python爬取小说(三)数据存储
由于时间关系,我们先把每章的内容存储到数据库。
需要用到sqlite,
接着上一篇,在原基础上修改代码如下:
# -*- coding: utf-8 -*-
import urllib.request
import bs4
import re
import sqlite3
import time
print ('连接数据库……')
cx = sqlite3.connect('PaChong.db')
# #在该数据库下创建表
# 创建书籍基本信息表
cx.execute('''CREATE TABLE book_info(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title verchar(128) not null,
img verchar(512) null,
auther verchar(64) null,
type verchar(128) null,
status verchar(64) null,
num int null,
updatatime datetime null,
newchapter verchar(512) null,
authsummery verchar(1024) null,
summery verchar(1024) null,
notipurl verchar(512) null);
''')
# 创建章节内容表
cx.execute('''CREATE TABLE book_chapter(
id INTEGER PRIMARY KEY AUTOINCREMENT,
book_id int null ,
chapter_no int null ,
chapter_name verchar(128) null,
chapter_url verchar(512) null,
chapter_content text null);
''')
print("Table created successfully")
print("数据库连接完成")
def getHtml(url):
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
headers = {"User-Agent":user_agent}
request = urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(request)
html = response.read()
return html
# 爬取整个网页
def parse(url):
html_doc = getHtml(url)
sp = bs4.BeautifulSoup(html_doc, 'html.parser', from_encoding="utf-8")
return sp
# 爬取书籍基本信息
def get_book_baseinfo(url):
# class = "info"信息获取
info = parse(url).find('div',class_ = 'info')
book_info = {}
if info:
# print(info)
book_info['title'] = ''
book_info['img'] = ''
# 标题
book_info['title'] = info.find('h2').string
# book_info['title'] = title
# 图片链接
img = info.find('div',class_ = 'cover')
for im in img.children:
# 图片地址想要访问,显然需要拼接
book_info['img'] = 'http://www.biqukan.com' + im.attrs['src']
# 基本信息存储
ifo = info.find('div',class_ = 'small')
bkinfo = []
for b in ifo:
for v in b.children:
t = v.string
if t:
bkinfo.append(''.join(t))
# 将:后面的信息连起来
spv = []
cv = ''
for v in bkinfo:
if v.find(':') >= 0:
if cv:
spv.append(cv)
cv = v
else:
cv += v
spv.append(cv)
# 基本信息转成字典
for element in spv:
its = [v.strip() for v in element.split(':')]
if len(its) != 2:
continue
nm = its[0].lower() # 统一成小写
if type(nm).__name__ == 'unicode':
nm = nm.encode('utf-8')
vu = its[1]
book_info[nm] = vu
# 发现这里获取到的字典键与后面将要获取的键重复了,所以这里改一下
book_info['auther'] = book_info.pop('作者')
#简介获取(与基本信息的获取方式一致)
intro = info.find('div',class_ = 'intro')
bkurl = []
for b in intro:
t = b.string
if t:
bkurl.append(''.join(t))
bkjj = []
cvx = ''
for w in bkurl:
if w.find(':') >= 0:
if cvx:
bkjj.append(cvx)
cvx = w
else:
cvx += w
bkjj.append(cvx)
for ele in bkjj:
itis = [n.strip() for n in ele.split(':')]
if len(itis) != 2:
continue
summ = itis[0].lower() # 统一成小写
if type(summ).__name__ == 'unicode':
summ = summ.encode('utf-8')
vux = itis[1]
book_info[summ] = vux
