大数据分析Hadoop及Python实现
大数据
1.分布式:
主节点(Master)、从节点(Slaves)
2.集群(多台机器)
同时存储数据,并行处理数据
3.分布式计算
核心思想:分而治之思想
一.Hadoop
1.Apache Hadoop
介绍:
对多个服务器中分布式并行处理数据的一种工具,可以无限的扩大数据规模,以此来解决大数据规模。
特点;
规模扩展性,灵活性,容错性和低成本。
功能:
Apache Hadoop是一个100%开源的框架,主要有两个功能:
(1)存储大数据
(2)处理大数据
2.Hadoop关键模块
(1)HDFS
分布式存储海量数据, 将大数据文件分割为小的block(默认值128MB)文件进行存储的

(2)YARN
管理集群中资源(内存和CPU CORE)、分配资源给程序运行使用,比如MapReduce、Spark

(3)MapReduce
分析海量数据框架
思想:分而治之的思想 将大数据文件分为很多小的数据文件,每个数据文件启用一个Map Task进行处理,完成以后启用一个Reduce Task合并所有的Map Task处理的结果。

3.Hadoop模块具体流程
(1)HDFS(数据存储)
分布式存储数据,将大数据文件划分为小数据文件Block,存储在集群中各个节点的硬盘中,
每个block有三个副本数,由Block统一管理。

(2)YARN(资源管理)
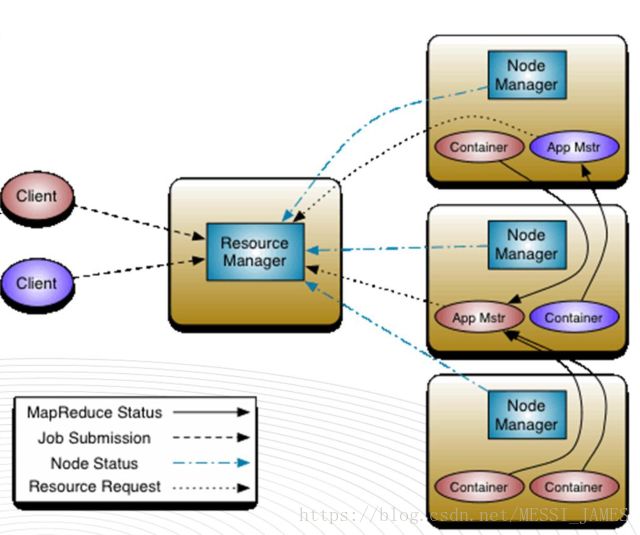
YARN中
ResourceManager:Master结构(主节点)
NodeManager:Slave结构(子节点)

(3)MapReduce(数据分析框架)
第一阶段:
Map:并行处理输入数据
对每一部分数据进行分析处理。
函数,包含 处理数据的逻辑代码(可以使用Java或Python)。
第二阶段:
Reduce:对Map结果进行汇总
合并map处理数据的结果
过程input:设置要处理的数据存储位置 hdfs
map:指定处理数据的map函数
reduce:指定合并map函数处理的数据结构
output:制定最终合并处理的数据结果存储的地方 hdfs
一个简单的MapReduce需要指定map(),reduce(),input(),output(),其他由框架完成。
二.Linux

1.安装VMware Workstation虚拟化工具
D:\Spark\上课\06_资料书籍 参考word文档
2.Linux常见命令
(1) 查看当前目录下的文件有哪些(list)
ls
ls -l=ll
(2)进入某个目录(change directory)
cd 目录名称
(3) 读取文件(文本文件,在Windows下使用记事本打开的文件)
more 文件名称
less 文件名称
head 文件名称(默认是显示前10行数据)
tail 文件名称(默认是显示后10行数据)
cat 文件名称 (当且仅当,查看文件内容较少的时候)
(4)显示当前目录(print work derictory)
pwd
(5)创建目录
mkdir 目录名称
mkdir -p bigdata/ai0404
-p 表示创建目录的父目录不存在的话,一并创建
(6)两个特殊的目录
.. -> 表示的是 上一级目录,比如: cd ..
. -> 表示的是 当前目录
(7)创建文件
touch 文件名称
(8)编辑文件
vim aa.txt 进入以后:
i -> 显示插入模式Insert
Esc、:、x -> 保存文件内容(一共三个键,再回车。中文下的冒号)
Esc、:、q! -> 退出编辑,不保存文件
(9)拷贝文件
cp 源文件 目标文件
(10)删除文件
rm -rf 文件名称/目录名称
(11)上传文件

