Kafka实践五:KafkaProducer和KafkaConsumer的API使用
参考官网文档:添加链接描述
参考博客:添加链接描述
参考:添加链接描述
参考:添加链接描述
一、KafkaProducer的原理和使用
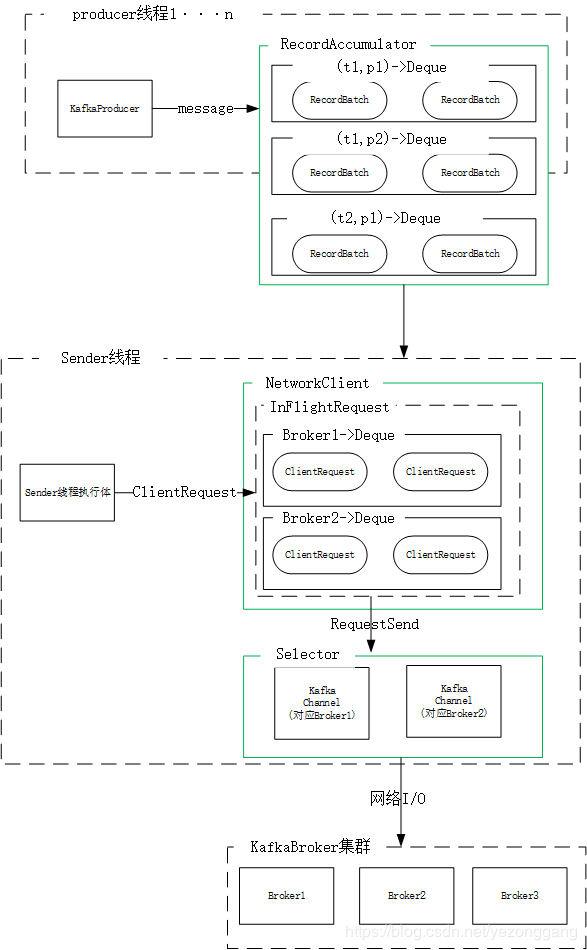
发送过程
Kafka API中使用KafkaProducer类发送数据,kafka Producer是线程安全的,可以在多个线程之间共享生产者实例,其发送模型如下:
二、分析
从一段基础的发送代码分析起,首先maven配置的pom.xml主要引入kafka-clients包:
1.0.0
org.apache.kafka
kafka-clients
${kafka.version}
org.apache.kafka
kafka-streams
${kafka.version}
kafka的配置信息写入KafkaProducer.properties:
bootstrap.servers = localhost:9092
acks = 0
retries = 0
batch.size 16384
linger.ms = 1
buffer.memory = 33554432
key.serializer = org.apache.kafka.common.serialization.StringSerializer
value.serializer = org.apache.kafka.common.serialization.StringSerializer
生产者读取配置文件并发送数据:
package cmos;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.*;
import java.io.FileInputStream;
import java.util.*;
public class KafkaProducerTest {
public static void main(String[] args) throws IOException {
/*
或使用读取配置方法:
Properties props = new Properties();
String path = KafkaProducer.class.getClassLoader().getResource("kafkaProducer.properties").getPath();
props.load(new FileInputStream(path));
System.out.println(props.getProperty("acks"));
*/
/* 或直接配置props
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
*/
//读取配置文件
Properties props = new Properties();
InputStream in = KafkaProducerTest.class.getClassLoader().getResourceAsStream("kafkaProducer.properties");
props.load(in);
System.out.println("the acks is : "+props.getProperty("acks"));
//发送数据
Producer producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
}
}
生产者的缓冲池保留尚未发送到服务器的消息,后台I/O线程负责将这些消息转换成请求发送到kafka集群。如果使用后不关闭生产者,则会导致资源泄露。
**acks:**是判断消息是否成功发送的条件,将acks指定为"all"将会阻塞消息,当所有的副本都返回后才表明该消息发送成功,这种设置性能最低,但是是最可靠的。
**retries:**表示重试的次数,如果请求失败,生产者会自动重试。如果启用重试,则会有重复消息的可能性。
**batch.size:**指定了缓冲区的大小,kafka的producer会缓存每个分区未发送消息。
**linger.ms:**指示生产者发送请求前等待一段时间,等待更多的消息来填满缓冲区。默认缓冲可立即发送,即使缓冲空间还没有满。但是,如果想减少请求的数量,可以设置linger.time大于0。如果我们没有填满缓冲区,这个设置将增加1毫秒的延迟请求以等待更多的消息。需要注意的是,在高负载下,相近的时间一般也会组成批,即使linger.time=0。在不处于高负载的情况下,如果设置比0大,以少量的延迟代价换取更少的,更有效的请求。
buffer.memory:控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽这个缓存空间。当缓存空间耗尽,其他发送调用将被阻塞,阻塞时间的阈值通过max.block.ms设定,之后它将抛出一个TimeoutException。
