javascript,chrome与幽灵攻击---JavaScript,chrome with Spectre Attacks
javascript,chrome与幽灵攻击
----JavaScript,chrome with Spectre Attacks
本文主要介绍曾经沸沸扬扬的CPU幽灵及熔断漏洞,以幽灵漏洞为主。之后介绍它们和JavaScript和浏览器之间的关系,还有浏览器对这种漏洞的防御。
CPU与幽灵攻击
分支预测
现代的CPU大部分都带有分支预测和乱序执行的技术,作为现代CPU的一个重要特征,它们用以克服过于繁忙的执行单元在等待上的延迟。以分支预测为例,在计算机中,CPU和内存合作完成程序的执行,但是CPU速度远远快于内存读取的速度,所以会出现这样的情况,比如CPU的一个内存读取单元需要等待内存数据的到达,但现代处理器将不会拖延整个程序的执行,而会向前看,在等待过程中提前推测并执行后面的内容。
此外,在操作系统中存在内存隔离的机制,该机制是为了确保一个程序无法访问属于其他程序的内存区块。
本文要将的分支预测和幽灵漏洞即打破了内存隔离的限制,访问到了受害者存在隐私信息的内存隔离限制。
举个简单的例子, 你写了一系列if语句,进入哪个分支取决于分支条件的检查,而然而在分支条件检查结果还未返回的时候,cpu会进行分支推测,并提前执行分支内代码。当分支检查的结果返回后,cpu会保留或者丢弃刚才的执行结果,但是该过程会影响到高速缓存的内容,而高速缓存的内容不会因为预测错误被清除或回退。cpu这种执行方式,导致可以访问本身不被允许的受害者的内存或者寄存器里面的值,这便是本文所要讲的漏洞内容。
JavaScript与幽灵攻击
幽灵和熔断漏洞是近些年发现的CPU漏洞,并且该漏洞已经影响到我们接触的开发式web平台。
下面以JavaScript条件语句为例,具体介绍下幽灵漏洞。
由于CPU存在分支预测的技术,通过这个技术去预测可能会进入的分支并,并且短暂的改变代码的语义顺序,去提前执行分支内的语句。而不正确的分支预测被攻击者用来从程序的地址空间中读取私密信息。
以这段代码为例:
if (x < array1_size)
y = array2[array1[x] * 4096];
简单的说下攻击者的攻击过程。
在初始阶段,攻击者可以多次用有效的输入值调用这段代码,使代码进入分支内并执行。因此,CPU的分支预测就会期望if的条件未来也是true。接下来,攻击者会控制x,让x是超出array1边界的值。此时的CPU在等待分支判定结果之前,会猜测分支检测会是true。因此在等待的过程中,会预先用带有恶意目的的x值执行分支内语句
y = array2[array1[x] * 4096];
这里要注意,读取array2的值到缓存内与用恶意的x访问array[x]是独立的过程。
当最终条件检测返回结果为false,CPU就会丢弃分支内执行的结果并回退它的状态。但是,刚才预测执行对高速缓存产生的影响并不会被回退,所以攻击者会分析缓存内容,然后找出受害者私密的内容。
虽然就上面代码而言,书写者角度运用条件语句对数组项x的访问做了边界检查,这种写法理论上可以避免对超出array1所占内存以外的敏感数据的访问。但是,本文所要说的就是通过对x的控制访问敏感数据。
下图展示了边界检查与分支预测结合的四种情况。
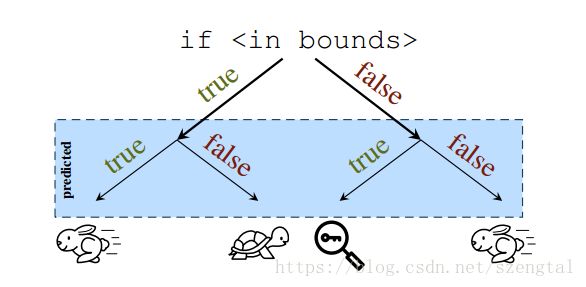
(如图,在边界检查的结果出来之前,分支预测去执行最可能的目标代码,如果预测正确将大幅度提升执行速度。然而,若是预测错误,攻击者可以在某些情况下获取其无权限获取的内存空间的内容,从而泄露私密信息。)
在边界检查的结果出来之前,cpu通过分支预测的技术推测下面最可能去执行的代码。而为什么边界检查的结果不能立即知晓,存在多种原因。比如边界检查过程中需要的数据值在高速缓存未命中,边界检查所需的执行单元阻塞,要依赖复杂的算术运算等等。然而,就像图上一样,正确的分支预测可以大幅度提升执行效率。
