JDK源码阅读,手写HashMap
HashMap是jdk提供的最常用的容器之一,jdk 1.7及之前版本,HashMap底层基于数组和单链表结构,数组每个元素是一对键值对对象,该对象包括hash值,key,value以及单链表下一个键值对的引用。jdk 1.8对HashMap底层结构做了一些改进,当数组同一位置的键值对超过8个,不再以单链表形式存储,而是改为红黑树。进一步提升了性能。
本文基于jdk 1.7,参考源码,手写一个简单的HashMap,实现自动扩容功能、put、get、entrySet方法。
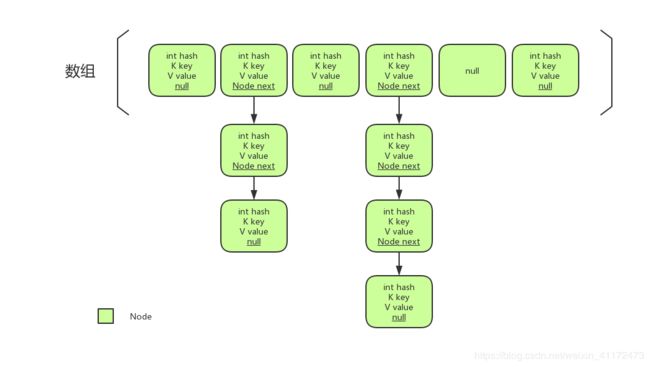
HashMap结构如下图:
1、HashMap的一些性质
通过阅读源码,相较于HashTable,HashMap有以下性质:
- 线程安全:Hashtable线程安全,同步,同步方式是锁住整个Hashtable,效率相对低下
HashMap线程不安全,非同步,效率相对高 - 父类:Hashtable是Dictionary
HashMap是AbstractMap - null值:Hashtable键与值不能为null
HashMap键最多一个null,值可以多个null - 初始容量:HashMap的初始容量为16,
Hashtable初始容量为11 - 扩容方式:HashMap扩容时是当前容量翻倍即:capacity2,
Hashtable扩容时是容量翻倍+1即:capacity2+1。 - 计算hash的方法:HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸。
Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模 - 存储结构:jdk1.8以后,HashMap在链表长度超过阈值时,改用数组+红黑树的方式存储
Hashtable采用数组+链表方式存储
这些性质都体现在源码中,通过代码,可以有更深刻的认识。
2、手写HashMap
这里还是用常规命名MyHashMap作为我们的HashMap的类名
定义接口 MyMap
public interface MyMap<K, V> {
V put(K k,V v);
V get(K k);
Set<? extends Entry<K, V>> entrySet();
interface Entry<K, V>{
K getKey();
V getValue();
}
}
这里定义了后面即将去实现的三个方法,和一个内部接口类型。
MyhashMap的一些属性
public class MyHashMap<K,V> implements MyMap<K,V> {
//默认初始化的容量,16
private static final int DEFAULT_INITIAL_CAPACITY = 1<<4;
//默认初始化的扩容因子
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
//容量
private int initialCapacity;
//扩容因子
private float loadFactor;
//Entry数量,也就是map的长度
int size;
//entry数组
private Node<K,V>[] table;
有两个常量,一个初始化容量16,一个扩容因子0.75,都与jdk源码保持一致。两个变量initialCapacity,loadFactor就是对应的两个属性,size是MyHashMap键值对个数,table是存放键值对的数组。
前面说了HashMap是基于数组+链表形式存储键值对,那么链表数据结构就在下面的静态内部类Node的结构中体现
静态内部类 Node
static class Node<K,V> implements MyMap.Entry<K,V>{
K key;
V value;
Node<K,V> next;
public Node() {
}
Node(K key, V value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Node<?, ?> node = (Node<?, ?>) o;
return Objects.equals(key, node.key) &&
Objects.equals(value, node.value);
}
@Override
public int hashCode() {
return Objects.hash(key, value);
}
@Override
public String toString() {
return key+"="+value;
}
}
Node类实现前面定义的MyMap.Entry接口,有三个属性,key、value以及单链表下一个节点的引用,实际上jdk源码还有一个hash属性存储hash值,这里简化掉。Node的两个方法getKey,getValue非常简单,获取键和值,源码有个setValue方法,这里也简化掉,:)然后就是重写hashCode方法和equals方法,使得判断两个Node相等的依据是key值和value值都相等。
MyHashMap的构造方法
public MyHashMap(int initialCapacity, float loadFactor) {
if (initialCapacity<0) {
throw new IllegalArgumentException("Illegal initial capacity: "+initialCapacity);
}
if (loadFactor <= 0 || Float.isNaN(loadFactor)){
