faster-rcnn中,对RPN的理解
原文中rcnn部分的截图

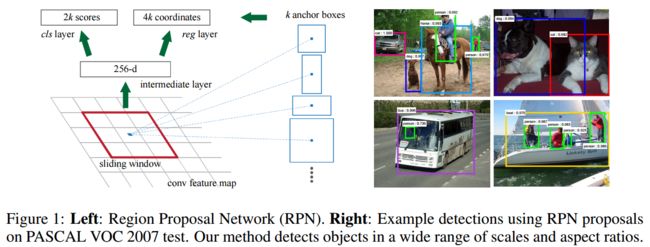
图片来自网上,黑色是滑动窗口的区域,就是上图的红色区域的sliding window其他颜色 9种窗口 就是anchor机制生成的9种区域
这里要把sliding window和卷积层的滑动区别开,sliding winsow的stride步长是1!(想到经典的harr+adaboost人脸检测)
sliding window只是选取所有可能区域,并没有额外的什么作用!
以下是我对faster-rcnn中的RPN的理解:
经过前面的网络 生成了一个 多通道的特征图,接下来就是通过在这些特征图上应用 滑动窗口 加 anchor 机制 进行目标区域判定和分类了,
目标检测,就是包括 目标框定 和 目标判定。
所以 这里的 滑动窗口 + anchor的机制 的功能就 类似于 fast rcnn 的selective search 生成proposals 的作用
rpn网络用来生成proposals
用原文的话讲“we slide a small network over the conv feature map output by the last shared conv layer”
1.RPN是一个 卷积层(256维) + relu + 左右两个层的(clc layer 和 reg layer)的小网络
应用在滑动窗口区域上的 , 所有的滑动窗口共享这个 RPN
这个卷积层 对比 普通的卷积层
1,它是一个将 n x n x channels的输入 通过256个 n x n 大小的卷积核 生成 1 * 1 * 256的feature map,即最后是256维的特征(假设前面得到的特征图是w x h x channels,那么n x n x channels的输入是在这个w x h x channels的特征图上的用滑动窗口框出的区域, 这个滑动窗口就是卷积核, 比如3x3的卷积核, stride=1)
2,它的输入就是滑动窗口nxn对应的特征图区域,经过它卷积后 特征图变成1 x 1了
3,由于此时输出的是 1 * 1 *256,所有cls layer 和reg layer是用 1 x 1的卷积核进行进一步的特征提取,
这里1 x 1卷积核卷积时,对各个通道都有不同的参数,因为输入又是1 x 1的图片,所以相当于全连接的功能,相当于把 1 * 1 * 256展平成 256,然后进行全连接a
2.关于 anchor机制
anchor机制 就是 在n x n的滑动窗口上,进一步生成k种不同大小的可能区域
滑动窗口 加 anchor机制 基本把目标可能出现的区域都涵盖了
所以 滑动窗口 加 anchor 就替代了 滑动窗口加金字塔 的功能a
3.RPN损失计算
RPN提取出的256d特征是被这k种区域共享的,输给clc layer和reg layer后,只要一次前向,就同时预测k个区域的前景、背景概率(1个区域2个scores,所以是2k个scores),以及bounding box(1个区域4个coordinates,所以是4k个coordinates),具体的说:
clc layer输出预测区域的2个参数,即预测为前景的概率pa和pb,损失用softmax loss(cross entropy loss)(本来还以为是sigmoid,这样的话只预测pa就可以了?)。需要的监督信息是Y=0,1,表示这个区域是否ground truth
reg layer输出预测区域的4个参数:x,y,w,h,用smooth L1 loss(用parameterized coordinates, 参看原文)。需要的监督信息是anchor的区域坐标{xa,ya,wa,ha}(这个是根据当前划窗计算的区域映射回原图中得到坐标?) 和 ground truth的区域坐标{x*,y*,w*,h*}
计算损失时,我们需要确定k个区域中的各个区域是不是有效的,是前景还是背景。有效的区域才计算损失。上面的监督信息:Y,{xa,ya,wa,ha}(k个),{x*,y*,w*,h*}(1个)是根据文章中的样本产生规则得到的:
对于这k个区域
1 分配正标签给满足以下规则的区域
1.1 与某个ground truth(GT)的IoU最大的区域
1.2 与任意GT的IoU大于0.7的区域
(使用规则2基本可以找到足够正样本,但对于所有区域与GT的IoU都不大于0.7,可以用规则1)
(一个GT可能分配正标签给多个anchor,具体怎么分配?)
2 分配负标签给与所有GT的IoU都小于0.3的区域。
非正非负的区域不算损失,对训练没有作用
RPN只对有标签的区域计算loss。
最后
参与训练RPN的区域都有参与最后rcnn的训练,只是只有RPN预测为前景的区域 在rcnn才有计算回归损失
在使用faster rcnn的时候(测试阶段),RPN预测为前景的区域才是proposal(对每个位置, RPN依然计算k个anchor boxes的cls和reg, 假如这k个boxes的cls都判定为前景, 那么这k个boxes都会被作为proposals送给后面的ROI Pooling, 只不过后面有做NMS, 肯定会删掉大部分重合的anchor boxes),然后按照softmax score从大到小排序选出前2000个区域,在用NMS进一步筛选出300个区域,然后输给后面的rcnn(包括ROI Pooling, 备注: 经过ROI Pooling后的输出尺寸是固定大小的, 比如7x7)进行预测
(注意此时rcnn的预测类别不包括背景,已经RPN输出的已经默认是前景了. 即RCNN的cls是做目标分类(比如COCO数据集80类), reg是做位置修正)
热点回复:
1. RPN中, 一个位置对应的这k个anchor共享特征. RPN输出之后, 经过筛选存留下来的anchor就根据box位置去前面的原图特征图上crop, 得到各个anchor的特征图(这时候可以把他们统称为proposals), 经过roi pooling后, 这些特征的尺寸维度就都一样了
2. RPN的目标是得到前景的box位置, 作为proposals输出. 后面使用的时候, 根据这个box位置在前面的输入图特征图上进行crop, 然后做roi pooling. rpn和roi pooling的联系只是这个box位置