selenium第一篇!文末带有解决验证码问题的小代码哦!测试入门selenium!并解决几个常见的问题,如带空格的属性,和click后定位不在页面。并实战模拟登陆人人网
selenium的内容好多,用来做自动化测试很管用,所以我打算一点一点来写!今天先是一些简单的操作。
对于selenium,能控制浏览器进行自动操作的方法,我之前其实用的PhantomJS,因为它不会要求在屏幕上打开浏览器,但是这次选用的是chrome来测试,便于观察效果,chrome需要下载对应版本的驱动chromedriver,下载链接:
http://chromedriver.storage.googleapis.com/index.html
chrome的版本打开设置选择高级可以看到,下载完成后把exe放入python的script文件夹下就好,直接就可以用了。
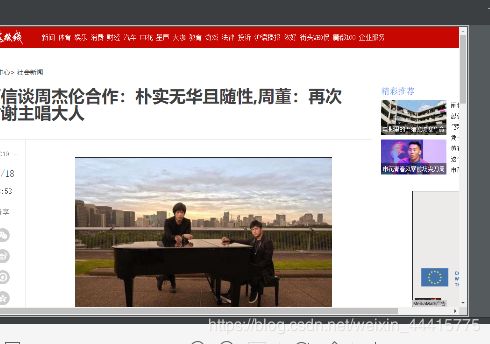
测试例子是我上课在百度网页上点进去的一个关于周杰伦新歌的页面,说到周杰伦,我
一定要去看他的演唱会!
