对异常检测技术的简要概述(干货)
转载请注明作者和出处:http://blog.csdn.net/u013829973
我的GitHub:https://github.com/weepon
欢迎评论,顶!
- 什么是离群值如何处理它们
- 离群值的类型
- 数据集中出现异常值的最常见原因
- 一些最流行的离群检测方法是
- Z-Score
- Dbscan
- Isolation Forests
- 总结Conclusions
- Z-Score 优点
- Z-Score 缺点
- Dbscan 优点
- Dbscan 缺点
- Isolation Forest 优点
- Isolation Forest缺点
今天和大家简单聊聊异常检测技术的简要概述。

什么是离群值,如何处理它们?
“Observation which deviates so much from other observations as to arouse suspicion it was generated by a different mechanism” — Hawkins(1980)
异常值是偏离数据其他观测值的极端值,它们可能表示测量的可变性,实验误差或新事物。 换句话说,异常值是偏离整体样本的观察值。
离群值的类型
异常值可以是两种:单变量和多变量。 当查看单个特征空间中的值分布时,可以找到单变量异常值。 多变量异常值可以在n维空间(n个特征)中找到。 观察n维空间中的分布对于人类大脑来说可能非常困难,这就是为什么我们需要训练一个模型。
不同的环境,异常值也可以有不同的风格:点异常值,背景异常值或集体离群值。 点异常值是与分布的其余部分相距甚远的单个数据点。 语境异常值可以是数据中的噪声,例如在进行语音识别时实现文本分析或背景噪声信号时的标点符号。 集体异常值可以是诸如可能指示发现新现象的信号的数据的新颖性子集(如图B所示)。
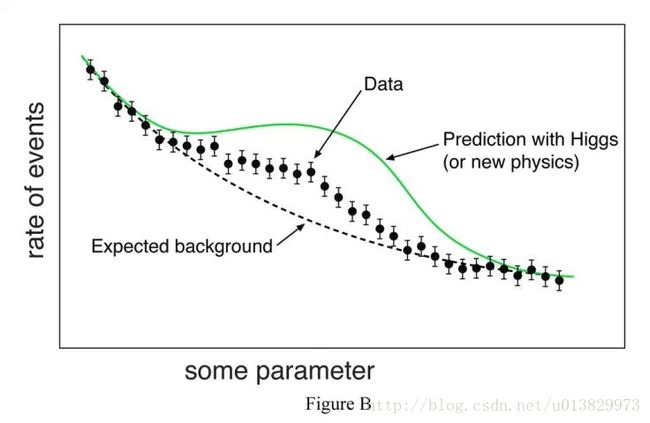
数据集中出现异常值的最常见原因:
数据输入误差(人为误差)
测量误差(仪器错误)
实验误差(数据提取或实验计划/执行误差)
故意的(测试检测方法的假异常值)
数据处理错误(数据处理或数据设置意外突变)
抽样错误(提取或混合来自错误或不同来源的数据)
自然(不是错误,数据中的新奇)
在制作,收集,处理和分析数据的过程中,异常值可以来自许多来源,并在许多方面隐藏起来, 那些不是错误的产物被称为新奇。
检测异常值对于几乎任何定量学科都是至关重要的(即:物理,经济,金融,机器学习,网络安全)。 在机器学习和任何定量学科中,数据质量与预测或分类的模型一样重要。
当试图在数据集中检测离群值时,记住上下文并尝试回答这个问题非常重要:“为什么我要检测离群值?你的发现的意义将由上下文决定。
此外,当开始一个离群的检测任务时,你必须回答关于你的数据集的两个重要问题:此外,当开始一个离群的检测任务时,你必须回答关于你的数据集的两个重要问题:
- 我要考虑哪些特征来检测离群值?(单变量或多变量)我要考虑哪些特征来检测离群值?(单变量或多变量)
- 我可以为我选择的特性假设一个值的分布吗?(参数/非参数)
一些最流行的离群检测方法是:
z分数(Z-Score )或极值分析(参数)
概率和统计建模(参数)
线性回归模型(PCA,LMS)
基于邻近模型(非参数)
信息理论模型
高维离群检测方法(高维稀疏数据)
Z-Score
一个观测的z分数或标准分数是一个度量,表示一个数据点偏离样本均值的多少个标准差,假设一个高斯分布。这使得z分数是一个参数化的方法。非常频繁的数据点并不是由高斯分布描述的,这个问题可以通过将转换应用于数据,比如:缩放它来解决。