不幸的是,在分支预测过程中,边界检查的结果可能会进入另一个分支,这样分支预测就错误了。这个例子中,攻击者可能会这样运行这段代码:
- x的值被恶意控制,从而对array1[x]产生越界访问,返回的是受害者内存中某个私密的内容k。
- array1_size和array2这两个值都未在缓存中,但是k在。
- 先前的运行中,通过攻击者的控制传入有效的x值并进入分支。所以分支预测遇到恶意的x时猜测也会进入分支。
注意,上面所说的高速缓存的命中与否的配置可以自然发生也可以由攻击者创建,因为预测执行的时间有限,所以为了完成攻击,攻击者可以简单的发起多次攻击,这样会把目标内存数据加入高速缓存中。
当上面几条满足情况下,开始运行代码。程序接收到恶意的x,要与array1_size进行比较。读取array1_size发现未命中缓存,这时候程序要面对一个等待的延迟去DRAM中读取array1_size,之后才能进行边界检查判断能否进入分支。此时,分支预测就会假设边界检查为true,进入分支执行代码。因此,分支预测将x与array1的基地址相加,然后从内存中请求这个结果地址所在的数据。这个读取命中缓存,并快速的返回了内容k(上面的条件中已经返回过k),这里假设k为11。
接着,分支预测用k=11去计算array2[k * 4096]的值,再接着去内存中请求这个结果地址的值(这个值是缓存未命中的)。
此时,当去内存中读取array2数据的时候,边界检查的结果可能已经返回了。这时候分支预测发现预测的结果错了,它会重置寄存器的状态。然而,分支预测对array2的读取已经影响了高速缓存的状态,该状态不会被重置,即缓存中已经保存了array2[k * 4096]在k=11的值。
最后,为了完成攻击,攻击者去遍历array2,发现在第[k * 4096]项的时候,访问速度快于其他项,这时候攻击通过时间测量就可以知道k是11,而k则来源于受害者之前因内存隔离而无法访问到的其他内存区块中的私密信息。
幽灵漏洞的解决
由于这是硬件层面的漏洞,在新的硬件出来之前,解决幽灵漏洞有几个有效的途径:
- 关闭分支预测和乱序执行,不要保留缓存。但这种方法会导致CPU性能下降,因为这些技术对于性能的提升很重要
- 以上面例子为例,告诉CPU获得条件语句的分支检测结果之前,不要预测执行,即在小范围内关掉分支预测。
上面就是幽灵漏洞的攻击过程。接下来介绍下这种CPU漏洞与JavaScript和浏览器之间关系,以及目前的防范措施。
chrome对幽灵漏洞的防范
目前chrome采用多进程架构。即每一个你打开的标签都是一个独立渲染进程。但在之前(chrome67以前,chrome67手动启动),同一个标签页中跨站点iframe和跨站点弹出窗口通常与创建它们的标签存在于同一个渲染进程,共享同一个渲染进程的内存空间。
这时候,若是在恶意站点内嵌入安全的站点如银行网站并诱导用户访问,由于同个标签页中的内容包括iframe都处于同一个渲染进程的内存空间中,这使得幽灵攻击能够成功的获得到iframe内的数据,比如用户密码,cookie等。
浏览器针对这种幽灵攻击的解决办法叫做站点隔离—Site Isolation。
站点隔离对于chrome架构来说是一个比较大的改变。通过这项技术,将每个渲染器进程限制为来自单个站点的文档。这种方式的好处是可以依赖操作系统来保护不同进程之间数据的独立性
举个例子,url=https://google.co.uk 和它的子站点 url=https://maps.google.co.uk 就会处于同一个渲染进程中。
回到上面那个例子。现在,由于恶意站点和嵌入的安全站点分属于不同站点,因此chrome会为它们创造不同的渲染进程,不同站点因此被隔离到不同的内存空间中,幽灵攻击此时将无法获取到浏览器内部的跨站数据了。见下图。

但是,仅仅为每个站点创建单独的渲染进程还不足以完全避免幽灵攻击。
在现代浏览器中,遵循着一个叫做同源策略的机制,即限制不同源之间数据的访问。但是由于某些历史原因,一些web特性如 或者