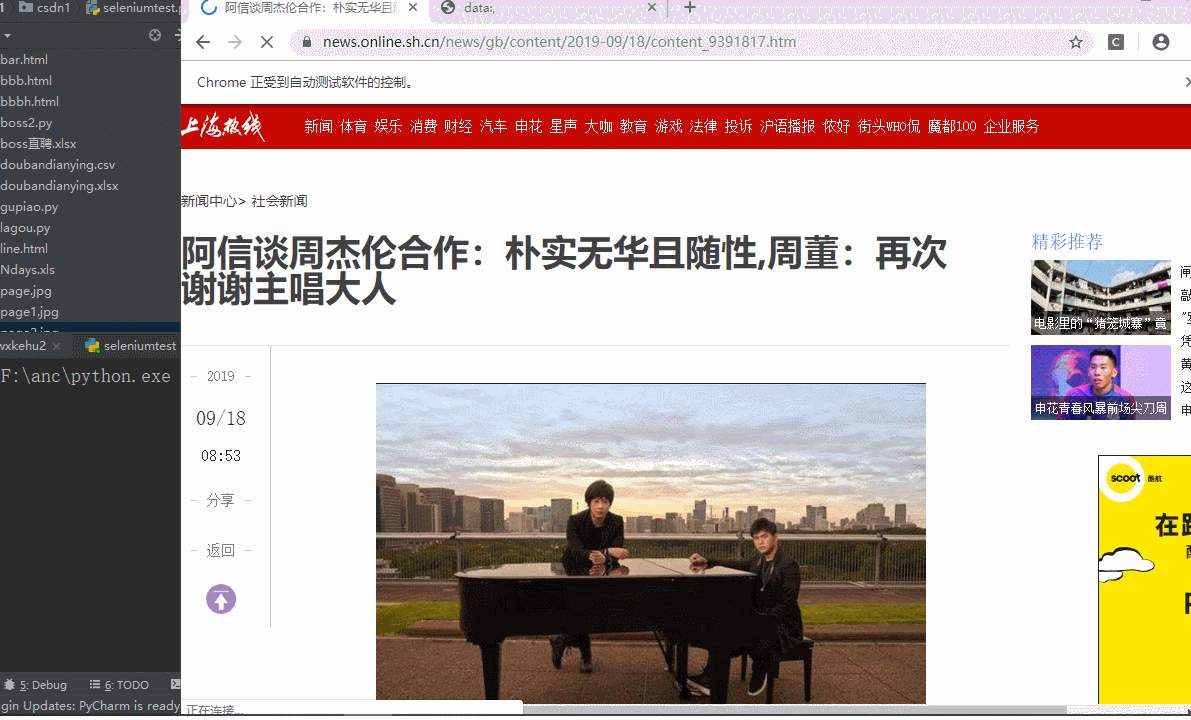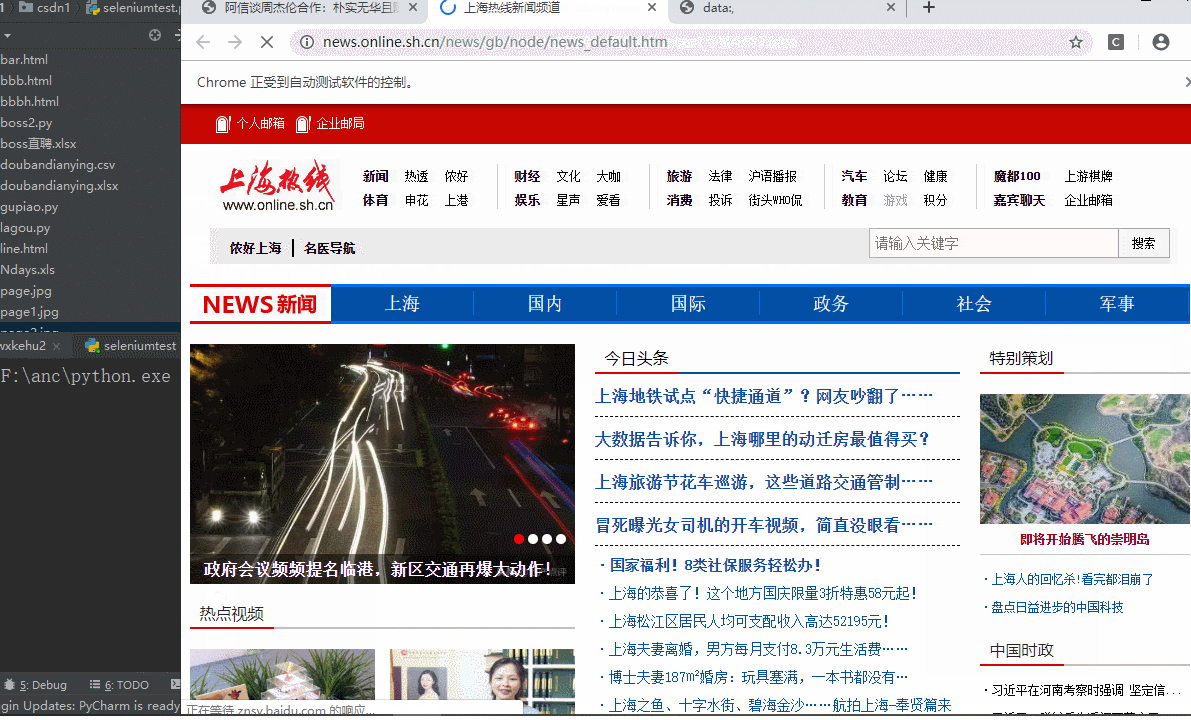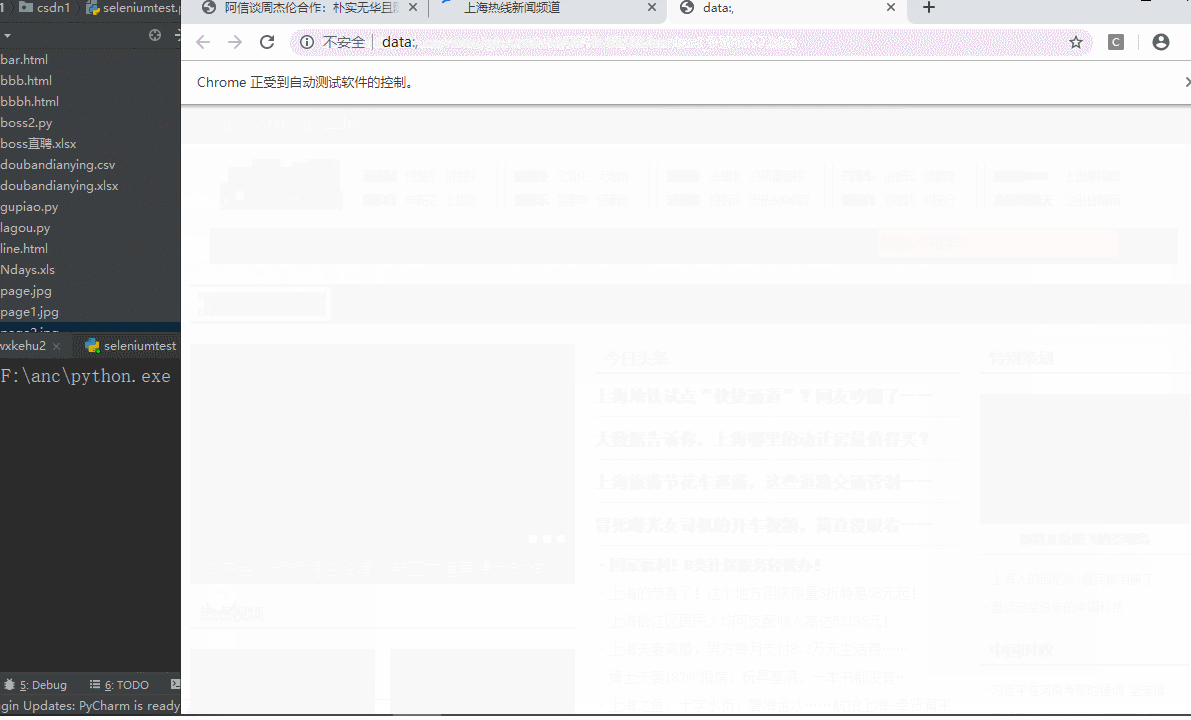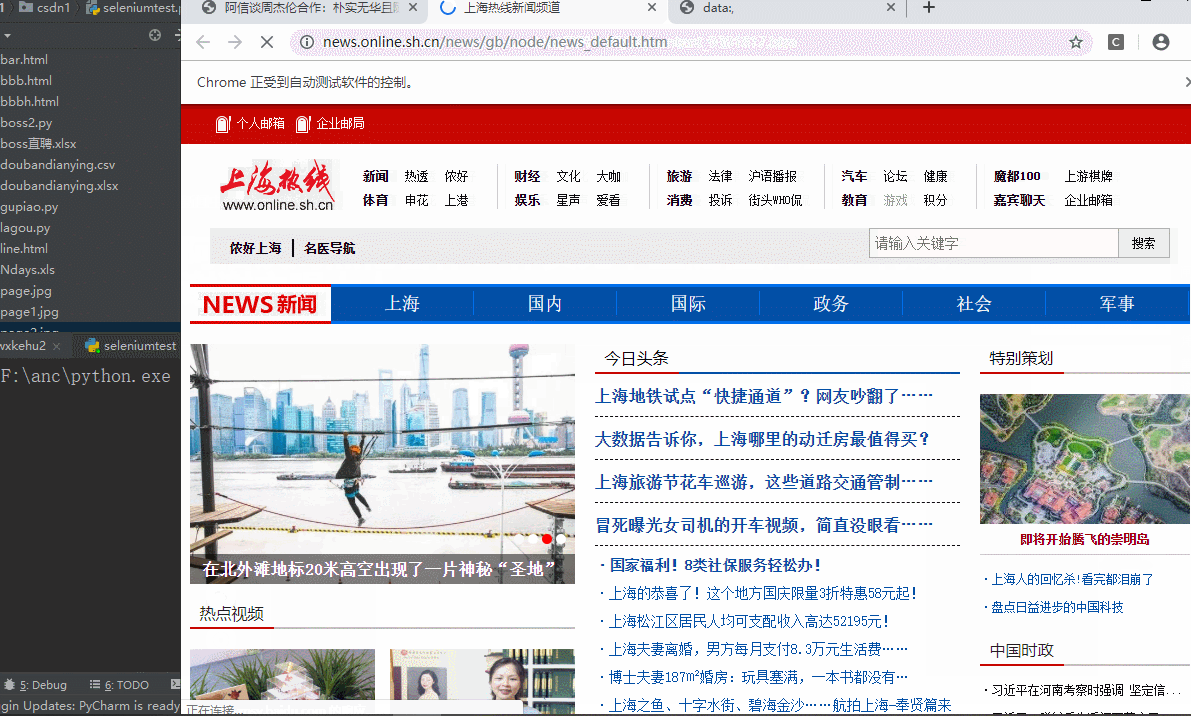
下面看运行打开页面的测试图
代码如下url = 'https://news.online.sh.cn/news/gb/content/2019-09/18/content_9391817.htm' browser = webdriver.Chrome()#打开浏览器 browser.get(url=url)#打开需要的页面
我们再来试下给当前的页面拍个照片
page = browser.save_screenshot('page.jpg')
另外selenium也可用做爬虫获取当前页面需要的元素,他支持很多种选取方式,xpath,css等而且可以混用,这里我主要使用两种,先来试试手,提取页面的标题。
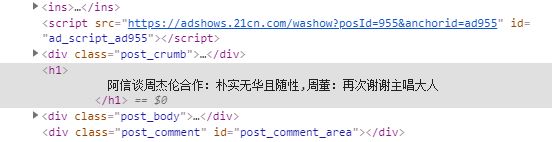
