感知机算法学习笔记(带例题及代码)
感知机
感知机是二分类的线性分类模型,其输入为实例的特征向量,输出实例为类别,取+1和-1二值,属于判别模型。感知机学习旨在求出能够将训练数据集进行正确的分类的分离超平面的。为此,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。感知机具有简单易实现的优点,分为原始和对偶形式。
感知机模型
定义:称函数 y = f ( x ) = s i g n ( ω ⋅ x i + b ) y=f(x)=sign(\omega \cdot x_{i}+b) y=f(x)=sign(ω⋅xi+b)为感知机,其中 ω ∈ R n , x ∈ X ⊆ R n , ω ≠ 0 , B ∈ R , s i g n \omega \in\mathbb{R}^{n} ,x\in X\subseteq \mathbb{R}^{n},\omega \neq 0,B\in R,sign ω∈Rn,x∈X⊆Rn,ω̸=0,B∈R,sign为符号函数,即对任意 z ∈ R z\in \mathbb{R} z∈R,有 s i g n = { + 1 z > 0 0 z = 0 − 1 z < 0 sign=\left\{\begin{matrix} +1 & & z>0\\ 0& &z=0 \\ -1& &z<0 \end{matrix}\right. sign=⎩⎨⎧+10−1z>0z=0z<0对于任意输入 x ∈ X ⊆ R n x\in X\subseteq \mathbb{R}^{n} x∈X⊆Rn,感知机的输出是+1或-1中的一个。在几何意义上, ω ⋅ x i + b = 0 \omega \cdot x_{i}+b=0 ω⋅xi+b=0是 R n \mathbb{R}^{n} Rn的一个分离超平面S, R n \mathbb{R}^{n} Rn被划分到分离超平面的两侧,输入感知机后得到+1或-1。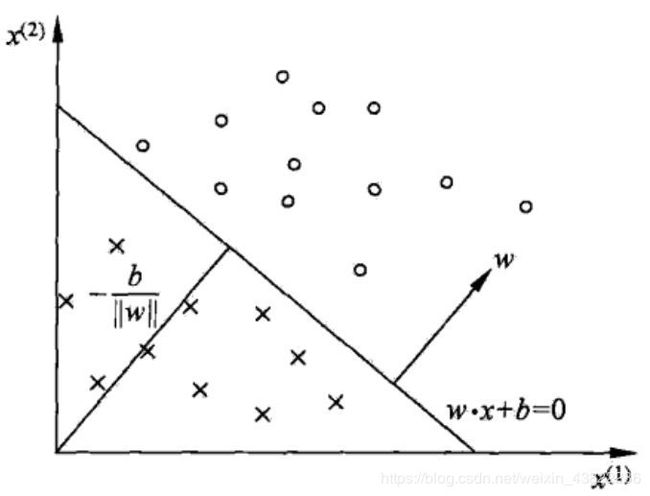
感知机学习策略
对于训练数据集 T = { ( x 1 , y 1 ) ( x 2 , y 2 ) . . . ( x N , y N ) } T=\begin{Bmatrix} (x_{1},y_{1}) & (x_{2},y_{2}) &...& (x_{N},y_{N}) \end{Bmatrix} T={(x1,y1)(x2,y2)...(xN,yN)},其中 x ∈ X ⊆ R n x\in X\subseteq \mathbb{R}^{n} x∈X⊆Rn, y i = { + 1 , − 1 } y_{i}=\begin{Bmatrix} +1,-1\end{Bmatrix} yi={+1,−1}中的实例点 ( x i , y i ) (x_{i},y_{i}) (xi,yi), R n \mathbb{R}^{n} Rn中的某一超平面 S : ω ⋅ x i + b = 0 S:\omega \cdot x_{i}+b=0 S:ω⋅xi+b=0可能会被正确分类,也可能会被错误分类。当被错误分类时,有 − y i ( ω ⋅ x i + b ) > 0 -y_{i}(\omega \cdot x_{i}+b)>0 −yi(ω⋅xi+b)>0(判断和实际的符号不一致,相乘结果小于0,加上负号后大于0)
设 M ⊆ T M\subseteq \ T M⊆ T时 S S S关于所有误分类点的集合,且令
L ( ω , b ) = − ∑ ( x i , y i ) ∈ M y i ( ω ⋅ x i + b ) L(\omega ,b)=-\sum_{(x_{i},y_{i})\in M}y_{i}(\omega \cdot x_{i}+b) L(ω,b)=−(xi,yi)∈M∑yi(ω⋅xi+b)
L ( ω , b ) L(\omega ,b) L(ω,b)常被称为感知机的损失函数,其值显然是非负的。如果没有误分类点,损失函数等于0,误分类点越少,损失函数值越小。所以感知机的学习策略就是选取参数 : ω :\omega :ω和 b b b使 L ( ω , b ) L(\omega ,b) L(ω,b)达到最小值。
