redis缓存如何应对高并发请求和攻击
缓存使用背景
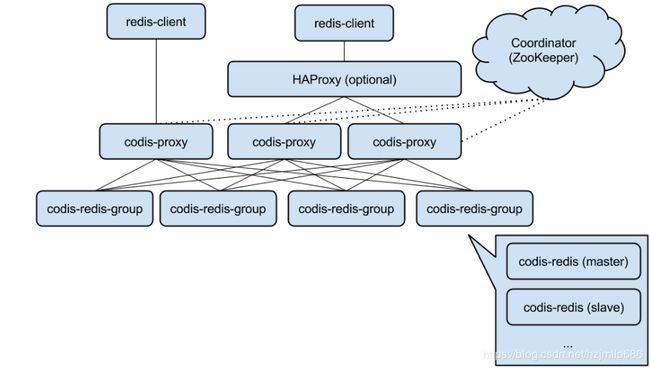
一说缓存使用,相信大多数缓存使用者脑海中第一印象是redis,redis缓存高性能,提供丰富的数据类型,String,list,set,zset,hash。除了上述优势之外还提供多种集群方式,这是Memcached所不具备。redis提供基于Sentinel 机制主从节点集群方案,还提供客户端集群方式RedisSharding,服务端实现集群Cluster、codis。
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有明显的区别 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务。本公司基于原子性数据迁移,在不停机情况实现热扩容和非常友好的后台集群管理的界面(提供热扩容、槽分配,数据迁移等操作),选择了codis 。
言归正传目光焦点还是转移到高并发场景下,缓存如何使用。首先分析一下高并发场景,高并发意味找有大量请求进来,进行数据读写。如果大量请求瞬间直接打到DB层,那估计DB凶多吉少了。数据库一宕机,应用服务直接就跪了。有人说数据库得分库分表吧,没有错,有读写压力就得考虑数据库集群。基于成本考虑,数据库节点不能无限制增加。况且高并发场景下,追求是更快响应速度和更高吞吐量。从数据库读取还是不够快。这时你考虑使用缓存了。
大多数使用场景是这样,把一些经常查询,但不怎么变的数据写入缓存,大概应用使用如下图:
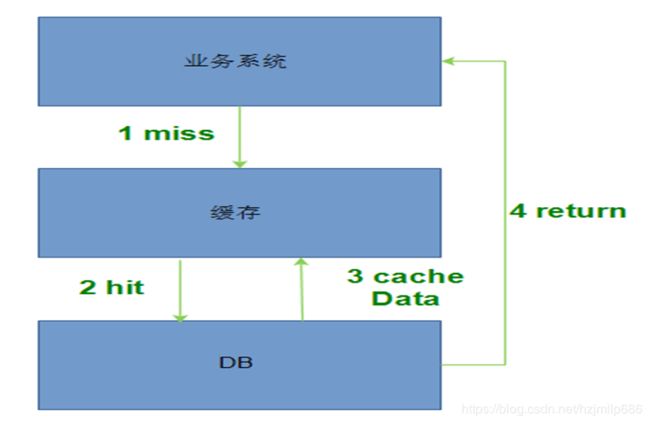
业务系统有请求进来,先查缓存,查不到查DB层,查到后回写缓存,再返回数据。这里称之为“赖加载”模式。这样使用缓存策略一般也不会遇到问题,但当你业务平台越来越大,用户数量越来越大的时候。平台要开始考虑高并发场景下是否系统是否支撑的下去。尤其是考虑瞬间大量请求时,系统如何设计。本文就从缓存这一个层面来分析和设计缓存如何在高并发使用问题。
高并发场景一:
在可预见情况下,新上来应用系统,比如某个产品搞个秒杀活动,瞬间有大量请求来。如果还是采用传统缓存方式- 赖加载。大想可以想象一下,瞬间大量请求到DB层,缓存第一时间没有发生任何作用,应用系统直接就宕机了。甚至影响其他关联服务,进行可以应用系统雪崩。
方案: 数据预热
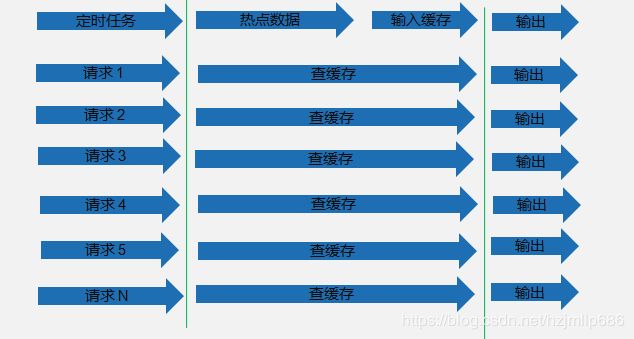
可以先把商品基本信息和库存量等数据通过后台定时批量写入缓存当中,这样就避免大量的这样基础数据信息查询,替数据库挡一挡流量,减轻数据库读写压力,间接保护了数据库。ps:批量导入数据写入缓存,建议可以使用redis的Pipeline。Pipeline提供给类似数据库批处理能力。Redis 管道 (Pipeline) 本身并不是 Redis 服务器直接提供的技术,是由客户端提供的,跟服务器没有什么直接的关系。
高并发场景二 :
比如说商品类的缓存数据过期时间设置过于集中,大量缓存集中失效,这样场景称为缓存雪崩。在缓存大量失效且高并发场景下,大量请求击穿缓存,直击DB。如下图所示:
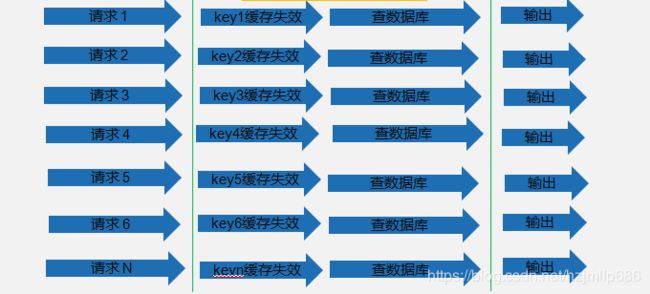
方案:将过期时间散列表开。具体怎么做尼,设置一个过期时间基数+rand.nextInt(n) .这样就避免缓存过期时间集中大量的失效。避免出现缓存雪崩问题。
高并发场景三:
接下来仔细分析一下,应用平台可避免大量缓存失效,但某个key到了过期时间最终还是要失效。在高并发场景下,大量请求还是直击DB。如下图所示:
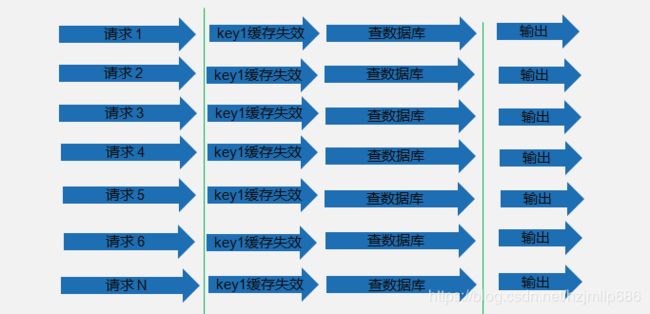
方案:分布式锁
此方案只允许在某个时间只有一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可,整个过程如图 :