一些Python库,如Scipy和scikit学习,可以很容易地使用函数和类利用Pandas和Numpy轻松实现。在对数据集的选定特征空间进行适当的转换之后,任何数据点的z分数都可以用以下表达式计算:

当计算数据的每个样本的z分数时,必须指定一个阈值。一些好的“thumb-rule”阈值可以是:2.5、3、3.5或更高的标准差。
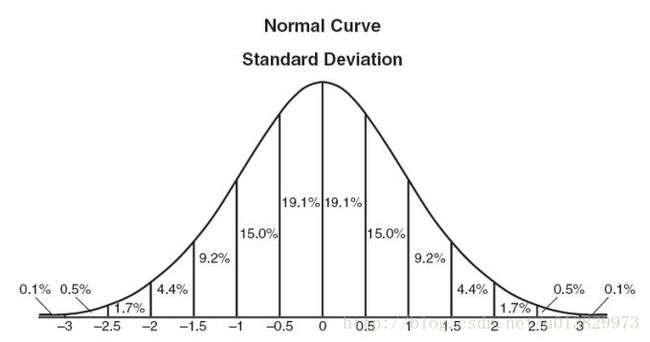
通过“标记”或删除超出给定阈值的数据点,我们将数据分类为异常值,和非异常值。
z - score是一种简单但强大的方法,如果你处理的是一个低维度特征空间的参数分布,就可以摆脱数据中的异常值。对于非参数问题, Dbscan和 Isolation Forests是很好的解决方案。
Dbscan
机器学习和数据分析聚类方法是帮助我们更好地可视化和理解数据的有用工具。数据集中的特性、趋势和种群之间的关系可以通过像dbscan这样的聚类方法来表示,也可以应用于许多维度上的非参数分布中的异常值。
Dbscan(Density Based Spatial Clustering of Applications with Noise)是基于密度的聚类算法,重点是发现邻居的密度(MinPts)在n维球体的半径ɛ。
集群可以被定义为特征空间中“密度连接点”的最大集合。
Dbscan定义不同类型的点:
核心点:A是一个核心的区域(ɛ所定义的)包含至少比参数MinPts同样多或更多的点。
边界点:C是一个位于集群中的边界点,它的邻域并不包含比MinPts更多的点,但它仍然是集群中其他点的“密度可达”。
离群点:N是一个离群点,在没有集群的情况下,它不是“密度可达”或“密度连接”到任何其他点。因此,这一点将有“他自己的集群”。
-

如果A是一个核心点,它就会形成一个集群,所有的点都可以从中得到。通过P可获得点P如果有一个路径 p1,…,pn 与 p1=p 和 pn=q ,其中每个 pi+1 是直接可以从 p (所有路径上的点必须核心点,可能 q 除外)。
可达性是一种非对称的关系,从定义上说,无论距离如何,都不能从非核心点到达任何点(因此,非核心点可能是可到达的,但它达不到任何点)。因此,需要进一步的连接概念来正式定义该算法所发现的集群的范围。
两个点p和q是密度连接的,如果有一个点o,那么p和q都是密度可达的。密度-连接度是对称的。
一个集群满足两个属性:
集群中的所有点都是相互关联的。
如果某个点从集群的任何一点处都可以到达,那么它也是集群的一部分。
scikit-learn有利用pandas实现的dbscan离群检测模型。
第一步是缩放数据,从半径ɛ随着MinPts定义邻域。(提示:对于手边的问题,一个好的scaler可以是scikit-learn的 Robust Scaler)。
在扩展特性空间之后,是时候选择dbscan执行集群的空间度量了。必须根据问题选择度量,欧几里得距离在二维或三维空间中工作得很好,在处理高维空间4或更多维度时,曼哈顿度距离也很有用。然后,根据聚类选择相应的参数eps(ɛ)。如果ɛ太大了许多点密度连接,如果太小聚类将导致许多无意义的集群。一个好的方法是尝试从0.25到0.75不等的值。
Dbscan对MinPts参数也很敏感,它将完全依赖于手动调整的问题。dbscan的复杂度为O(n log n),它是一种具有中等大小的数据集的有效方法。当使用Scikit-learn的实现时,向模型提供数据是很容易的。在将dbscan安装到数据集群之后,可以提取并将每个样本分配给一个集群。Dbscan自己估计集群的数量,没有必要指定所需集群的数量,它是一个无监督机器学习模型。
