【机器学习】模型评估与选择--西瓜书第二章
2.1 经验误差与过拟合
2.2 评估方法
2.3 性能度量
2.5 偏差与方差
2.1 经验误差与过拟合
错误率(error rate):分类错误的样本占总样本的比率
精度(accuracy):分类正确的样本占总样本的比率
误差(error):学习器的实际预测输出与样本的真实输出之间的差距(指误差期望)
训练误差(training error)或经验误差(empirical error):学习器在训练集上的误差
泛化误差(generalization error):在新样本上的误差
我们希望得到泛化误差小,在新样本上表现好的学习器。我们应该从训练样本中尽可能学出适用于所有潜在样本的"普遍规律",这样才能在遇到新样本时做出正确的判别。
然而,实际能做的是努力使经验误差最小化。在很多情况下,我们可以学得一个经验误差很小、在训练集上表现很好的学习器,在训练集上表现很好,在测试集上表现很差,这就是过拟合。
过拟合(overfitting):学习器学习能力太好,把训练样本自身的一些特点(训练样本所包含的不太一般的性质)当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下
欠拟合(underfitting):学习器学习能力太低下训练样本的一般特点都没有学好。解决方法有:在决策树学习中扩展分支、在神经网络学习中增加训练轮数epoch
过拟合无法避免,只能缓解
2.2评估方法
不同的参数配置 ⇒ \Rightarrow ⇒不同的模型 ⇒ \Rightarrow ⇒选择泛化误差最小、泛化性能最强的模型。
训练集(training set):训练模型
验证集(validation set):选择模型和调参
测试集(test set):评估模型
留出法 (hold-out)
"留出法"直接将数据集 D 划分为两个互斥的集合?其中一个集合作为训练集 S,另一个作为测试集 T, 即$S \cup T=D $ , S ∩ T = ⊘ S \cap T=\oslash S∩T=⊘。在 S 上训练出模型后,用 T 来评估其测试误差,作为对泛化误差的估计。
常见做法是将大约 2/3 ~ 4/5 的样本用于训练,剩余样本用于测试。
交叉验证法(cross validation)
(1)先将数据集 D 划分为 k 个大小相似的互斥子集, 每个子集 Di 都尽可能保持数据分布的一致性,即从 D 中 通过分层采样得到。
(2)每次用k-1 个子集的并集作为训练集,剩下那个子集作为测试集
这样就可获得 k组训练/测试集,从而可进行 k 次训练和测试,最终返回的是这 k 个测试结果的均值。
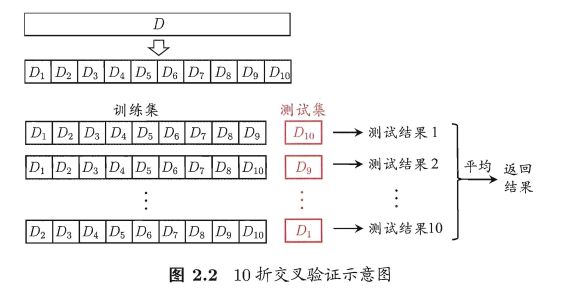
交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值,为强调这一点,通常把交叉验证法称为 " k 折交叉验证" (k-fold cross validation)。k 最常用 的取值是 10,此时称为 10 折交叉验 证 ; 其他常用 的 k 值有 5、 20 等。
from sklearn.model_selection import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=2)
kf.get_n_splits(X)
2
print(kf)
KFold(n_splits=2, random_state=None, shuffle=False)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
TRAIN: [2 3] TEST: [0 1]
TRAIN: [0 1] TEST: [2 3]
若令 k=m(数据集中有m个样本), 则得到了交叉验证法的一个特例:留一法 (Leave-One-Out,简称 LOO)
在留出法和交叉验证法中,由于保留了一部分样本用于测试,因此实际评估的模型所使用的训练集比 D小,这必然会引入一些因训练样本规模不同而导致的估计偏差。留一法受训练样本规模变化的影响较小,但计算复杂度又太高了。“自助法” (bootstrapping)是一个比较好的解决方案。
2.3 性能度量
性能度量(performance measure):衡量模型泛化能力的评价标准。
回归任务最常用的性能度量是均方误差(mean squared error)即MSE
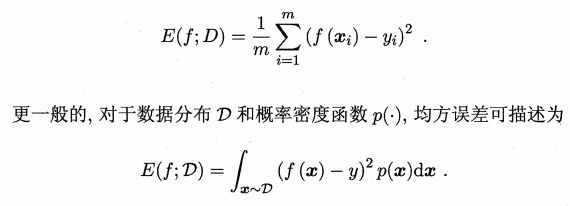
下面介绍分类任务中常用的性能指标。
第一类
错误率(error rate):分类错误的样本占总样本的比率
正确率(accuracy):又叫精度,分类正确的样本占总样本的比率
a c c u r a c y = T P + T N T P + F P + T N + F N accuracy=\frac{TP+TN}{TP+FP+TN+FN} accuracy=TP+FP+TN+FNTP+TN
当您使用分类不平衡的数据集(比如正类别标签和负类别标签的数量之间存在明显差异)时,单单正确率一项并不能反映全面情况。
第二类
precision ⇔ \Leftrightarrow ⇔ 查准率 ⇔ \Leftrightarrow ⇔ 准确率:在被识别为正类别的样本中,确实为正类别的比例是多少?
recall ⇔ \Leftrightarrow ⇔ 查全率 ⇔ \Leftrightarrow ⇔ 召回率:在所有正类别样本中,被正确识别为正类别的比例是多少?
如何理解?
以西瓜问题为例:
假定瓜农拉来一车西瓜,我们用训练好的模型对这些西瓜进行判别,
查准率:“挑出的瓜中真正是好瓜的比例”
查全率:“所有好瓜 有多少被挑了出来”
以信息检索问题为例:
查准率:“检索出的信息中有多少比例是用户真正感兴趣的”
查全率:“用户感兴趣的信息 有多少被检索出来”
如何计算?
对于二分类问题,可将样本根据其真实类别与预测类别的组合划分为真正例 (true positive)、假正例 (false positive)、真反例 (true negative) 、假反例 (false negative) 四种情形。分类结果的“混淆矩阵”(confusion matrix)如下:
TP+FP+TN+FN=样本总数

查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。例如,若希望将好瓜尽可能多地选出来(查全率高),则可通过增加选瓜的数量来实现,如果将所有西瓜都选上,那么所有的好瓜也必然都被选上了,但这样查准率就会较低;若希望选出的瓜中好瓜比例尽可能高(查准率高),则可只挑选最有把握的瓜, 但这样就难免会漏掉不少好瓜,使得查全率较低。
P-R曲线:
如何绘制?
根据样例是正例的可能性进行排序,排在前面的是学习器认为"最可能 “是正例的样本,排在最后的则是学习器认为"最不可能"是正例的样本。这样,分类过程就相当于在这个排序中以某个"截断点” (cut point)将样本分为两部分,前一部分判作正例,后一部分则判作反例。
这个截断点就相当于阈值(threshold),设置不同的threshold计算出当前的查全率、 查准率。
即根据不同threshold来绘制曲线,曲线A上的每个点都对应不同的阈值。
A,B,C是三个学习器,也可以说是三个模型。
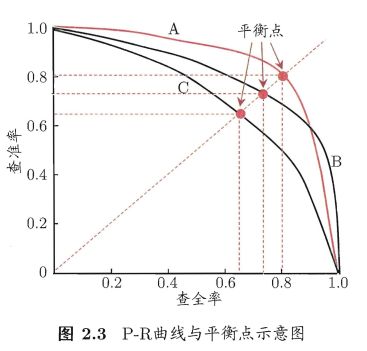
如何度量学习器性能?
若一个学习器的 P-R 曲线被另一个学习器的曲线完全包住 ,则后者的性能优于前者,A优于C
若两个学习器的P-R曲线相交,则可根据平衡点和F1度量。
(1)平衡点(Break-event Point,简称BEP):即查全率=查准率时的取值。平衡点取值A>B,即A优于B
(2)F1度量
Fl 是基于查准率与查全率的调和平均 (harinonic mean)定义的:
1 F 1 = 1 2 ( 1 P + 1 R ) \frac{1}{F1}=\frac{1}{2}(\frac{1}{P}+\frac{1}{R}) F11=21(P1+R1)
即:
F 1 = 2 × P × R P + R F1=\frac{2\times P \times R}{P+R} F1=P+R2×P×R
在一些应用中,对查准率和查全率的重视程度有所不同。例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时查全率更重要。
F1 度量的一般形式 – F β F_{\beta} Fβ能让我们表达出对查准率/查全率的不同偏好, F β F_{\beta} Fβ是加权调和平均,它定义为:
1 F β = 1 1 + β 2 ( 1 P + β 2 R ) \frac{1}{F_{\beta}}=\frac{1}{1+\beta^{2}}(\frac{1}{P}+\frac{\beta^{2}}{R}) Fβ1=1+β21(P1+Rβ2)
其中 β \beta β>O 度量了查全率对查准率的相对重要性; β \beta β=1即等于F1;
β \beta β>1 查全率有更大影响, β \beta β<1查准率有更大影响。
第三类
ROC 和 AUC
根据样例是正例的可能性进行排序,排在前面的是学习器认为"最可能 “是正例的样本,排在最后的则是学习器认为"最不可能"是正例的样本。这样,分类过程就相当于在这个排序中以某个"截断点” (cut point)将样本分为两部分,前一部分判作正例,后一部分则判作反例。这个截断点就相当于阈值(threshold)。
在不同的应用任务中,我们可根据任务需求来采用不同的截断点,例如若我们更重视"查准率"(把握),则可选择排序中靠前的位置进行截断;若更重视"查全率"(数量),则可选择靠后的位置进行截断。因此,排序本身的质量好坏,体现了综合考虑学习器在不同任务下的"期望泛化性能"的好坏,或者说"一般情况下"泛化性能的好坏。ROC 曲线则是从这个角度出发来研究学习器泛化性能的有力工具。
注意:下图右边等于上面所描述的前面

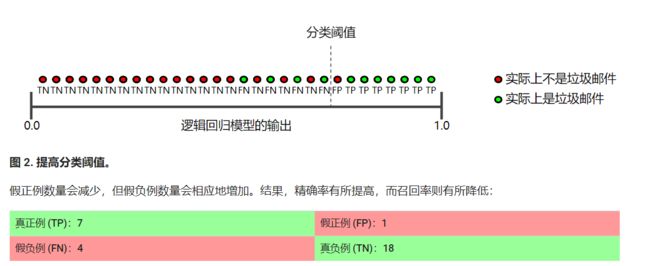
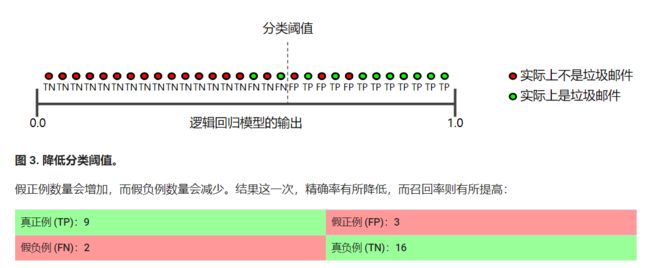
如何计算?
真正例率(TPR),假正例率(FPR)
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
F P R = F P T N + F P FPR=\frac{FP}{TN+FP} FPR=TN+FPFP
根据不同threshold来计算TPR,FPR。一条曲线上的每个点都对应不同的阈值。
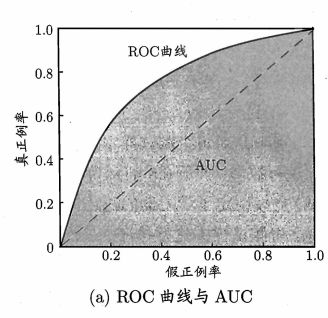
若一个学习器的 ROC 曲线被另 一个学习器的曲线完全"包住", 则可断言后者的性能优于前者;
若两个学习器的 ROC 曲线发生交叉,则根据 ROC 曲线下的面积,即 AUC来比较。
曲线下面积的一种解读方式是看作模型将某个随机正类别样本排列在某个随机负类别样本之上的概率,曲线下面积的取值范围为 0-1
第四类
代价曲线
在现实任务中常会遇到这样的情况:不同类型的错误所造成的后果不同。例如在医疗诊断中,错误地把患者诊断为健康人与错误地把健康人诊断为患者,后者的影响是增加了进→步检查的麻烦,前者的后果却可能是丧失了拯救生命的最佳时机;再如,门禁系统错误地把可通行人员拦在门外,将使得用户体验不佳,但错误地把陌生人放进门内,则会造成严重的安全事故。
为权衡不同类型错误所造成的不同损失,可为错误赋予"非均等代价" (unequal cost)。
在非均等代价下,需要最小化总体代价(total cost), ROC 曲线不能直接反映出学习器的期望总体代价。
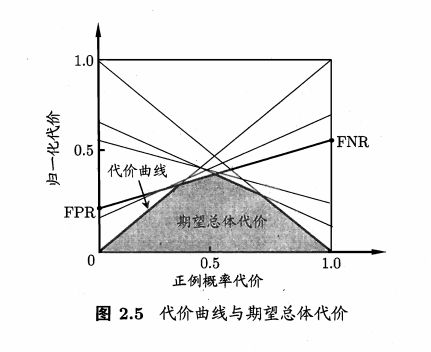
如何绘制?
假反例率: F N R = 1 − T P R FNR=1-TPR FNR=1−TPR
ROC 由线上每一点对应了代价平面上的一条线段 ,设 ROC 曲线上点的坐标为 (TPR, FPR) ,则可相应计算出 FNR,然后在代价平面上绘制一条从 (O , FPR) 到 (1 , FNR) 的线段,线段下的面积即表示了该条件下的期望总体代价;如此将 ROC 曲线土的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价。
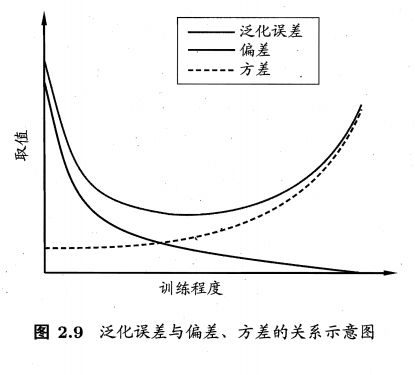
2.5 偏差与方差
偏差(bias): 度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;
方差(variance):度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据的影响;
泛化误差可分解为偏差、方差与噪声之和。
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
泛化性能是由学习算法、数据集以及学习任务本身的难度所共同决定。