转称为一字旋转。如果伸展结点q是祖父结点的左孩子的左孩子,或是其祖父结点的右孩子的右孩子时,则执行双重旋转的一字旋转。前者称为zigzig旋转,后者称为zagzag旋转。经过一次一字旋转,树的高度并未减小,只是把伸展结点q的位置向上移了两层。
- 第二种双重旋转称之为之字旋转。如果伸展结点q是祖父结点的左孩子的右孩子,或是其祖父结点的右孩子的左孩子时,则执行双重旋转的之字旋转。前者称为zigzag旋转,后者称为zagzig旋转。经过一次之字旋转,树的高度减少1,且伸展结点q的位置上移,离根的距离减少了两层。
定义(秩):设x是伸展树T中的一个结点,s(x)s(x)是以x为根的子树的结点数,结点x的秩(rank)r(x)r(x)定义为:r(x)=log s(x)r(x)=log s(x)
定义(势能):设x是伸展树T中的一个结点,伸展树T的势能(potential)ϕϕ定义为树中所有结点的秩之和:ϕ=∑x∈Tr(x)ϕ=∑x∈Tr(x)
定义(分摊代价):设对伸展树T执行m次运算,第i次运算的分摊代价cˆic^i定义为:cˆi=ci+ϕi−ϕi−1c^i=ci+ϕi−ϕi−1
定理:在一个有n个结点的伸展树上,执行一次运算i(搜索、插入或删除),其伸展结点为q,所需的分摊代价为:
定理:对一颗结点数目不超过n的伸展树,执行m次运算(搜索、插入或删除)的实际总代价不会超过:
跳表
跳表是一个有序链表,每个结点包含可变数目的链(指针),节点中的第i层链,跳过那些只包含低于第i层链的结点,构成一个单链表。每隔2i2i个元素就有一个i级指针。第0层链是包含所有元素的有序链表,第1层链是包含第0层链的子集,……,第i层链包含的元素是i-1层链的子集。在理想情况下,跳表的层数是⌈logn⌉⌈logn⌉。
对于一个有n个结点的跳表有如下结论:
第k层至少有一个元素的概率至多是n/2kn/2k。
定理:跳表的高度(即最大级数)大于k的概率至多为n/2kn/2k。
- 定理:n个元素的跳表的平均空间复杂度为O(n)O(n)。
基本搜索和遍历方法
基本概念
搜索(search)是一种通过系统地检查给定数据对象的每个结点,寻找一条从开始结点到答案结点的路径,最终输出问题的求解方法。
遍历(traversal)方法要求系统检查数据对象的每个结点。根据被遍历的数据对象的结构不同,可分为树遍历和图遍历。
无知搜索(uninformed search)也称盲目搜索(blind search)或穷举搜索(brute search),是最简单的搜索状态空间树(图)的方法。
有知搜索(informed search)对应于无知搜索,采用经验法则(rules of thumb)的搜索方法称为启发式搜索(heuristic search)。
深度优先搜索(depth first search)和广度优先搜索(breadth first search)是两种基本的盲目搜索方法,介于两者之间的有D-搜索(depth search)。
搜索方法
将被搜索的数据结构中的结点按其状态分为4类:未访问、未检测、正扩展和已检测。
一个结点x如果尚未访问,则它处于未访问(unvisited)状态;如果x自身已访问,但x的后继结点尚未全部访问,则称x处于未检测(unexplored)状态;当算法访问了x的所有后继结点时,就称x已由此算法检测,处于已检测(explored)状态;所谓检测一个结点x是指算法正从x出发,访问x的某个后继结点y,x被称为扩展结点(being expanded),简称E-结点。一旦y被访问后,y便成为未检测结点。在算法执行的任意时刻,最多只有一个结点为E-结点,但可以有多个结点处于未检测状态。
根据如何选择E-结点的规则不同,得到两种不同的搜索算法:深度优先搜索和广度优先搜索。
- 如果对于一个未检测结点,一个搜索算法必定在访问它的全部后继结点后(使得该E-结点成为已检测结点后),才选择另一个未检测结点(作为扩展结点),检测它,这种做法称为广度优先搜索。
- 如果一个算法一旦访问了某个结点,该结点成为未检测结点后,便立即被算法检测,成为E-结点,而此时,原E-结点尚未检测完毕,仍处于未检测状态,需要在以后适当时候才得以继续检测,这种做法称为深度优先搜索。
称未检测结点为活结点(life node),称已检测结点为死节点(dead node)。在搜索算法的执行中,需要有一个数据结构保存这些活结点,被称为活结点表(life node list)。
深度优先搜索需要用堆栈作为活结点表,而广度优先搜索的活结点表通常是先进先出的队列。如果一个搜索算法既按广度优先搜索方式选择E-结点,又使用堆栈为活结点表,则称之为D-搜索,它是广度和深度两者的结合。