1.简介
正则表达式为高级文本模式匹配,以及搜索-替代等功能提供了基础。Python通过re模块支持正则表达式。
2.匹配与搜索
在python专门术语中,有两种主要方法完成模式匹配:搜索(searching)和匹配(matching),搜索,即在字符串任意部分中搜索匹配的模式,而匹配是指,判断一个字符串能否从起始处全部或者部分的匹配某个模式。搜索通过search()函数或者方法来实现,而匹配是以match()函数或者方法来实现的。
3.正则表达式使用的特殊符号和字符
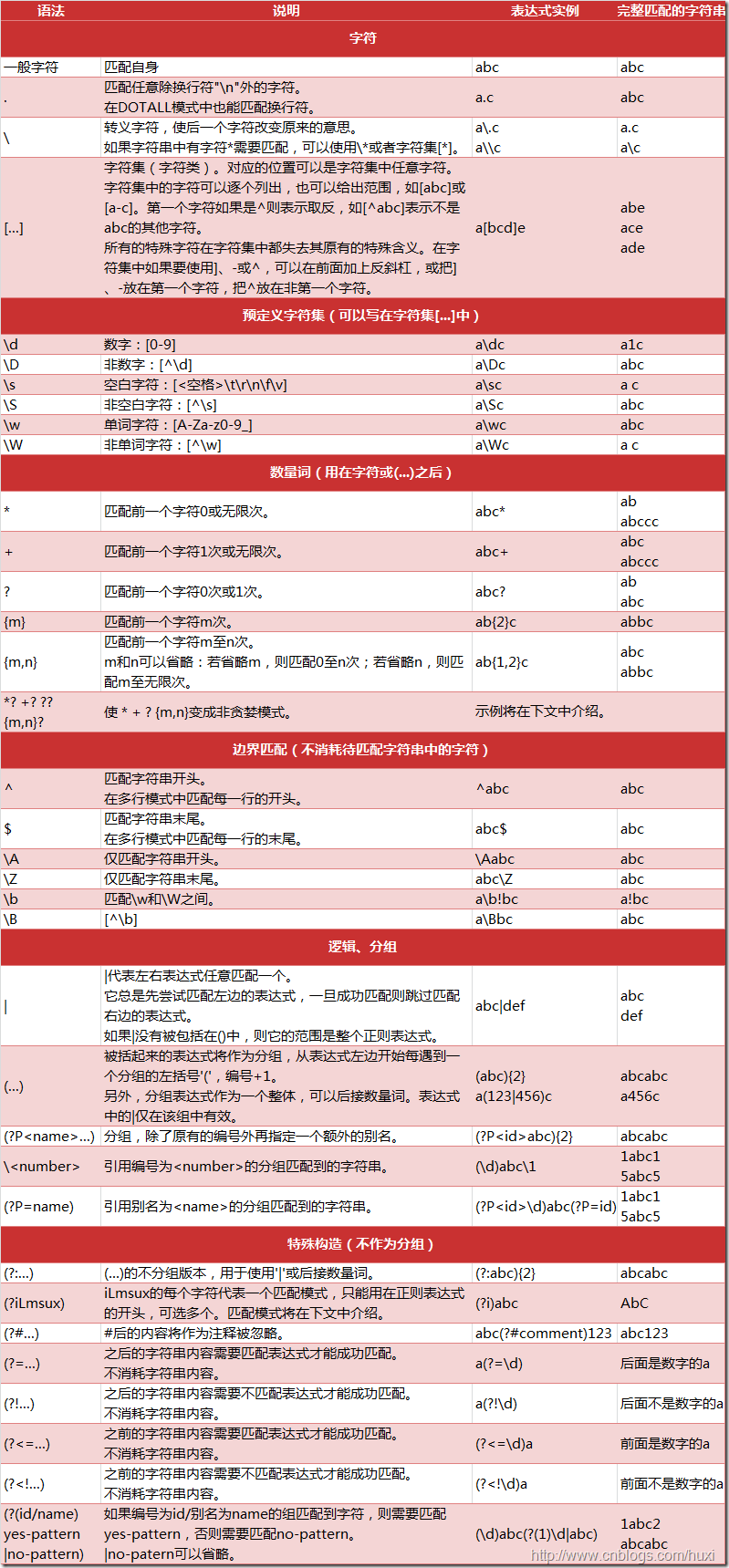
4.re模块
核心函数和方法
re.match(pattern, string[, flags]):
m1=re.match("[0-9]{0,10}","12312312szdfafs567sadf") #匹配0到10个连续的数字
print m1 #<_sre.SRE_Match object at 0x000000000331BE00>
if m1:
print m1.group() #12312312
*************************************
m1=re.match("[0-9]{10}","12312312szdfafs567sadf") #匹配10个连续的数字数字
print m1 #None,因为12312312这个没有10个
if m1:
print m1.group() 这个方法将从string的开始处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达结尾,则返回None。
–
re.search(pattern, string[, flags]):
m2=re.search("\d","a75_46.5 4a~bc6@def") #从左开始一个一个查找
if m2:
print m2.group() #7
这个方法用于查找字符串中可以匹配成功的子串。从string的开始处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将下标加1后重新尝试匹配;直到到结尾时仍无法匹配则返回None。
search()与match()对比
>>> m=re.match("\d+","12assd3124") #从头开始查找,有匹配的就返回,没有就None
>>> print m
<_sre.SRE_Match object at 0x00000000033AA510>
>>> m.group()
'12'
>>> m=re.match("\d+","asd12assd3124")#开头不是数字,匹配失败,返回None
>>> m.group()
Traceback (most recent call last):
File "" , line 1, in
AttributeError: 'NoneType' object has no attribute 'group'
>>> m=re.search("\d+","asd12assd3124")#开头不是数字,索引加1在匹配,匹配到一个就返回,索引到末尾还没有匹配就返回None
>>> m.group()
'12'
>>>
>>> m=re.search("\d+","asdqweqweqwe")
>>> print m
None
>>>
–
re.findall(pattern, string[, flags]):
m2=re.findall("[a-zA-Z]","14123sasdasdcv3434234")#匹配所有的单个字母
print m2 #['s', 'a', 's', 'd', 'a', 's', 'd', 'c', 'v']
m2=re.findall("[a-zA-Z]{3,5}","14123sasdasdcv3434234")
print m2 #['sasda', 'sdcv'] 贪吃原则,先匹配最长的,即先匹配5个字符,剩下的
m2=re.findall(".","14123sasdasdcv3434234") #匹配任意单个字符
print m2 #['1', '4', '1', '2', '3', 's', 'a', 's', 'd', 'a', 's', 'd', 'c', 'v', '3', '4', '3', '4', '2', '3', '4']
m2=re.findall(".*","14123sasdasdcv3434234") #匹配任意多(0到无穷)个任意字符