kafka的producer的send()方法提供多种重载,send()是异步的,一旦消息被保存在等待发送的消息缓存中,此方法就立即返回,这样可以你并行发送多条消息而不阻塞去等待每一条消息的响应。发送的结果是一个RecordMetadata,它指定了消息发送的分区,分配的offset和消息的时间戳。如果topic使用的是CreateTime,则使用用户提供的时间戳或发送的时间,如果topic使用的是LogAppendTime,时间戳是broker的本地时间。由于send调用是异步的,它将为分配消息的此消息的RecordMetadata返回一个Future。如果future调用get(),则将阻塞,直到相关请求完成并返回该消息的metadata,或抛出发送异常,如果要模拟一个简单的阻塞调用,你可以调用get()方法。
send()可以使用callback()返回消息的发送的元数据,callback()定义如下:
package cmos;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.RecordMetadata;
public class CallBackTest implements Callback {
public void onCompletion(RecordMetadata recordMetadata, Exception exception){
if (exception != null){
exception.printStackTrace();
}
else {
long offset = recordMetadata.offset();
int partition = recordMetadata.partition();
String topic = recordMetadata.topic();
System.out.println("the message offset : "+offset+" ,partition:"+partition);
}
}
}
在producer程序中send()得到callback()返回的元数据信息:
//读取配置文件
Properties props = new Properties();
InputStream in = KafkaProducerTest.class.getClassLoader().getResourceAsStream("kafkaProducer.properties");
props.load(in);
System.out.println("the acks is : "+props.getProperty("acks"));
//发送数据
Producer producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
try{
producer.send(new ProducerRecord("my-topic", Integer.toString(i), Integer.toString(i)),new CallBackTest());
}catch (Exception e){
e.printStackTrace();
}
producer.close();
二、KafkaConsumer的原理和使用
kafkaConsumer类不是线程安全的,了解其消费过程之前需要了解偏移量、消费组、消费线程之间的关系;
**偏移量:**Kafka为分区中的每个记录保留一个数值偏移量offset,这个偏移量是该分区中数据的唯一标识符,并且可以表示消费线程在该分区中的的位置;可以选择通过调用commitSync手动控制提交位置(阻塞,直到在提交过程中成功提交了补偿或致命错误),或者使用非阻塞的commitAsync,并将触发OffsetCommitCallback,要么成功要么失败;
**消费组:**Kafka使用消费者组(Consumer Groups)定义一个线程池,来划分消费和处理记录的工作。这些进程可以在同一台机器上运行,或者分布在许多机器上,从而为处理提供额外的可伸缩性和容错。
① 使用自动提交偏移量的方式:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
**① 使用手动提交偏移量的方式:**关闭自动提交
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List> buffer = new ArrayList<>();
while (true) {
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();
buffer.clear();
}
}
③ 多线程消费:
public class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public void run() {
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
ConsumerRecords records = consumer.poll(10000);
// Handle new records
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}