ETL工具Kettle的简介和安装配置基本使用
什么是Kettle
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
作为Pentaho的一个重要组成部分,现在在国内项目应用上逐渐增多。
Kettle :Kettle is an acronym for “Kettle E.T.T.L. Environment”. This means it has been designed to help you with your ETTL needs: the Extraction, Transformation, Transportation and Loading of data
Kettle 是”Kettle E.T.T.L. Envirnonment”只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL 需要:抽取、转换、装入和加载数据;翻译成中文名称应该叫水壶,名字的起源正如该项目的主程序员MATT 在一个论坛里说的哪样:希望把各种数据放到一个壶里然后以一种指定的格式流出。
kettle的相关知识
Kettle工程存储方式有两种:一种是以XML形式存储,一种是以资源库方式存储。
Kettle中有两类设计分别是:Transformation(转换)与Job(作业),Transformation完成针对数据的基础转换,Job则完成整个工作流的控制。
Kettle常用三大家族:Spoon、Pan、Kitchen。
Spoon:通过图形界面方式设计、运行、调试Job与Transformation。
Pan: 通过脚本命令方式来运行Transformation。
Kitchen: 通过脚本命令方式来运行Job,一般就是通过调用Kitchen脚本来完成定时任务。
目前Kettle有两种版本:一种是社区版(免费),一种是企业版(收费)。
相关网站
kettle官网
https://community.hds.com/docs/DOC-1009855
开源中文社区
http://www.ukettle.org/
Kettle的一些组件的使用方法
http://wiki.pentaho.com/display/EAI/Pentaho+Data+Integration+Steps
Spoon User Guide文档
http://wiki.pentaho.com/display/EAI/Spoon+User+Guide
JAVASCRIPT组件的使用
https://developer.mozilla.org/en/JavaScript
Kettle社区版下载
http://community.pentaho.com/
Kettle企业版下载
http://www.pentaho.com/
Kettle调度使用方法
http://wiki.pentaho.com/display/EAI/Kitchen+User+Documentation
Kettle的安装与配置
下载安装
可以从http://kettle.pentaho.org下载最新版的 Kettle软件 ,同时,Kettle 是绿色软件,下载后,解压到任意目录即可。
目前Kettle的最新版本是7.1。
由于Kettle 是采用java 编写,因此需要在本地有JVM 的运行环境。
安装完成之后,点击目录下面的kettle.exe 或者spoon.bat 即可启动kettle 。在启动kettle 的时候,会弹出对话框,让用户选择建立一个资源库。
资源库:是用来保存转换任务的, 它用以记录我们的操作步骤和相关的日志,转换,JOB 等信息。用户通过图形界面创建的的转换任务可以保存在资源库中。资源库可以是各种常见的数据库,用户通过用户名/ 密码来访问资源库中的资源,默认的用户名/ 密码是admin/admin. 资源库并不是必须的,如果没有资源库,用户还可以把转换任务保存在 xml 文件中。
配置环境变量
前提是配置好Java的环境变量,因为他是java编写,需要本地的JVM的运行环境
配置Java环境变量可参考:
java实战(一)———–jdk环境配置
http://blog.csdn.net/zzq900503/article/details/9770237
在系统的环境变量中添加KETTLE_HOME变量,目录指向kettle的安装目录:D:kettledata-integration(具体以安装路径为准)
新建系统变量:KETTLE_HOME