# 由于我们后面创建的数据表字段使用英文,为方便起见,这里用字典名映射转换
# 英文
# book_en = ["title", "img", "type", "status","num", "updatatime", "newchapter", "auther","summery", "authsummery","notipurl"]
# 中文
# book_cn = ["书名", "图片链接", "分类", "状态", "字数", "更新时间", "最新章节", "作者", "简介", "作者介绍","无弹窗推荐地址"]
# 将字典的key与数据库中的字段对应,这里用book_dict列表存储
# book_dict = dict(zip(book_cn,book_en))
# 使用笨办法将字典的key转成英文状态,这样方便数据库存储
book_info['type'] = book_info.pop('分类')
book_info['status'] = book_info.pop('状态')
book_info['num'] = book_info.pop('字数')
book_info['updatatime'] = book_info.pop('更新时间')
book_info['newchapter'] = book_info.pop('最新章节')
book_info['authsummery'] = book_info.pop('作者')
book_info['summery'] = book_info.pop('简介')
book_info['notipurl'] = book_info.pop('无弹窗推荐地址')
return book_info
# 获取书籍目录
def get_book_dir(url):
books_dir = []
name = parse(url).find('div', class_='listmain')
if name:
dd_items = name.find('dl')
dt_num = 0
for n in dd_items.children:
ename = str(n.name).strip()
if ename == 'dt':
dt_num += 1
if ename != 'dd':
continue
Catalog_info = {}
if dt_num == 2:
durls = n.find_all('a')[0]
Catalog_info['chapter_name'] = (durls.get_text())
Catalog_info['chapter_url'] = 'http://www.biqukan.com' + durls.get('href')
books_dir.append(Catalog_info)
# print(books_dir)
return books_dir
# 获取章节内容
def get_charpter_text(curl):
text = parse(curl).find('div', class_='showtxt')
if text:
cont = text.get_text()
cont = [str(cont).strip().replace('\r \xa0\xa0\xa0\xa0\xa0\xa0\xa0\xa0', '').replace('\u3000\u3000', '')]
c = " ".join(cont)
ctext = ' '.join(re.findall(r'^.*?html', c))
return ctext
else:
return ''
#数据存储
def SqlExec(conn,sql):
try:
cur = conn.cursor()
cur.execute(sql)
conn.commit()
except Exception as e:
print('exec sql error[%s]' % sql)
print(Exception, e)
cur = None
return cur
# 获取书籍章节内容 并入库
def get_book(burl):
# 目录
book = get_book_dir(burl)
if not book:
print('获取数据目录失败:', burl)
return book
for d in book:
curl = d['chapter_url']
try:
ctext = get_charpter_text(curl)
d['chapter_content'] = ctext
sql = 'insert into book_chapter(' + 'book_id' + ',' + 'chapter_no' + ','+ ','.join(d.keys()) + ')'
i = 1
sql += " values('" + str(i) + "'" + "," + "'" + str(i) + "'" + "," + "'" + "','".join(d.values()) + "');"
# 调用数据库函数
if SqlExec(cx, sql):
print('正在插入...【{}】'.format(d['chapter_name']))
else:
print(sql)
except Exception as err:
d['chapter_content'] = 'get failed'
return book
# 书籍基本信息入库
def insert_baseinfo(burl):
baseinfo = get_book_baseinfo(burl)
if not baseinfo:
print("获取基本信息失败")
return baseinfo
sql = 'insert into book_info(' + ','.join(baseinfo.keys()) + ')'
sql += " values('" + "','".join(baseinfo.values()) + "');"
# 调用数据库函数
if SqlExec(cx, sql):
print('正在插入...书籍【{}】'.format(baseinfo['title']))
else:
print(sql)
if __name__ == '__main__':
# 一本书的所有章节爬完之后,才会爬取下一本书的内容
url = 'http://www.biqukan.com/1_1094/'
insert_baseinfo(url)
get_book(url)
结果展示:
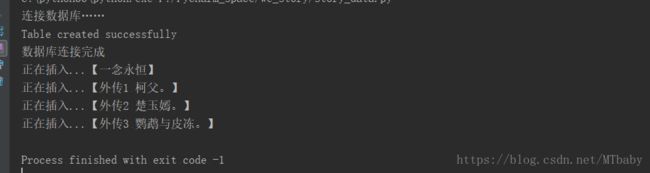
数据库展示:


如果你想爬去多本书的信息和内容,那就组装一下url
if __name__ == '__main__':
for i in range(1090,1100):
url = 'http://www.biqukan.com/1_' + str(i) + '/'
insert_baseinfo(url)
get_book(url)结果如下:
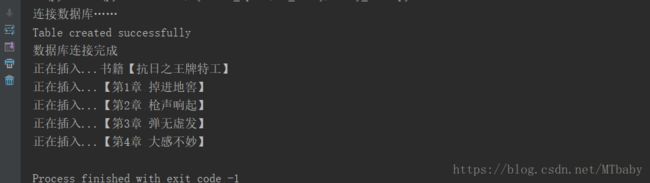
下一篇会将数据在前端展示。