(12)重命名文件
MV+空格+当前文件名+新文件名
3.安装软件lrzsz
Linux系统自带上传下载软件,将本地文件上传到虚拟机中(服务器上)
$sudo yum install -y lrzsz
4.远程连接三大工具(开发大数据)
(1)远程
命令行工具
Xshell
(2) 远程编辑工具
Notepad++ 和 NppFTP 插件
(3)远程文件上传下载工具
使用系统自带的lrzsz工具
三.案例
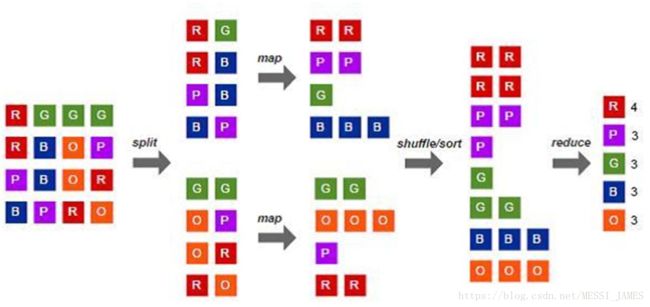
1.词频统计WordCount(类似TF)
属于大数据框架中最经典的案例:统计文件中每个单词出现的个数
(1)准备数据
将要分析的数据存储到HDFS文件系统中
a :rz上传数据
b:创建目录
hdfs dfs -mkdir -p /user/cloudera/wordcount/input
c:上传数据文件(位置home/cloudera/bigdata/wc.data)
hdfs dfs -put /home/cloudera/bigdata/wc.data /user/cloudera/wordcount/input
(2)使用Python编码,实现wordcount统计
input,mapper,reducer a:使用Python开发
完成mapper.py和reduce.py脚本
#!/usr/bin/python
#-*- coding: utf-8 -*-
import sys
#从标准输入读取数据
for line in sys.stdin:
#hadoop spark hadoop spark
#去除读取每条数据前后空格,并按照空格分割
for word in line.strip().split():
print "%s\t%d"%(word,1)#!/usr/bin/python
#-*- coding: utf-8 -*-
import sys
#定义变量存储 单词 和 词频
current_word=None
current_count=1
for line in sys.stdin:
#读取mapper函数输出结果
word,count=line.strip().split("\t")
#判断当前是否存在单词
if current_word:
if word==current_word:
current_count+=int(count)
else:
print "%s\t%d"%(current_word,current_count)
current_count=1
#赋值当前单词
current_word=word
#处理读取最后一行数据
if current_count>=1:
print "%s\t%d"%(current_word,current_count)b:
在linux系统上执行,需要给予执行权限:
chmod u+x wordcount_mapper.py
chmod u+x wordcount_reducer.py
c:测试结果
查看wordcount_mapper.py
echo “hadoop mapreduce mapreduce python” | python wordcount_mapper.py
查看wordcount_reducer.py
echo “hadoop mapreduce mapreduce python” | python wordcount_mapper.py | python wordcount_reducer.py

(3)运行Python编写的WordCountt在YARN
a:提交运行Hadoop 中MapReduce运行在YARN上
hadoop jar / yarn jar
b:-files 参数 将Python编写脚本文件上传到集群上,以便集群中各个集群下载使用
要求集群中各个机器上必须按照同一版本、同一目录的Python
c:指定 input、output、mapper和reducer各个参数的值
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming-2.6.0-cdh5.12.0.jar -files /home/
cloudera/bigdata/wordcount_mapper.py,/home/cloudera/bigdata/wordcount_reducer.py -mapper \
"python wordcount_mapper.py" -reducer "python wordcount_reducer.py" -input /
user/cloudera/wordcount/input.wc.data -output /user/cloudera/wordcount/output2.IBM股票价格数据

a. 创建目录stock,拷贝wordcount_mapper.py和wordcount_reducer.py文件至stock目录
重命名文件:
mv wordcount_mapper.py stock_mapper.py
mv wordcount_reducer.py stock_reducer.py
b. 开发代码
c. 本地测试:
more stock-ibm.csv | python stock_mapper.py | sort -k1| python stock_reducer.py > stock-ibm.output
d. 集群测试
读取HDFS上的数据,将程序提交运行在YARN上。
/user/cloudera/stock/input
(1)准备文件stock_mapper.py和stock_reducer.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
# 从标准输入读取数据
for line in sys.stdin:
# Date,Open,High,Low,Close,Adj Close,Volume
row=line.split(",")
# Open Price
open_price=float(row[1])
# Close Price
close_price=float(row[-3])
# Compute Price Change
price_change=((open_price-close_price)/open_price)*100
cheng_text=str(round(price_change, 2))+"%"
print "%s\t%d" % (cheng_text, 1)#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
# 定义变量存储 单词 和 词频
current_word = None
current_count = 1
for line in sys.stdin:
# 读取mapper函数输出的结果
word, count = line.strip().split("\t")
# 判断当前是否存单词
if current_word:
if word == current_word:
current_count += int(count)
else:
print "%s\t%d" %(current_word, current_count)
current_count = 1
# 赋值当前单词
current_word = word
# 处理读物最后一行数据
if current_count >= 1:
print "%s\t%d" %(current_word, current_count)(2)matplotlib可视化
安装matplotlib工具包:
sudo yum install python-matploylib
#!/usr/bin/python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
# 从MapReduce统计分析结果文件读取数据
with open('/home/cloudera/bigdata/stock/part-00000') as f:
# 存储 x轴和y轴 数据
x,y=[],[]
# 一行一行读取数据 数据格式: -1.7% 144
for line in f.readlines():
# 按照制表符分割
data=line.split("\t")
# 存储 每日百分比数据 -> X轴
x.append(float(data[0].strip('%')))
# 存储 统计数 -> Y轴
y.append(float(data[1]))
print "Max: ",max(x)
print "Min: ",min(x)
# 绘制柱状图
plt.bar(x,y,width=0.1)
# 显示
plt.show()