title = browser.find_element_by_class_name('post_content_main').find_element_by_tag_name('h1').text
#这是获取了文章的标题
![]()
接下来让我们用该方法进入页面中的新闻中心子页面,这次进入会碰到一个小问题,我没有使用browser.get(url)的方法进入,选择了click的方法进入,click点击链接会有一个小问题,就是我们的browser还会定位在之前的页面,就无法在当前的页面选取
link = browser.find_element_by_class_name('post_content_main').find_elements_by_tag_name('a')[0]
link.click()
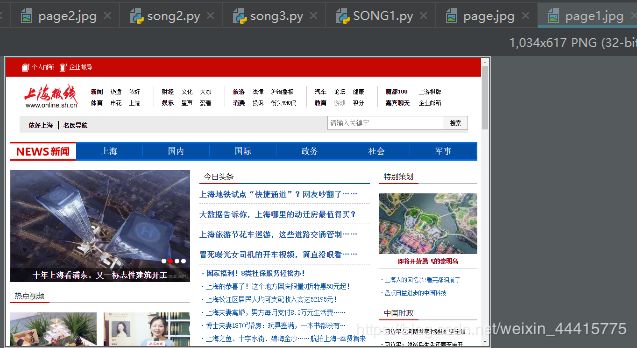
上面的代码理论上来说已经获取了该链接并成功点击了,但事实上并没有进去我们需要的界面。这个点我们可以照着之前拍照第一个页面的样子再拍一次,结果会发现,click以后还是在同一个页面
但这样就出现了问题,我们要的材料在下一个页面中但并没有进去,接下来说下解决的方法