print m2 #['14123sasdasdcv3434234', ''] 为什么有空的,因为0个也算是一个
m2=re.findall(".+","14123sasdasdcv3434234") #匹配任意多(1到无穷)个任意字符
print m2 #['14123sasdasdcv3434234']
搜索string,以列表形式返回全部能匹配的子串。
–
re.sub(pattern, repl, string[, count]):
m2=re.sub("\d",'|',"a75_46.5 4a~bc6@def",count=2) #将前两个数字替换成“|”,
print m2 #a||_46.5 4a~bc6@def使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
–
re.split(pattern, string[, maxsplit]):
import re
print re.split('\d+','one1two2three3four4')
### output ###
# ['one', 'two', 'three', 'four', '']
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
匹配对象和group(),groups()方法
在处理正则表达式的时候,除了regex对象之外,还有一种对象类型匹配对象,这些对象是在match()或者search()被成功调用后返回的结果,匹配对象主要有两种方法,group(),groups()
group()方法或者返回所有的匹配对象或是根据要求返回某个特定子组。groups()很简单,他返回一个包含唯一或者所有子组的元组。
示例
用于练习的数据生成代码
from random import randint,choice
from string import lowercase
from sys import maxint
from time import ctime
doms=('com','edu','net','org','gov')
for i in range(randint(5,10)):
dtint=randint(0,maxint-1)
dtstr=ctime(dtint)
shorter=randint(4,7)
em=''
for j in range(shorter):
em+=choice(lowercase)
longer=randint(shorter,12)
dn=''
for j in range(longer):
dn+=choice(lowercase)
Sun May 03 19:31:12 1992::[email protected]::704892672-5-7
Mon Apr 08 13:27:52 2002::[email protected]::1018243672-7-11
Wed May 24 12:18:11 2017::[email protected]::1495599491-6-9
Tue May 16 12:01:36 2000::[email protected]::958449696-6-8
Sat Jan 19 18:14:04 2036::[email protected]::2084350444-5-10
Fri Jan 12 01:07:32 2035::[email protected]::2052148052-6-12
Thu Aug 15 23:51:19 2002::[email protected]::1029426679-6-11
Fri Jun 18 08:45:36 2032::[email protected]::1971132336-6-11
用生成的这些字符串进行匹配练习
待续5.常用的正则表达式收集
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配URL的正则表达式:http://([w-]+.)+[w-]+(/[w- ./?%&=]*)?
匹配HTML标记的正则表达式:/<(.*)>.*|<(.*) />/
匹配IP地址的正则表达式 :/(d+).(d+).(d+).(d+)/g
验证Email地址:^w+[-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$
验证URL:^http://([w-]+.)+[w-]+(/[w-./?%&=]*)?$
验证用户密码:^[a-zA-Z]w{5,17}$ 正确格式为:以字母开头,长度在6-18之间