昨天,腾讯百万节点规模管控系统(TSC)诞生了!

2018-07-04,随着时钟的滴答,在10:30:33这一秒,腾讯第一个百万规模管控系统-Tencent System Controller(TSC)诞生了,这绝对是一个划时代的开端,一个新纪元的开始!
海量服务器管控系统,一般人心中是这样理解的,规模至多几万台,全部以Master/Slave模式并行部署,所有node上面跑着一样的进程,进程之间有着复杂的控制和协调机制,支持node的有限伸缩(scalable)。
但这一次,我们真的要重新定义海量服务器管控系统的理念,各位客官请听我娓娓道来。
一、多层立体分布式
普通的分布式系统如hadoop皆基于C/S两层架构,并且总是要求网络扁平,在100万集群节点数、跨IDC等复杂环境下难以胜任。

当服务器数规模达到100万时,显然不能用常规的master-worker两层设计思想,必须使用master-zone_master-workor-worker_descendant[1-N代]的多层级管理设计,还需要融合worker的级联管理能力。
使用这种类似“中央-省-县-镇-村”行政区域的管理模式带来一系列好处,zone_master大多数事务是自治的,自行管理和决策,只是很重要的信息才上报给master;反之master也只给zone_master下达任务描述等很关键的信息,任务执行后,各zone_master只需要向master报告总体的任务执行情况即可,这样设计可以大幅减少网络通信传输,提升了整个系统控制能力。
二、百万服务器管控系统架构

对于普通C/S集群,在tcp server端我们用普通的NIO Server(java)、epoll/IOCP server(C/C++)即可轻松胜任。
但是对于百万node并且都是活动连接的集群,上述架构明显不能胜任。因此我们必须采取分治法+协程的策略对百万级别的连接进行统一管理和调度。