当发现某一个热点数据失效后,基于应用系统集群部署,上分布式锁,使用redis 分布式锁命令-setnex.大量请求涌进应用系统时, 只允许某一个请求加锁成功。上锁成功后,允许该请求向数据库发起操作,其余所有的查询请求均被阻塞,从而保护了数据库。
高并发场景四:
接上面继续分析,如果某个key数据实在太热,查询请求海量,就比如微博热搜。单个redis节点都可以撑不住怎么破。
方案:数据散列开
将一份热点数据的key,做成N份,打个比方,将原本key分成key1,key2,key3,分别写入Redis-1,Redis-2,Redis-3,这样数据均匀打散到这三个redis节点上,分担了读压力,缓存就不至于压垮。

高并发场景五:
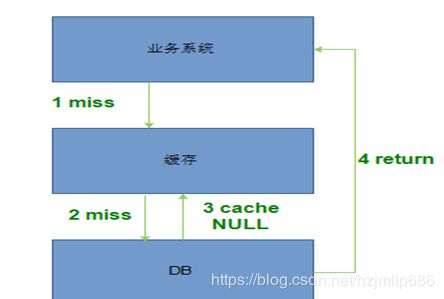
业务应用系统受到黑客大量攻击,查询那些既不在缓存也不在数据库里数据,缓存失去保护DB作用,这种场景业界称之为缓存穿透。发生缓存穿透,高并发场景下,如果是黑客恶意攻击也是致命的。那么在缓存这层怎么作保护方案尼
缓存穿透示意图
方案
1)缓存空数据
将数据库查询结果为空的key也存储在缓存中。当后续又出现该key的查询请求时,缓存直接返回null,而无需查询数据库.
缓存空对象会有两个问题:
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5 分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
2) BloomFilter
众所周知使用布隆过滤器,一个比特位就可以标识一个数据,可以节省大量空间,具体算法原理就不在这里累述了。BloomFilter推荐使用Redis 中的布隆过滤器,不过Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场,布隆过滤器作为一个插件加载到 Redis Server 中。

查询请求进入应用系统,首先去BloomFilter中查询该key是否存在。若不存在,则说明数据库中也不存在该数据,因此缓存都不要查了,直接返回null。若存在,则继续执行后续的流程,先前往缓存中查询,缓存中没有的话再前往数据库中的查询。
缓存空数据 VS BloomFilter
对于一些恶意攻击,查询的key往往各不相同,而且数据贼多。此时,第一种方案就显得提襟见肘了。因为它需要存储所有空数据的key,而这些恶意攻击的key往往各不相同,而且同一个key往往只请求一次。因此即使缓存了这些空数据的key,由于不再使用第二次,因此也起不了保护数据库的作用。
因此,对于空数据的key各不相同、key重复请求概率低的场景而言,应该选择第二种方案。而对于空数据的key数量有限、key重复请求概率较高的场景而言,应该选择第一种方案。
参考引用
http://redisdoc.com
https://blog.csdn.net/haoxin963/article/details/83245113