throw new IllegalArgumentException("Illegal load factor: " +loadFactor);
}
this.loadFactor = loadFactor;
this.initialCapacity = initialCapacity;
this.table = new Node[this.initialCapacity];
}
public MyHashMap() {
this(DEFAULT_INITIAL_CAPACITY,DEFAULT_LOAD_FACTOR);
}
用户可以构造自定义初始容量和扩容因子的MyHashMap,如果自定义的数据不合法,抛出运行时异常。使用空构造是使用默认的16和0.75作为初始容量和扩容因子。非常简单。
put方法
接下来看put方法
@Override
public V put(K key, V value) {
V oldValue = null;
//是否需要扩容
if (size>=initialCapacity*loadFactor){
//数组容量扩大为两倍
expand(2*initialCapacity);
}
//根据key的hash值确定应该放入的数组位置
int index = hash(key)&(initialCapacity-1);
if (table[index]==null){
table[index] = new Node<K,V>(key,value,null);
}else{//遍历单链表
Node<K,V> node = table[index];
Node<K,V> e = node;
while(e!=null){
if (e.key==key||e.key.equals(key)){
oldValue = e.value;
e.value=value;
return oldValue;
}
e = e.next;
}
table[index] = new Node<K,V>(key,value,node);
}
++size;
return oldValue;
}
插入node之前先检查键值对数量是否大于容量*扩容因子,若超过则需先扩容。扩容方法和hash方法后面再看。
put方法返回值为map中对应key原来的value值,若存在该key,更新其value值,并返回旧值;
若不存在该key,则通过hash取模将键值对插入到数组对应index的位置,若该位置有其他node,将要插入的键值对插入到单链表头部。size加1.
get方法
获取对应key值的键值对的value值。
@Override
public V get(K key) {
int index = hash(key)&(initialCapacity-1);
Node<K,V> e = table[index];
while(e!=null){
if (e.key==key||e.key.equals(key)){
return e.value;
}
e=e.next;
}
return null;
}
根据key的hash得到数组index,遍历该位置的单链表获取键值对。
entrySet方法
@Override
public Set<Node<K, V>> entrySet() {
Set<Node<K,V>> set = new HashSet<>();
for (Node<K,V> node:table){
while(node!=null){
set.add(node);
node = node.next;
}
}
return set;
}
遍历数组和链表,返回所有键值对的集合。
扩容方法 expand
//扩容方法,将旧数组的数据取出来通过put方法放进新数组
private void expand(int i) {
Node<K,V> [] newTable = new Node[i];
initialCapacity = i;
size = 0;
Set<Node<K, V>> set = entrySet();
//替换数组引用
if (newTable.length>0){
table = newTable;
}
for (Node<K,V> node:set){
put(node.key,node.value);
}
}
源码里该方法叫resize,通过entrySet方法获取所有键值对的集合,put进新的数组里面。
hash方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
}
参考源码的hash方法。
以上就是完整的MyHashMap类。实现HashMap的基本功能。
测试类:
public class TestMain {
public static void main(String[] args) {
MyHashMap<String, String> myHashMap = new MyHashMap<>();
//put()
for (int i = 1; i <=500 ; i++) {
myHashMap.put("KEY_"+i,"VALUE_"+i);
}
//size
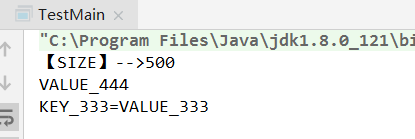
System.out.println("【SIZE】-->"+myHashMap.size);
//get()
System.out.println(myHashMap.get("KEY_444"));
//entrySet()
for (MyHashMap.Node<String, String> entry : myHashMap.entrySet()) {
if(entry.getKey().equals("KEY_333"))
System.out.println(entry);
}
}
}
运行结果: