首发:Meltdown漏洞分析与实践
转自:https://mp.weixin.qq.com/s?__biz=MzI3MTUxOTYyMA==&mid=2247483941&idx=1&sn=e846a19b766b32b05a0acd8c041c0333&chksm=eac1d8ceddb651d82ba5303315f3575dc90438d2802be947e68d91061da02c0c89db5fab25a7&mpshare=1&scene=23&srcid=01072RstgPbrUubVE7OZearz#rd

关于本文
2018年的第二天Meltdown和Spectre漏洞在计算机界如同放了一个核弹,IT码农们都炸开了锅,各大厂商的各路大神都在挑灯夜战的做各种测试和打补丁,各路技术爱好者也纷纷在微信群中热烈讨论漏洞的技术问题和研读论文。
本文是肖光荣和笨叔叔花了一个周末时间,参考了各路的论文和资料撰写出来,希望对喜欢技术的各位朋友能有一丁点的帮助。
本文作者简介:
-
Xiao Guangrong:Linux内核、KVM/QEMU社区核心开发者和维护者。
-
笨叔叔:畅销书《奔跑吧linux内核》作者。
正文
2018年或许注定就是不平凡的一年,这一年刚开始就爆出来两个硬件设计级别的漏洞,其影响之深令人咋舌。漏洞之一是Meltdown,目前发现Intel CPU和ARM Cortex A75受影响。其次是Spectre,其影响了几乎全部主流CPU包括Intel,AMD,ARM (IBM CPU是否受影响还未知)。漏洞爆出之后,几乎所有媒体都在做铺天盖地的报道,科技公司也在公布各自的解决方案和修正日期。然而因为技术背景参差不齐,有些报道没有说到点子上,令人啼笑皆非。
本文的主要资料来源于各论文[3][4]与以及相关的Blog[1][2],其次补充了这些资料中有所忽略或者是互相冲突的地方。因为篇幅原因,在这一篇文章里主要分析了Meltdown。在后续的文章里再来分析Spectre。
1. 背景知识
在深入分析Meltdown之前,我们需要了解一些背景知识。它包括CPU Cache,CPU指令执行,操作系统地址空间隔离的设计。接下来我们依次来看这些知识点。
1.1 CPU Cache
现代处理器执行指令的瓶颈已经不在CPU端,而是在内存访问端。因为CPU的处理速度要远远大于物理内存的访问速度,所以为了减轻CPU等待数据的时间,在现代处理器设计中都设置了多级的cache单元。
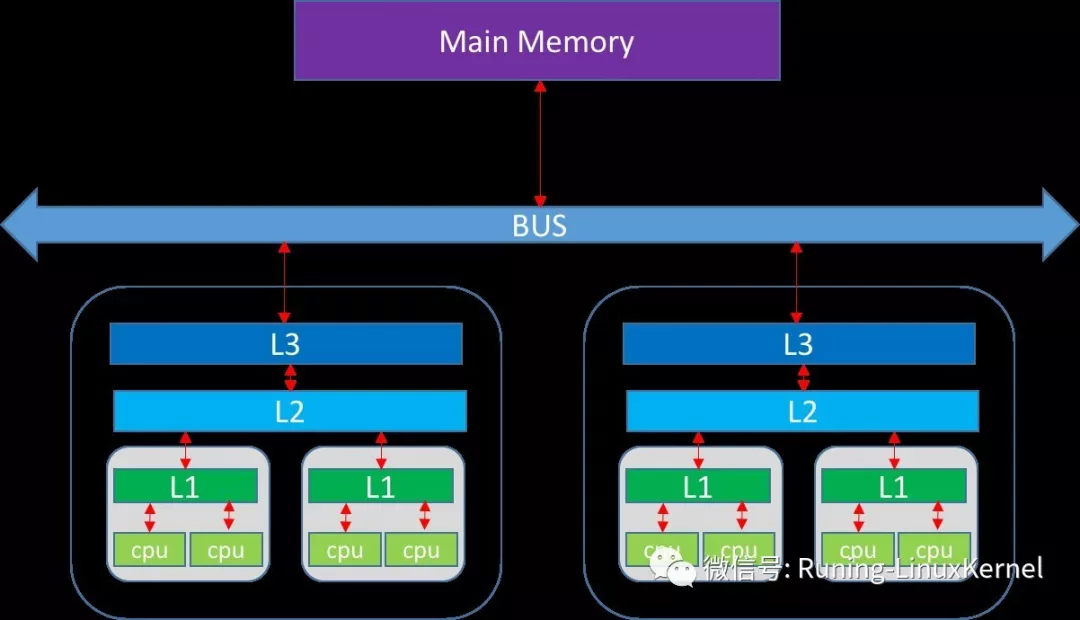
图1 经典处理器的存储结构
如图1所示,一个拥有2个CPU的系统, 每个CPU有两个Core, 每个Core有两个线程的Cache架构。每一个Core有单独的L1 cache, 它由其中的线程所共享, 每一个CPU中的所有Core共享同一个L2 Cache和L3 Cache。
L1 cache最靠近处理器核心,因此它的访问速度也是最快的,当然它的容量也是最小的。CPU访问各级的Cache速度和延迟是不一样的,L1 Cache的延迟最小,L2 Cache其次,L3 Cache最慢。
下面是Xeon 5500 Series的各级cache的访问延迟:(根据CPU主频的不同,1个时钟周期代表的时间也不一样,在1GHz主频的CPU下,一个时钟周期大概是1纳秒,在2.1GHz主频的CPU下,访问L1 Cache也就2个纳秒)。
表1:各级存储结构的访问延迟
| 访问类型 |
延迟 |
| L1 cache命中 |
约4个时钟周期 |
| L2 cache 命中 |
约10个时钟周期 |
| L3 cache命中 |
约40个时钟周期 |
| 访问本地DDR |
约60 纳秒 |
| 访问远端内存节点DDR |
约100纳秒 |
如表1所示,我们可以看到各级内存访问的延迟有很大的差异。CPU访问一块新的内存时,它会首先把包含这块内存的Cache Line大小的内容获取到L3 Cache,然后是载入到L2 Cache,最后载入到了L1 Cache。这个过程需要访问主存储器,因此延迟会很大,大约需要几十纳秒。当下次再读取相同一块数据的时候直接从L1 Cache里取数据的话,这个延迟大约只有4个时钟周期。当L1 Cache满了并且有新的数据要进来,那么根据Cache的置换算法会选择一个Cache line置换到L2 Cache里,L3 Cache也是同样的道理。