1. Zone-Master反向连接
TSC系统不同于一般集群系统,是zone-master反向连接worker的,这样做的好处如下:
(a) .响应及时。对于新任务可以直接发起一个新连接进行处理,而不需要在已有的连接中反复协议交互。
(b) .worker部署方便。worker是被动接受连接,不需要配置server ip,所有worker安装目录和配置都是一样的。
(c) .稳定性高。系统连接只处理标准的心跳信息及全局状态维护,用户任务都是在实时发起的新连接中处理,天然的信道分离使得程序逻辑处理简单,系统稳定性高。
2. 多进程+epoll协程模式
分治法是处理复杂问题最朴素的哲学思想,对于一个100万节点的集群,为了系统能高速响应,我们采取多机并行+每机并发多进程 +每进程并发协程的三重维度并行模式来处理,每个任务都可以被拆分在多个zone-master上跑,每个zone-master都采用多进程+epoll协程的模式对海量连接进行管理。
这种设计有如下优点:
(a) .稳定性高。在zone master上每个任务都是一个新的处理进程,进程里再使用epoll+协程进行多个连接的状态管理。一个任务进程的异常挂掉并不会影响其他任务进程,更不会影响整个系统的集群管理。
(b).高并发快速连接能力。由于任务被分而治之处理,并且顶层master会根据地域的亲和值将不同的连接分发到最近的zone-master,然后zone-master再在进程内使用epoll+协程进行并发连接,使得系统最终性能异常高。经实测,如果4万个worker状态都很好,对4万个worker全部执行一个集群任务,可在10秒内完成,这对传统C/S集群来说简直是逆天的节奏。
(c).可伸缩性强。当zone-master处理能力不足时,随时可以扩容机器,并能将其他的zone-master所管理的节点迁移到新的zone-master,以减轻原来zone-master的负担。
3. Worker级联管理
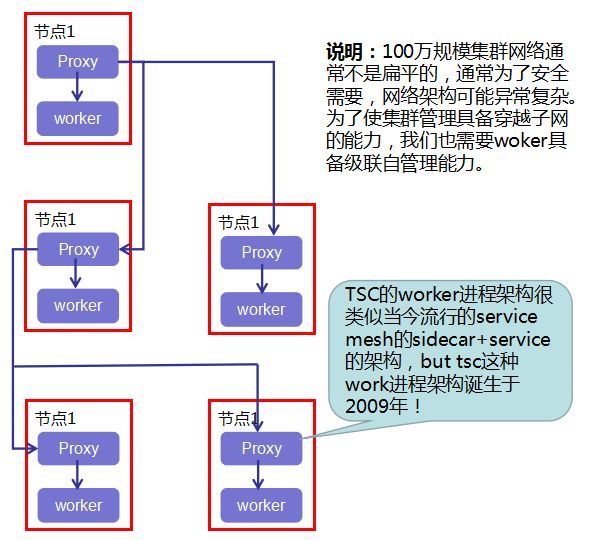
每个worker机器上都有proxy和worker两个进程,proxy只负责安全校验以及转发数据包,可以转发给自己的worker进程,也可以转发给别的worker进程,并支持无限层转发。
明显地,该架构使得系统能轻易地支持类似树形的复杂网络,并能穿透各种安全屏障及桥头堡机器。
TSC支持任意网络拓扑结构的组网,包括但不限于:
(a) .内外网混合组网
公司早期(2010-2012)内网跨城专线带宽很小且非常昂贵,tsc支持公网连接南北城市组网,传输海量文件为公司节省了大量成本。
(b) .自营/合作机房混合组网
SNG有二十多万的合作机房机器,由于安全需要,合作机房和自营机房在网络上是隔离的,但现实中SNG存在大量的跨“自营机房-合作机房”文件及脚本传输执行的需求,tsc很好地满足了SNG的该类管控需求。
(c) .普通区/devnet(开发网)混合组网
由于公司的安全策略,默认情况下devnet是隔离的。但对于发布系统、编译系统、持续集成系统来说,对devnet的自动化操作需求非常迫切,tsc很好地满足了该类平台的需求。
(d) .VPC多LAN重复组网
伴随着公司业务高速发展,某些BG需要和第三方公司合作,需要对第三方公司的机器进行管理,比如发布、监控等。第三方公司的机器位于自己独立的内网中,IP和公司的运营大网IP有重复和交叠。为了支持这种应用场景,TSC除了IP寻址外,还增加了基于uid(唯一标识)寻址的功能,这就可以在原有腾讯运营的大网集群基础上轻松桥接公司外的VPC私有网络。
(e) .基于上述4种结构的联合组网
基于各种历史原因和现实需求,目前tsc的组网模式实际上为上述4种模式的混合体。用户下发tsc任务时,不用关心网络细节,只需要输入ip或者uid即可,中间的路径计算及路由过程完全由系统自动现实,因此用户体验相当好。
4. 海量拓扑管理
大型互联网企业IDC管理网络(全局视点)是一个超级复杂、内外网混合、多种安全策略应用、需多次穿透代理等的立体式网状网络。
IP路由技术不能解决本系统所面临的困境,我们必须在软件应用层面想办法解决这个问题。
设计上可以使用DB持久化存储网络拓扑关系,并使用读cache缓存网络拓扑关系提高性能。同时采用预先申明路由策略与自动路由信息探测相结合的方法管理网络拓扑结构。Master负载均衡时以预先申明路由信息为主,同时考虑实时路由信息权值进行下发任务。
这种动静结合的方式能很好地解决超复杂的树形网络集群的管理及路由分发问题,同时又使得系统拓扑处于绝对的可控状态,不会引发泛洪、雪崩等非中心化集群系统可能存在的风险。
三、多维度安全性
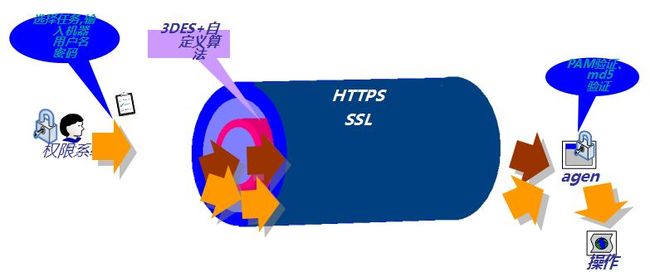
TSC安全架构图
1. 强鉴权
Worker上的任何操作必须经过本地OS的权限系统验证,权限控制与ssh类似(特殊的固定无危险的豁免脚本除外)。Linux默认会开启pam增强鉴权,Windows使用LogOnUser API鉴权。系统还支持插件式自定义鉴权,譬如ssl公钥鉴权。
2. 全通道ssl加密
Master、Zone-master、Workor、Worker_descendant所有节点通信均采用ssl加密,故TSC系统在通过公网转发数据包时没有安全风险,在内网中也没有被监听和篡改的风险。
3. 强化证书身份校验
为了防止节点被伪造,系统中的所有节点相互通信都会检查对端证书。证书不同于常规仅绑定url的证书,而是使用强化的证书域验证,证书域(Common Name)分为 系统、角色、IP,如tsys_master_172.16.5.39,此证书仅能用于tsys业务master模块而且IP必须为172.16.5.39,这种强化证书身份检验使得黑客根本无法伪造搭建系统节点。
4. 多重手段保证安全
除了整个外层通道的SSL加密,我们还对密码等敏感字段进行了高强度的二次加密,并且融合了PAM/LDAP用户验证、协议用户认证、sha512脚本验证等多重安全手段保障系统安全。
TSC还支持加密密码零保存、协议用户验证、服务器鉴定、防重放攻击、全程审计等诸多安全特性。
四、无限伸缩能力
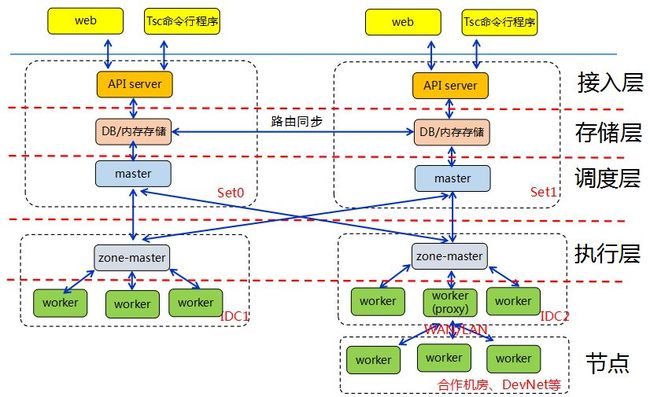
TSC的顶层调度层(master)采用set概念设计,每个set内都有独立的执行单元,部署在独立的物理机器上;多个set之间共享路由信息,在任务的分发、调度上,各个set的行为结果都是一致的,故可以看成是分布式系统的最终一致性。
执行层会同时连接多个set,接受任意set的任务指令,并将指令最终送达Worker或者Worker_descendant执行。
当系统处理能力遇到瓶颈时,直接扩容一个新的set即可,由于全局路由信息量较小,而且是1:N模式同步,因此系统理论上是支持无限伸缩的。