current_window = browser.current_window_handle # 这个代码写在第一部分的页面中获取第一个页面的窗口
all_window=browser.window_handles
for window in all_window:
if window != current_window:
browser.switch_to.window(window)#这段代码写在click之后,表示将当前窗口换为新的窗口
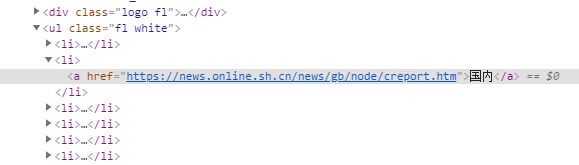
问题就解决啦!如图
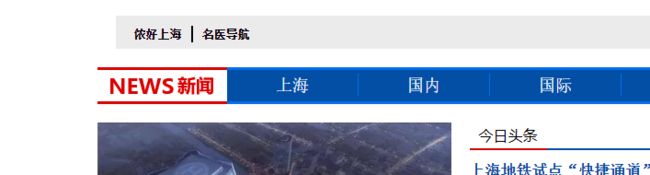
然后说下在这个页面中选取元素过程出现的问题,在遇到有空格属性名的元素时,写全称爬取就会报错,比如这样的

说一下解决的办法,其实有好多种,可以用输入css选择输入全名的方法,可以用css获取类名的方法,在每个属性前加个点,可以只选取一个属性,如果页面中有多个此属性则加上下标选取(不推荐,因为要是相同的太多会很难数),下面列举