感知机学习算法
对于给定的训练集 T T T,感知机的学习损失函数 L ( ω , b ) L(\omega ,b) L(ω,b)是 : ω :\omega :ω和 b b b的连续可导函数。确定最优的 : ω :\omega :ω和 b b b的问题转化为求解损失函数 L ( ω , b ) L(\omega ,b) L(ω,b)的最优问题,而最优化问题采用随机梯度下降法。
1.感知机学习算法的原始形式
给定一个数据集: T = { ( x 1 , y 1 ) ( x 2 , y 2 ) . . . ( x N , y N ) } T=\begin{Bmatrix} (x_{1},y_{1}) & (x_{2},y_{2}) &...& (x_{N},y_{N}) \end{Bmatrix} T={(x1,y1)(x2,y2)...(xN,yN)}, x ∈ X ⊆ R n x\in X\subseteq \mathbb{R}^{n} x∈X⊆Rn, y i = { + 1 , − 1 } y_{i}=\begin{Bmatrix} +1,-1\end{Bmatrix} yi={+1,−1},求参数 ω \omega ω和 b b b,使其为一下损失函数极小化问题的解 min ω , b L ( ω , b ) = − ∑ ( x i , y i ) ∈ M y i ( ω ⋅ x i + b ) \underset{\omega ,b }{\min}L(\omega ,b)=-\sum_{(x_{i},y_{i})\in M}y_{i}(\omega \cdot x_{i}+b) ω,bminL(ω,b)=−(xi,yi)∈M∑yi(ω⋅xi+b)其中 M ⊆ T M\subseteq \ T M⊆ T时 S S S关于所有误分类点的集合。
感知机的学习算法是误分类驱动的,采用随机梯度下降法,首先任意选取一个超平面 ω \omega ω和 b b b,然后用梯度下降法不断极小化损失函数,极小化的过程不是一次使 M M M中的所有误分类点的梯度下降,而是一次选取一个误分点使其梯度下降。
设误分点的集合 M M M是固定的,那么损失函数 L ( ω , b ) L(\omega ,b) L(ω,b)的梯度为: ▽ ω L ( ω , b ) = − ∑ ( x i , y i ) ∈ M y i x i \bigtriangledown _{\omega }L(\omega ,b)=-\sum_{(x_{i},y_{i})\in M}y_{i}x_{i} ▽ωL(ω,b)=−(xi,yi)∈M∑yixi ▽ ω L ( ω , b ) = − ∑ ( x i , y i ) ∈ M y i \bigtriangledown _{\omega }L(\omega ,b)=-\sum_{(x_{i},y_{i})\in M}y_{i} ▽ωL(ω,b)=−(xi,yi)∈M∑yi,随机选取一个误分点 ( x i , y i ) ∈ M (x_{i},y_{i})\in M (xi,yi)∈M,对 ω \omega ω和 b b b进行更新。 ω ← ω + η y i x i \omega \leftarrow \omega +\eta y_{i}\mathbf{x_{i}} ω←ω+ηyixi b ← b + η y i b\leftarrow b +\eta y_{i} b←b+ηyi参数更新表达式中的 η \eta η是步长或学习率。
例:
| 零件编号 | 宽度(wid) z 1 z1 z1 | 长度(len) z 2 z2 z2 | 检验类别 |
|---|---|---|---|
| 1 | 3 | 3 | 正品 |
| 2 | 4 | 3 | 正品 |
| 3 | 1 | 1 | 次品 |
令 x 1 = ( 3 , 3 ) , y 1 = 1 ; x 2 = ( 4 , 3 ) , y 2 = 1 ; x 2 = ( 1 , 1 ) , y 3 = − 1 x_{1}=(3,3),y_{1}=1;x_{2}=(4,3),y_{2}=1;x_{2}=(1,1),y_{3}=-1 x1=(3,3),y1=1;x2=(4,3),y2=1;x2=(1,1),y3=−1,则有 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) } ; T=\begin{Bmatrix} (x_{1},y_{1}) & ,(x_{2},y_{2}) & ,(x_{3},y_{3}) \end{Bmatrix}; T={(x1,y1),(x2,y2),(x3,y3)};,其中 ( x 1 , y 1 ) (x_{1},y_{1}) (x1,y1)和 ( x 2 , y 2 ) (x_{2},y_{2}) (x2,y2)为正实例点, ( x 3 , y 3 ) (x_{3},y_{3}) (x3,y3)为负实例点。
(1)设置初始值 ω 0 = ( 0 , 0 ) , b 0 = 0 , η = 1 \omega _{0}=(0,0),b_{0}=0,\eta =1 ω0=(0,0),b0=0,η=1
(2)对 x 1 = ( 3 , 3 ) , y 1 ( ω ⋅ x 1 + b ) = 0 x_{1}=(3,3),y_{1}(\omega \cdot x_{1}+b)=0 x1=(3,3),y1(ω⋅x1+b)=0未能被正确分类,更新参数模型: ω 1 = ω 0 + y 1 x 1 = ( 3 , 3 ) , b 1 = b 0 + y 1 = 1 \omega _{1}=\omega _{0}+y_{1}x_{1}=(3,3),b_{1}=b_{0}+y_{1}=1 ω1=ω0+y1x1=(3,3),b1=b0+y1=1(3) x 1 , x 2 x_{1},x_{2} x1,x2被正确分类,而 x 3 = ( 1 , 1 ) , y 1 ( ω ⋅ x 1 + b ) < 0 x_{3}=(1,1),y_{1}(\omega \cdot x_{1}+b)<0 x3=(1,1),y1(ω⋅x1+b)<0,更新参数模型: o m e g a 2 = ω 1 + y 3 x 3 = ( 2 , 2 ) , b 2 = b 1 + y 3 = 0 omega _{2}=\omega _{1}+y_{3}x_{3}=(2,2),b_{2}=b_{1}+y_{3}=0 omega2=ω1+y3x3=(2,2),b2=b1+y3=0如此继续下去,直到 ω 7 = ( 1 , 1 ) , b 7 = − 3 \omega _{7}=(1,1),b_{7}=-3 ω7=(1,1),b7=−3。整个迭代计算过程见表:
| 迭代次数 | 误分类点 | ω \omega ω | b b b | ω ⋅ x 1 + b \omega \cdot x_{1}+b ω⋅x1+b |
|---|---|---|---|---|
| 0 | (0,0) | 0 | ||
| 0 | x 1 x_{1} x1 | (0,0) | 1 | 3 w i d + 3 l e n + 1 3wid+3len+1 3wid+3len+1 |
| 2 | x 3 x_{3} x3 | (2,2) | 0 | 2 w i d + 2 l e n 2wid+2len 2wid+2len |
| 3 | x 3 x_{3} x3 | (1,1) | -1 | w i d + l e n wid+len wid+len-1 |
| 4 | x 3 x_{3} x3 | (0,0) | -2 | − 2 -2 −2 |
| 5 | x 1 x_{1} x1 | (3,3) | -1 | 3 w i d + 3 l e n − 1 3wid+3len-1 3wid+3len−1 |
| 6 | x 3 x_{3} x3 | (2,2) | -2 | 2 w i d + 2 l e n − 2 2wid+2len-2 2wid+2len−2 |