异常值(噪声)将被分配给- 1集群。在标记这些实例之后,它们可以被删除或分析。
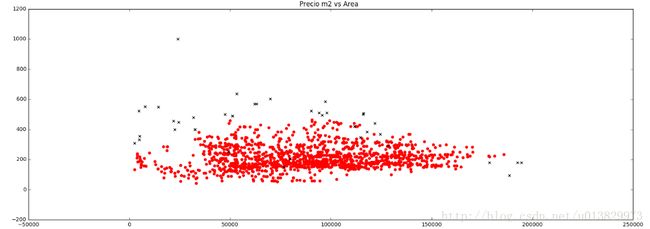
Real world application of DBSCAN in housing prices (red:normal, black: outliers)
Isolation Forests
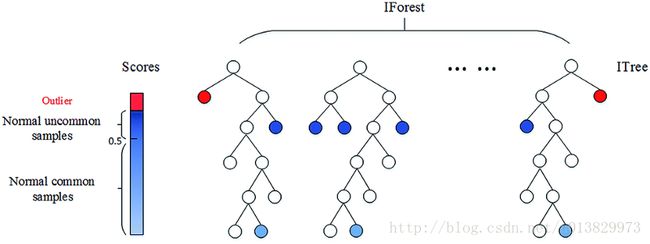
最后,Isolation Forests是检测数据中的异常值或新奇事物的有效方法,它基于二叉决策树。scikit-learn的实现相对简单易懂。
Isolation Forests的基本原则是,离群值很少,而且远离其他观测值。为了构建树(训练),该算法从特征空间随机抽取一个特征,并在最大值和最小值之间随机选择一个分割值。这是为训练集的所有观察值而制定的。为了建造森林,一棵树的集合是使森林里的所有树木都平均。然后,对于预测,它将观察值与“节点”中拆分值对比,该节点将有两个子节点,然后进行另一个随机比较。一个实例的算法所产生的“splittings”的数量被命名为:“路径长度”。正如预期的那样,离群值将比其他观测值的路径长度更长。
每个观测值可以计算出一个离群值:

其中h(x)为样本x的路径长度,c(n)为二叉树的“不成功的长度搜索”(从根到外节点的二叉树的最大路径长度)n为外部节点数。在给每个观察值打分(得分从0到1不等)后,1代表更多的“孤立”和“0”意味着更正常。可以指定一个阈值,比如0.55或0.60。
提示:在scikit- learn的库中,分数移位了0.5和1,所以它返回 - 0.5到0.5的值,越大越正常,越小的越不正常。
总结(Conclusions)
Z-Score 优点
如果你可以用高斯分布来描述特征空间中的值,这是一种非常有效的方法。(参数)
使用pandas和scipy等库可以很容易实现。
Z-Score 缺点
在一个小到中等大小的数据集中,只有在低维的特征空间中使用。
当分布不能被假定为参数时,不建议使用。
Dbscan 优点
当特征空间中的值分布不是假设的时,这是一种非常有效的方法。
如果搜索异常值的特征空间是多维的(比如:3或更多的维度),则可以很好地工作。
用Scikit learn实现简单,且文档很棒
可视化结果很简单,方法本身也很直观。
Dbscan 缺点
特征空间中的值需要相应地伸缩。
选择最优参数eps,MinPts和度规可能很困难,因为它对任何三个参数都非常敏感。
它是一个无监督的模型,需要在每次分析新的数据时重新校准。
它可以预测一次校准,但强烈不推荐。
Isolation Forest 优点
在特性空间中不需要缩放值。
当值分布不能被假设时,它是一种有效的方法。
它具有很少的参数,这使得该方法相当健壮且易于优化。
scikit- learn的实现很容易使用,而且文档非常出色。
Isolation Forest缺点
Python实现仅存在于Sklearn的开发版本中。
可视化的结果是复杂的。
如果没有正确的优化,训练时间可以很长,计算费用也很昂贵。
参考:
https://medium.com/towards-data-science/a-brief-overview-of-outlier-detection-techniques-1e0b2c19e561
如有不当之处,请留言!