纯Python实现手写数字的识别+GUI界面
目录
纯Python实现手写数字的识别+GUI界面
安装必要的库
下载mnist数据集
解析图片与标签
导入相关库
将图片28*28矩阵转换为1*784向量
训练所有60000张数字图片并构建分类器
保存模型与加载模型
根据测试图片预测数字
GUI的实现
纯Python实现手写数字的识别+GUI界面
基于python sklearn knn算法,数据集mnist
安装必要的库
pip install scikit-learn
pip install numpy
pip install wxPython
安装PIL库
下载mnist数据集
http://yann.lecun.com/exdb/mnist/
解析图片与标签
我的基本想法是把训练集中的图片与各自标签对应,以实现分类。
而下载mnist数据集得到的是需要进行解析的文件,无法直接查看,
所以我们需要先把图片解析出来,由于我们要知道每张图片的数字标签,所以为了后期易于获取,我在解析标签的过程中,将每个数字标签直接保存在对应的图片的文件名中,并且是文件名的第一个字符。
训练集处理示例如下:(请读者根据自己保存文件的目录对以下代码进行灵活处理)
#!/usr/bin/python
# -*- coding:utf-8 -*-
import struct
import numpy as np
import PIL.Image
'''解析训练标签后得到数字并保存在解析的图片文件名中'''
def getTrainLabels():
f1 = open("C:/Users/asus/Desktop/mnist_data/train-labels.idx1-ubyte", 'rb')
buf1 = f1.read()
f1.close()
index = 0
magic, num = struct.unpack_from(">II", buf1, 0)
index += struct.calcsize('>II')
labs = []
labs = struct.unpack_from('>' + str(num) + 'B', buf1, index)
return labs
filename = 'C:/Users/asus/Desktop/mnist_data/train-images.idx3-ubyte'
binfile = open(filename, 'rb')
buf = binfile.read()
index = 0
magic, numImages, numRows, numColumns = struct.unpack_from('>IIII', buf, index)
index += struct.calcsize('>IIII')
for image in range(0, numImages):
im = struct.unpack_from('>784B', buf, index)
index += struct.calcsize('>784B')
im = np.array(im, dtype='uint8')
im = im.reshape(28, 28)
im = PIL.Image.fromarray(im)
label = getTrainLabels()
imagenumber = label[image]
im.save('C:/Users/asus/Desktop/mnist_train/%s_train_%s.bmp' % (imagenumber, image), 'bmp')
测试集原理同上,在此省略。
导入相关库
import numpy as np
import os
from PIL import Image
from sklearn.neighbors import KNeighborsClassifier as knn
from sklearn.externals import joblib将图片28*28矩阵转换为1*784向量
def image_vector(fname):
im = Image.open("C:/Users/asus/PycharmProjects/mnist_train/"+fname).convert('L')
im = im.resize((28, 28))
tmp = np.array(im)
vector = tmp.ravel() # 转换成1*784的向量
return vector
将测试图片转换为向量原理同上,仅需更改文件目录即可。
训练所有60000张数字图片并构建分类器
训练60000张保存模型和加载模型耗时较长,但准确率有保证,可考虑利用随机训练n张图片以提高效率,但可能准确率会下降。
'''训练60000张图片'''
def split_data(paths):
fn_list = os.listdir(paths)
X = []
y = []
d0 = fn_list
for i, name in enumerate(d0):
y.append(name[0]) # 获取文件名的第一个字符,例如0_train_1.bmp,则得到数字标签0
X.append(image_vector(name)) # 获取图片并利用函数转换为1*784向量
return X, y
'''构建分类器'''
def knn_clf(X_train, y_train_label):
classifier = knn()
classifier.fit(X_train, y_train_label)
return classifier
保存模型与加载模型
保存模型的一般结构为:
joblib.dump(model, output_name)注意:此处的model为一个分类器
加载模型的一般结构为:
joblib.load(model)注意:此处的moel为之前保存的模型文件名
根据测试图片预测数字
通过转换向量、构建分类器、保存模型后,只需要先对测试图片进行向量转换,然后加载模型对数字进行预测即识别。
在此转换向量的函数原理同训练集,故省略。
def test(test_sample):
load_model('mnist_knn60000.m')
test_result = clf.predict(testdata(test_sample))
return test_result[0]
最后打印test_result,就是我们程序识别的结果。
GUI的实现
我的GUI实现是利用wxPython实现的,
其实主要分为两个重点:①设置按钮,点击后弹出窗口可进行识别图片的选择②选择图片后调用之前写好的model.py中的最终测试函数,打印识别结果。
界面的布局较简单,大家可以参考:https://www.yiibai.com/wxpython
注意设置按钮后一定要绑定对应的选择图片的函数。
注意调用函数的导入方法:from model import test
最终效果如下图:
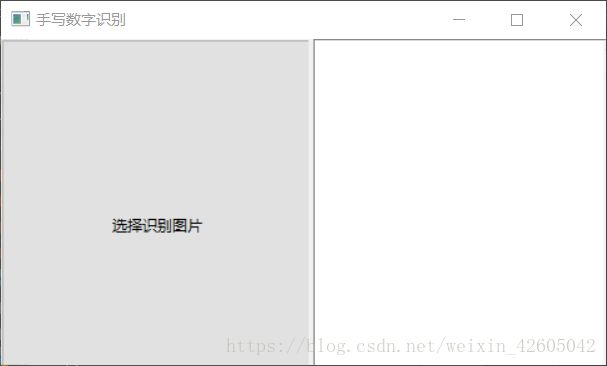
另外我还设置了图片显示:
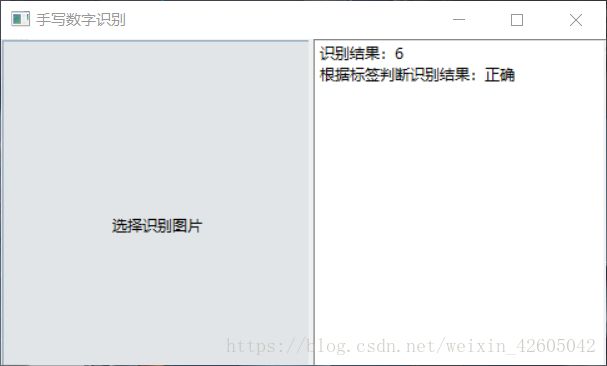
主要内容就是这么多,此文章只是个人的一个学习笔记,正在学习纯Python实现手写识别数字的朋友只需要了解我的大致思路即可,学习还是要自己实践操作。
部分内容我参考了此篇博客:https://www.cnblogs.com/demodashi/p/9452947.html