| 7 | x 3 x_{3} x3 | (1,1) | -3 | w i d + l e n − 3 wid+len-3 wid+len−3 |
| 8 | (1,1) | -3 | w i d + l e n − 3 wid+len-3 wid+len−3 |
在整个感知机的迭代算法中,若某个迭代过程有多个误分类点,那么选择不同的误分点,会得到不同的分离超平面。基于不同的初始值,也会的到不同的解。
例题R语言代码如下:
perception<-function(x,class,eta=1)
#x为样本的特征矩阵,class为样本的分类标签,eta为学习步长
{
ma<-as.matrix(x)
N<-nrow(x) #计算样本容量
w<-rep(0,times=ncol(x))
b<-0 #初始化w,b
while(TRUE)
{
k<-0
for(i in 1:N)
{
if(y[i]*(ma[i,]%*%w+b)<=0)
{
w<-w+eta*y[i]*ma[i,]
b<-b+eta*y[i]
k<-k+1
}
}
if(k==0) break
}
return(list(w=w,b=b))
}
x<-data.frame(x1=c(3,4,1),x2=c(3,3,1))
y<-c(1,1,-1)
model<-perception(x,y)
print(model)
2.感知机学习算法的对偶形式
在例题中的感知机迭代过程中,设置初始值 ω 0 = ( 0 , 0 ) , b 0 = 0 , η = 1 \omega _{0}=(0,0),b_{0}=0,\eta =1 ω0=(0,0),b0=0,η=1
第一次迭代,由于对 x 1 = ( 3 , 3 ) x_{1}=(3,3) x1=(3,3)为误分点,更新参数模型: ω 1 = ω 0 + y 1 x 1 = ( 3 , 3 ) , b 1 = b 0 + η ⋅ y 1 = 1 \omega _{1}=\omega _{0}+y_{1}x_{1}=(3,3),b_{1}=b_{0}+\eta \cdot y_{1}=1 ω1=ω0+y1x1=(3,3),b1=b0+η⋅y1=1第二次迭代,由于对 x 3 = ( 1 , 1 ) x_{3}=(1,1) x3=(1,1)是误分点,更新参数模型: ω 2 = ω 1 + η ⋅ y 3 x 3 = η ⋅ y 1 x 1 + η ⋅ y 3 x 3 = ( 2 , 2 ) \omega _{2}=\omega _{1}+\eta \cdot y_{3}x_{3}=\eta \cdot y_{1}x_{1}+\eta \cdot y_{3}x_{3}=(2,2) ω2=ω1+η⋅y3x3=η⋅y1x1+η⋅y3x3=(2,2) b 2 = b 1 + η ⋅ y 3 = η ⋅ y 1 + η ⋅ y 3 = 0 b_{2}=b_{1}+\eta \cdot y_{3}=\eta \cdot y_{1}+\eta \cdot y_{3}=0 b2=b1+η⋅y3=η⋅y1+η⋅y3=0第三次迭代由于对 x 3 = ( 1 , 1 ) x_{3}=(1,1) x3=(1,1)是误分点,更新参数模型: ω 3 = ω 2 + η ⋅ y 3 x 3 = η ⋅ y 1 x 1 + 2 η ⋅ y 3 x 3 = ( 1 , 1 ) \omega _{3}=\omega _{2}+\eta \cdot y_{3}x_{3}=\eta \cdot y_{1}x_{1}+2\eta \cdot y_{3}x_{3}=(1,1) ω3=ω2+η⋅y3x3=η⋅y1x1+2η⋅y3x3=(1,1) b 3 = b 2 + η ⋅ y 3 = η ⋅ y 1 + 2 η ⋅ y 3 = − 1 b_{3}=b_{2}+\eta \cdot y_{3}=\eta \cdot y_{1}+2\eta \cdot y_{3}=-1 b3=b2+η⋅y3=η⋅y1+2η⋅y3=−1第四次迭代由于对 x 3 = ( 1 , 1 ) x_{3}=(1,1) x3=(1,1)是误分点,更新参数模型: ω 4 = ω 3 + η ⋅ y 3 x 3 = η ⋅ y 1 x 1 + 3 η ⋅ y 3 x 3 = ( 0 , 0 ) \omega _{4}=\omega _{3}+\eta \cdot y_{3}x_{3}=\eta \cdot y_{1}x_{1}+3\eta \cdot y_{3}x_{3}=(0,0) ω4=ω3+η⋅y3x3=η⋅y1x1+3η⋅y3x3=(0,0) b 4 = b 3 + η ⋅ y 3 = η ⋅ y 1 + 3 η ⋅ y 3 = − 2 b_{4}=b_{3}+\eta \cdot y_{3}=\eta \cdot y_{1}+3\eta \cdot y_{3}=-2 b4=b3+η⋅y3=η⋅y1+3η⋅y3=−2第五次迭代由于对 x 1 = ( 3 , 3 ) x_{1}=(3,3) x1=(3,3)是误分点,更新参数模型: ω 5 = ω 4 + η ⋅ y 3 x 3 = 2 η ⋅ y 1 x 1 + 3 η ⋅ y 3 x 3 = ( 3 , 3 ) \omega _{5}=\omega _{4}+\eta \cdot y_{3}x_{3}=2\eta \cdot y_{1}x_{1}+3\eta \cdot y_{3}x_{3}=(3,3) ω5=ω4+η⋅y3x3=2η⋅y1x1+3η⋅y3x3=(3,3) b 5 = b 4 + η ⋅ y 1 = 2 η ⋅ y 1 + 3 η ⋅ y 3 = − 1 b_{5}=b_{4}+\eta \cdot y_{1}=2\eta \cdot y_{1}+3\eta \cdot y_{3}=-1 b5=b4+η⋅y1=2η⋅y1+3η⋅y3=−1第六次迭代由于对 x 3 = ( 1 , 1 ) x_{3}=(1,1) x3=(1,1)是误分点,更新参数模型: ω 6 = ω 5 + η ⋅ y 3 x 3 = 2 η ⋅ y 1 x 1 + 4 η ⋅ y 3 x 3 = ( 2 , 2 ) \omega _{6}=\omega _{5}+\eta \cdot y_{3}x_{3}=2\eta \cdot y_{1}x_{1}+4\eta \cdot y_{3}x_{3}=(2,2) ω6=ω5+η⋅y3x3=2η⋅y1x1+4η⋅y3x3=(2,2) b 6 = b 5 + η ⋅ y 3 = 2 η ⋅ y 1 + 4 η ⋅ y 3 = − 2 b_{6}=b_{5}+\eta \cdot y_{3}=2\eta \cdot y_{1}+4\eta \cdot y_{3}=-2 b6=b5+η⋅y3=2η⋅y1+4η⋅y3=−2第七次迭代由于对 x 3 = ( 1 , 1 ) x_{3}=(1,1) x3=(1,1)是误分点,更新参数模型: ω 7 = ω 6 + η ⋅ y 3 x 3 = 2 η ⋅ y 1 x 1 + 5 η ⋅ y 3 x 3 = ( 1 , 1 ) \omega _{7}=\omega _{6}+\eta \cdot y_{3}x_{3}=2\eta \cdot y_{1}x_{1}+5\eta \cdot y_{3}x_{3}=(1,1) ω7=ω6+η⋅y3x3=2η⋅y1x1+5η⋅y3x3=(1,1) b 7 = b 6 + η ⋅ y 3 = 2 η ⋅ y 1 + 5 η ⋅ y 3 = − 3 b_{7}=b_{6}+\eta \cdot y_{3}=2\eta \cdot y_{1}+5\eta \cdot y_{3}=-3 b7=b6+η⋅y3=2η⋅y1+5η⋅y3=−3从这个过程中可以发现,当初始值 ω 0 = ( 0 , 0 ) , b 0 = 0 \omega _{0}=(0,0),b_{0}=0 ω0=(0,0),b0=0时,感知机模型的参数可以表示为数据集中实例点的线性合: ω = 2 η ⋅ y 1 x 1 + 0 η ⋅ y 2 x 2 + 5 η ⋅ y 3 x 3 \omega =2\eta \cdot y_{1}x_{1}+0\eta \cdot y_{2}x_{2}+5\eta \cdot y_{3}x_{3} ω=2η⋅y1x1+0η⋅y2x2+5η⋅y3x3 b = 2 η ⋅ y 1 + 0 η ⋅ y 2 + 5 η ⋅ y 3 b=2\eta \cdot y_{1}+0\eta \cdot y_{2}+5\eta \cdot y_{3} b=2η⋅y1+0η⋅y2+5η⋅y3令 α 1 = 2 η 1 , α 2 = 0 η 2 , α 3 = 5 η 3 \alpha_{1}=2\eta _{1},\alpha _{2}=0\eta _{2},\alpha _{3}=5\eta _{3} α1=2η1,α2=0η2,α3=5η3,则有 ω = α 1 y 1 x 1 + α 2 y 2 x 2 + α 3 y 3 x 3 = ∑ 3 j = 1 α j y j x j \omega =\alpha_{1}y_{1}x_{1}+\alpha _{2}y_{2}x_{2}+\alpha _{3}y_{3}x_{3}=\sum_{3}^{j=1}\alpha_{j}y_{j}x_{j} ω=α1y1x1+α2y2x2+α3y3x3=3∑j=1αjyjxj b = α 1 y 1 + α 2 y 2 + α 3 y 3 = ∑ 3 j = 1 α j y j b=\alpha_{1}y_{1}+\alpha _{2}y_{2}+\alpha _{3}y_{3}=\sum_{3}^{j=1}\alpha_{j}y_{j} b=α1y1+α2y2+α3y3=3∑j=1αjyj α j = n j η \alpha_{j}=n_{j}\eta αj=njη为 x j x_{j} xj被误分的次数, n j n_{j} nj越大表示实例点 ( x j , y j ) (x_{j},y_{j}) (xj,yj)离分离超平面越近,就越难被分类。将 ω = ∑ 3 j = 1 α j y j x j \omega =\sum_{3}^{j=1}\alpha_{j}y_{j}x_{j} ω=∑3j=1αjyjxj带入感知机的原始形式就得到感知机的对偶形式,在该形式下,分离超平面为 ∑ 3 j = 1 α j y j x j ⋅ x + b = 0 \sum_{3}^{j=1}\alpha_{j}y_{j}x_{j}\cdot\mathbf{x} +b=0 3∑j=1αjyjxj⋅x+b=0而感知机模型为 f ( x ) = s i g n ( ∑ 3 j = 1 α j y j x j ⋅ x + b ) f(x)=sign(\sum_{3}^{j=1}\alpha_{j}y_{j}x_{j}\cdot\mathbf{x} +b) f(x)=sign(3∑j=1αjyjxj⋅x+b)这种算法旨在求解 α = ( α 1 , α 2 , . . . , α n ) \mathbf{\alpha }=(\alpha _{1},\alpha _{2},...,\alpha _{n}) α=(α1,α2,...,αn)和 b b b。
对偶形式的感知机R语言代码:
perception_pair<-function(x,class,eta=1)
#x为样本的特征矩阵,class为样本的分类标签,eta为学习步长
{
ma<-as.matrix(x)
N<-nrow(x) #计算样本容量
a<-rep(0,times=N)
w<-vector(length = ncol(x));b<-0 #初始化w,b
gram<-ma%*%t(ma)
while(TRUE)
{
k<-0
for(i in 1:N)
{
if(y[i]*(sum(a*y*gram[,i])+b)<=0)
{
a[i]<-a[i]+eta
b<-b+eta*y[i]
k<-k+1
}
}
if(k==0) break
}
for (i in 1:N) {
w<-w+a[i]*y[i]*ma[i,]
}
return(list(a=a,w=w,b=b))
}
model_pair<-perception_pair(x,y)
model<-perception(x,y)
print(model)