变量值: D:kettledata-integration(具体以安装路径为准,Kettle的解压路径,直到Kettle.exe所在目录)
选择PATH添加环境变量:
变量名:PATH
变量值:% KETTLE_HOME%;
Kettle的基本概念
作业(job)
负责将[转换]组织在一起进而完成某一块工作,通常我们需要把一个大的任务分解成几个逻辑上隔离的作业,当这几个作业都完成了,也就说明这项任务完成了。
1.Job Entry:一个Job Entry 是一个任务的一部分,它执行某些内容。
2.Hop:一个Hop 代表两个步骤之间的一个或者多个数据流。一个Hop 总是代表着两个Job Entry 之间的连接,并且能够被原始的Job Entry 设置,无条件的执行下一个Job Entry,
直到执行成功或者失败。
3.Note:一个Note 是一个任务附加的文本注释信息。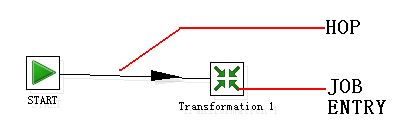
转换(Transformation)
定义对数据操作的容器,数据操作就是数据从输入到输出的一个过程,可以理解为比作业粒度更小一级的容器,我们将任务分解成作业,然后需要将作业分解成一个或多个转换,每个转换只完成一部分工作。
1.Value:Value 是行的一部分,并且是包含以下类型的的数据:Strings、floating point Numbers、unlimited precision BigNumbers、Integers、Dates、或者Boolean。
2.Row:一行包含0 个或者多个Values。
3.Output Stream:一个Output Stream 是离开一个步骤时的行的堆栈。
4.Input Stream:一个Input Stream 是进入一个步骤时的行的堆栈。
5.Step:转换的一个步骤,可以是一个Stream或是其他元素。
6.Hop:一个Hop 代表两个步骤之间的一个或者多个数据流。一个Hop 总是代表着一个步骤的输出流和一个步骤的输入流。
7.Note:一个Note 是一个转换附加的文本注释信息。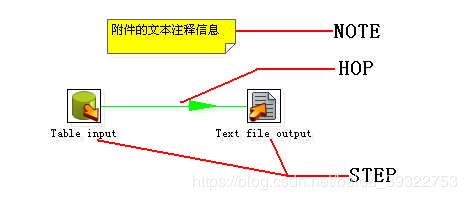
kettle界面和组件
组件树

Main Tree菜单列出的是一个transformation中基本的属性,可以通过各个节点来查看。
DB连接:显示当前transformation中的数据库连接,每一个transformation的数据库连接都需要单独配置。
Steps:一个transformation中应用到的环节列表
Hops:一个transformation中应用到的节点连接列表
Core Objects菜单列出的是transformation中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加。
Input:输入环节
Output:输出环节
Lookup:查询环节
Transform:转化环节
Joins:连接环节
Scripting:脚本环节
Transformation转换介绍
每一个环节可以通过鼠标拖动来将环节添加到主窗口中。
并可通过shift+鼠标拖动,实现环节之间的连接。
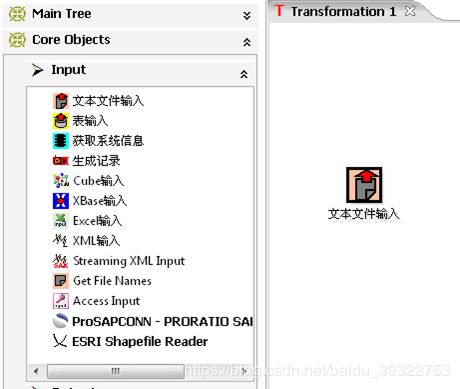
转换常用环节介绍
Job任务介绍

Main Tree菜单列出的是一个Job中基本的属性,可以通过各个节点来查看。
DB连接:显示当前Job中的数据库连接,每一个Job的数据库连接都需要单独配置。
Job entries:一个Job中引用的环节列表
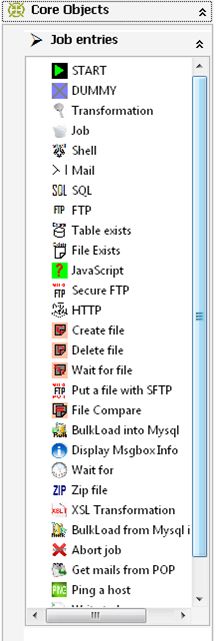
Job entries菜单列出的是Job中可以调用的环节列表,可以通过鼠标拖动的方式对环节进行添加。
每一个环节可以通过鼠标拖动来将环节添加到主窗口中。
并可通过shift+鼠标拖动,实现环节之间的连接。
常用环节介绍
Kettle 基本使用
Kettle 的几个子程序的功能和启动方式
Spoon.bat: 图形界面方式启动作业和转换设计器。
Pan.bat: 命令行方式执行转换。
Kitchen.bat: 命令行方式执行作业。
转换和作业
Kettle 的 Spoon 设计器用来设计转换(Transformation)和 作业(Job)。
•转换主要是针对数据的各种处理,一个转换里可以包含多个步骤(Step)。
•作业是比转换更高一级的处理流程,一个作业里包括多个作业项(Job Entry),一个作业项代表了一项工作,转换也是一个作业项。
输入步骤简介