link2 = browser.find_element_by_css_selector("[class='fl white']").find_elements_by_tag_name('li')[1].find_element_by_css_selector('a').get_attribute('href')
link1 = browser.find_element_by_css_selector(".fl.white")
link4 = browser.find_elements_by_class_name('fl')[1]
以上是获取从该页面点击新闻中心之后,再选择国内新闻的代码。他们的输出结果都是一样的
接下来做一下该页面搜索框的模拟搜索操作
time.sleep(2)
browser.refresh()#这是刷新页面,网页有点奇怪,有时候不出现输入框,我就试着刷新了一下
browser.find_element_by_css_selector('.bdcs-search-form-input').send_keys('蔡徐坤')
browser.find_element_by_css_selector("[class='bdcs-search-form-submit ']").click()
我们模拟输入了蔡徐坤,并点击了一下搜索按钮,会出现什么结果呢
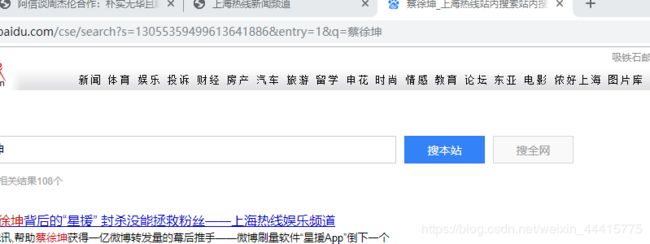
测试成功!
最后实战一下下,模拟登陆一下人人网!
网址http://www.renren.com/SysHome.do
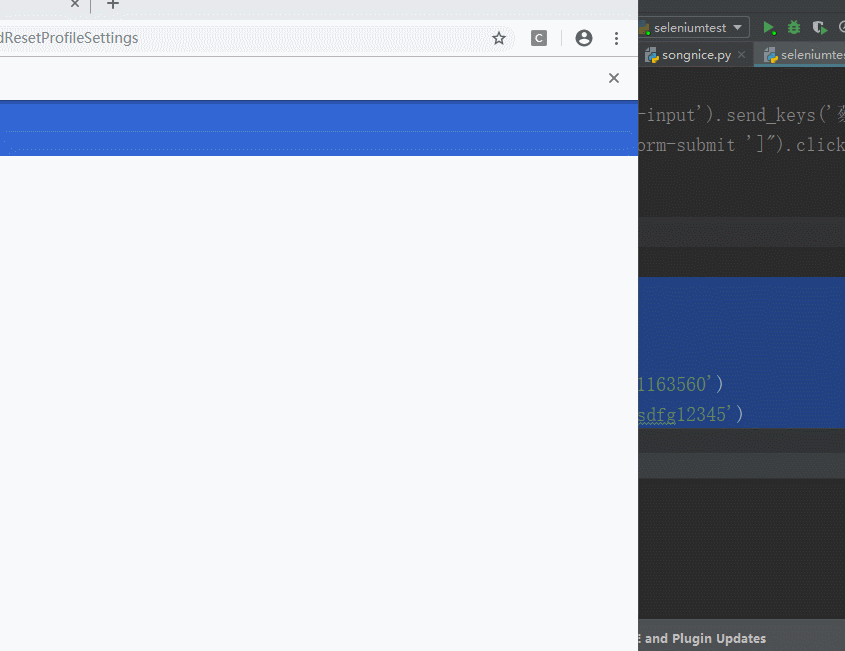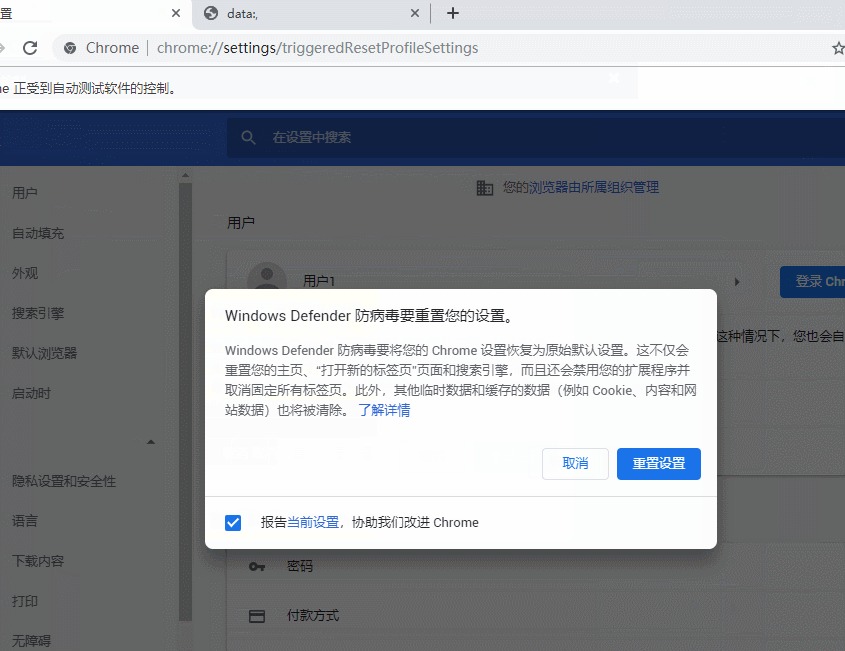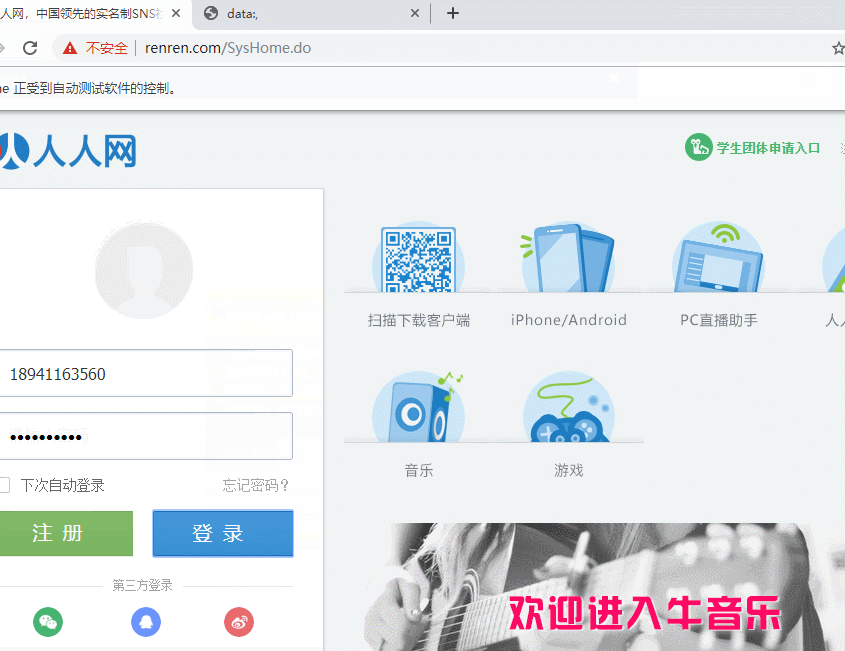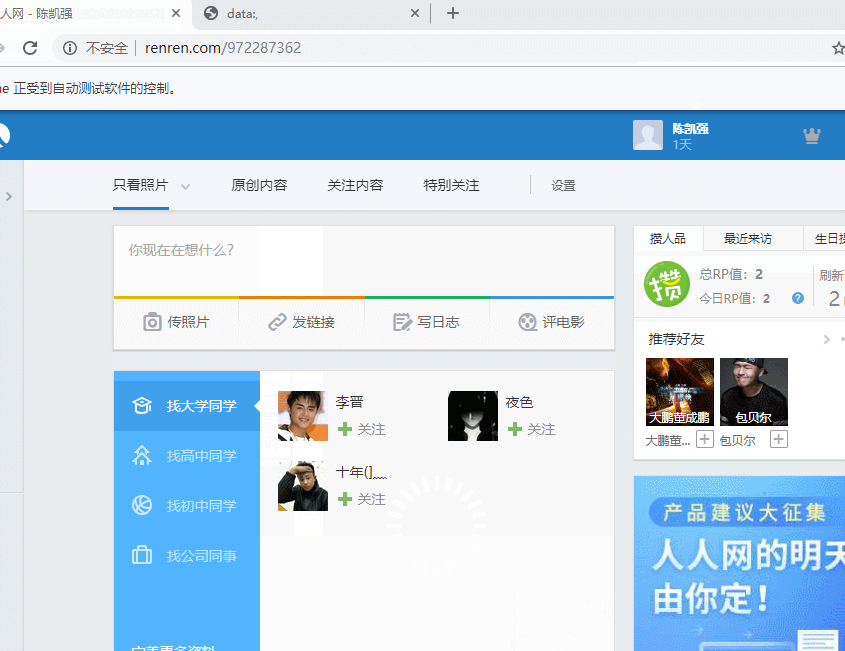
页面信息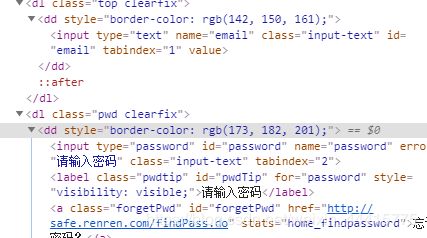
url = 'http://www.renren.com/SysHome.do'
driver = webdriver.Chrome()
driver.get(url=url)
driver.find_element_by_css_selector('#email').send_keys('xxx')#你的账号
driver.find_element_by_css_selector('#password').send_keys('xxx')#你的密码
driver.find_element_by_css_selector('#login').click()
driver.save_screenshot('page66.jpg')
最后发个小东西,对模拟登陆感觉挺有帮助,验证码的识别功能

这是保存的用来测试的验证码
然后是效果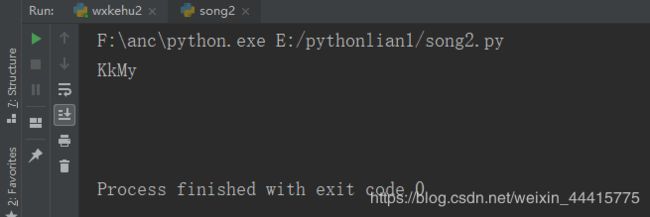
是不是很强大,给代码import tesserocr from PIL import Image image = Image.open('captcha.jpg') image = image.convert('L') result = tesserocr.image_to_text(image) print(result)
有些验证码识别不出需要重新设置阈值或者其他操作,很简单就能识别出来。