输入类步骤用来从外部获取数据,可以获取数据的数据源包括,文本文件(txt,csv,xml,json)数据库、 Excel 文件等桌面文件,自定义的数据等。对特殊数据源和应用需求可以自定义输入插件。 例子:生成随机数步骤
转换步骤简介
转换类步骤是对数据进行各种形式转换所用到的步骤。例如:字段选择、计算器、增加常量
流程步骤简介
流程步骤是用来控制数据流的步骤。一般不对数据进行操作,只是控制数据流。 例如:过滤步骤
连接步骤简介
连接步骤用来将不同数据集连接到一起。 例如:笛卡尔乘积
输出步骤简介
输出步骤是输出数据的步骤,常见的输出包括文本文件输出、表输出等,可以根据应用的需求开发插件以其他形式输出。例如:表输出
在Kettle里元数据的存储方式
•资源库 资源库包括文件资源库、数据库资源库 Kettle 4.0 以后资源库类型可以插件扩展
•XML 文件 .ktr 转换文件的XML的根节点必须是 transformation .kjb 作业XML的根节点是job
数据库资源库:
•把 Kettle 的元数据串行化到数据库中,如 R_TRANSFORMATION 表保存了Kettle 转换的名称、描述等属性。
•在Spoon 里创建和升级数据库资源库
文件资源库:
在文件的基础上的封装,实现了 org.pentaho.di.repository.Repository 接口。是Kettle 4.0 以后版本里增加的资源库类型
不使用资源库: 直接保存为ktr 或 kjb 文件。
Kettle 资源库-如何选择资源库
数据库资源库的缺点:
•不能存储转换或作业的多个版本。
•严重依赖于数据库的锁机制来防止工作丢失。
•没有考虑到团队开发,开发人员不能锁住某个作业自己开发。
文件资源库的缺点:
•对象(如转换、作业、数据库连接等对象)之间的关联关系难以处理,所以删除、重命名等操作会比较麻烦。
•没有版本历史。
•难以进行团队开发。
不使用资源库:使用 svn 进行文件版本控制。
命令行执行Kettle文件
参数格式说明 有两种参数格式 1. /参数名:值 或 -参数名=值 建议使用第一种参数格式.
1.执行test.ktr 文件 日志保存在D:log.txt 中, 默认日志级别是Basic
Pan /file:D:AppProjects
xkh est.ktr /logfile:D:log.txt
2.执行test.ktr 文件 日志保存在D:log.txt 中, 日志级别是Rowlevel
Pan /file:D:AppProjects
xkh est.ktr /logfile:D:log.txt /level: Rowlevel
3.导出一个 job 文件,以及该 job 文件依赖的转换及其他资源
kitchen /file:c:/job1.kjb /export:c:/a.zip
4.直接执行一个导出的 zip 文件
Kitchen.bat /file:”zip:file:///c:/a.zip!job1.kjb”
常见错误及其排除
数据库的连接失败

解决办法,是链接相应的数据库的jar包没有加到Kettel中去。在百度或者以前的web项目中找个数据库的jar包。将MySQL-connector-java-5.1.18.jar复制到D:kettle5.1data-integrationlib下面,重新启动一次,这下就好了。再次测试,测试通过链接成功。
传递的数据时出现中文乱码的处理
在数据库连接选项卡中,在选项中增加命名参数setCharacterEncoding = utf8
另外确保在创建数据库时,Character Set同时也设为utf8.

Kettle的变量
变量的类型
Kettle 的早期版本中的变量只有系统环境变量
新版本变量一般包括系统环境变量, “Kettle变量” 和内部变量三种系统环境变量的影响范围很广,凡是在一个 JVM下运行的线程都受其影响.
Kettle变量限制了变量的作用范围, 变量范围包括三种分别是 grand-parent job, parent job, root job
内部变量是 kettle 内置的一些变量, 主要是kettle 运行时依赖的环境, 如转换文件名称, 转换路径,ip地址, kettle 版本号等等.
变量的设置
“系统环境变量” 有三种设置方式
1) 通过命令行 -D 参数
2) 属性文件 kettle.property 中设置, 该属性文件位于 ${user.home}.kettle 下
3) 通过设置环境变量步骤 (Set Variable) 设置.”Kettle 变量” 只能通过设置环境变量 (Set Variable) 步骤设置,同时设置变量的作用范围.
“内部变量” 是预置的无须设置.
变量的使用
无论哪种类型的变量在使用上都是一样的, 有两种方式
1) 通过 %%var%% 或 var来引用,这个引用可以用在SQL语句中,也可以用在允许变量输入的输入框里.2)通过获取变量(GetVariable)步骤来使用命令行参数:1.设置:命令行参数通过获取系统信息(GetSystemInfo)步骤设置,在使用时可以像列名一样来使用,不必像变量一样要通过var来引用,这个引用可以用在SQL语句中,也可以用在允许变量输入的输入框里.2)通过获取变量(GetVariable)步骤来使用命令行参数:1.设置:命令行参数通过获取系统信息(GetSystemInfo)步骤设置,在使用时可以像列名一样来使用,不必像变量一样要通过{var} 这样的格式引用. 用户最多可以设置10个命令行参数
2.传递: 命令行下使用 pan /file:xxx.ktr arg1 arg2 来传递参数.
图形界面下,每次运行时有要求输入参数的提示窗口.
Kettle之效率提升
Kettle作为一款ETL工具,肯定无法避免遇到效率问题,当很大的数据源输入的时候,就会遇到效率的问题。对此有几个解决办法:
1)数据库端创建索引。对需要进行查询的数据库端字段,创建索引,可以在很大程度上提升查询的效率,最多的时候,我不创建索引,一秒钟平均查询4条记录,创建索引之后,一秒钟查询1300条记录。
2)数据库查询和流查询注意使用环境。因为数据库查询为数据输入端输入一条记录,就对目标表进行一次查询,而流查询则是将目标表读取到内存中,数据输入端输入数据时,对内从进行查询,所以,当输入端为大数据量,而被查询表数据量较小(几百条记录),则可以使用流查询,毕竟将目标表读到内存中,查询的速度会有非常大的提升(内存的读写速度是硬盘的几百倍,再加上数据库自身条件的制约,速度影响会更大)。同理,对于目标表是大数据量,还是建议使用数据库查询,不然的话,一下子几百M的内存被干进去了,还是很恐怖的。
3)谨慎使用JavaScript脚本,因为javascript本身效率就不高,当你使用js的时候,就要考虑你每一条记录,就要执行一次js所需要的时间了。
4)数据库commit次数,一条记录和一百条记录commit对效率的影响肯定是不一样的。
5)表输入的sql语句的写法。有些人喜欢在表输入的时候,将所有关联都写进去,要么from N多个表,要么in来in去,这样,就要面对我在2)里面说道的问题,需要注意。
6)注意日志输出,例如选择数据库更新方式,而且日志级别是debug,那么后台就会拼命的输出日志,会在很大程度上影响速度,此处一定要注意。
7)kettle本身的性能绝对是能够应对大型应用的,一般的基于平均行长150的一条记录,假设源数据库,目标数据库以及kettle都分别在几台机器上(最常见的桌面工作模式,双核,1G内存),速度大概都可以到5000 行每秒左右,如果把硬件提高一些,性能还可以提升 , 但是ETL 过程中难免遇到性能问题,下面一些通用的步骤也许能给你一些帮助.
尽量使用数据库连接池
尽量提高批处理的commit size
尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流)
Kettle 是Java 做的,尽量用大一点的内存参数启动Kettle.
可以使用sql 来做的一些操作尽量用sql。Group , merge , stream lookup ,split field 这些操作都是比较慢的,想办法避免他们.,能用sql 就用sql
插入大量数据的时候尽量把索引删掉
尽量避免使用update , delete 操作,尤其是update , 如果可以把update 变成先delete ,后insert .
能使用truncate table 的时候,就不要使用delete all row 这种类似sql
尽量不要用kettle 的calculate 计算步骤,能用数据库本身的sql 就用sql ,不能用sql 就尽量想办法用procedure , 实在不行才是calculate 步骤.
要知道你的性能瓶颈在哪,可能有时候你使用了不恰当的方式,导致整个操作都变慢,观察kettle log 生成的方式来了解你的ETL操作最慢的地方。
远程数据库用文件+FTP 的方式来传数据 ,文件要压缩。(只要不是局域网都可以认为是远程连接)