1.2 cache攻击
我们已经知道同一个CPU上的Core共享L2 cache和L3 Cache, 如果内存已经被缓存到CPU cache里, 那么同一个CPU的Core就会用较短的时间取到内存里的内容, 否则取内存的时间就会较长。两者的时间差异非常明显(大约有300个CPU时钟周期), 因此攻击者可以利用这个时间差异来进行攻击。
来看下面的示例代码:
1: clflush for user_probe[]; // 把user_probe_addr对应的cache全部都flush掉
2: u8 index = *(u8 *) attacked _mem_addr; // attacked_mem_addr存放被攻击的地址
3: data = user_probe_addr[index * 4096]; // user_probe_addr
存放攻击者可以放访问的基地址
user_probe_addr[]是一个攻击者可以访问的, 255 * 4096 大小的数组。
第1行, 把user_probe_addr数组对应的cache全部清除掉。
第2行, 我们设法访问到attacked_mem_addr中的内容. 由于CPU权限的保护, 我们不能直接取得里面的内容, 但是可以利用它来造成我们可以观察到影响。
第3行, 我们用访问到的值做偏移, 以4096为单位, 去访问攻击者有权限访问的数组,这样对应偏移处的内存就可以缓存到CPU cache里。
这样, 虽然我们在第2行处拿到的数据不能直接看到, 但是它的值对CPU cache已经造成了影响。
接下来可以利用CPU cache来间接拿到这个值. 我们以4096为单位依次访问user_probe_addr对应内存单位的前几个字节, 并且测量这该次内存访问的时间, 就可以观察到时间差异, 如果访问时间短, 那么可以推测访内存已经被cache, 可以反推出示例代码中的index的值。
在这个例子里, 之所以用4096字节做为访问单位是为了避免内存预读带来的影响, 因为CPU在每次从主存访问内存的时候, 根据局部性原理, 有可能将邻将的内存也读进来。Intel的开发手册上指明 CPU的内存预取不会跨页面, 而每个页面的大小是4096。
Meltdown[3]论文中给出了他们所做实验的结果, 引用如下:
图2 cache攻击数据对比
据此, 他们反推出index的值为84。
1.3 指令执行
经典处理器架构使用五级流水线:取指(IF)、译码(ID)、执行(EX)、数据内存访问(MEM)和写回(WB)。
现代处理器在设计上都采用了超标量体系结构(Superscalar Architecture)和乱序执行(Out-of-Order)技术,极大地提高了处理器计算能力。超标量技术能够在一个时钟周期内执行多个指令,实现指令级的并行,有效提高了ILP(InstructionLevel Parallelism)指令级的并行效率,同时也增加了整个cache和memory层次结构的实现难度。
在一个支持超标量和乱序执行技术的处理器中,一条指令的执行过程被分解为若干步骤。指令首先进入流水线(pipeline)的前端(Front-End),包括预取(fetch)和译码(decode),经过分发(dispatch)和调度(scheduler)后进入执行单元,最后提交执行结果。所有的指令采用顺序方式(In-Order)通过前端,并采用乱序的方式进行发射,然后乱序执行,最后用顺序方式提交结果。若是一条存储读写指令最终结果更新到LSQ(Load-StoreQueue)部件。LSQ部件是指令流水线的一个执行部件,可以理解为存储子系统的最高层,其上接收来自CPU的存储器指令,其下连接着存储器子系统。其主要功能是将来自CPU的存储器请求发送到存储器子系统,并处理其下存储器子系统的应答数据和消息。
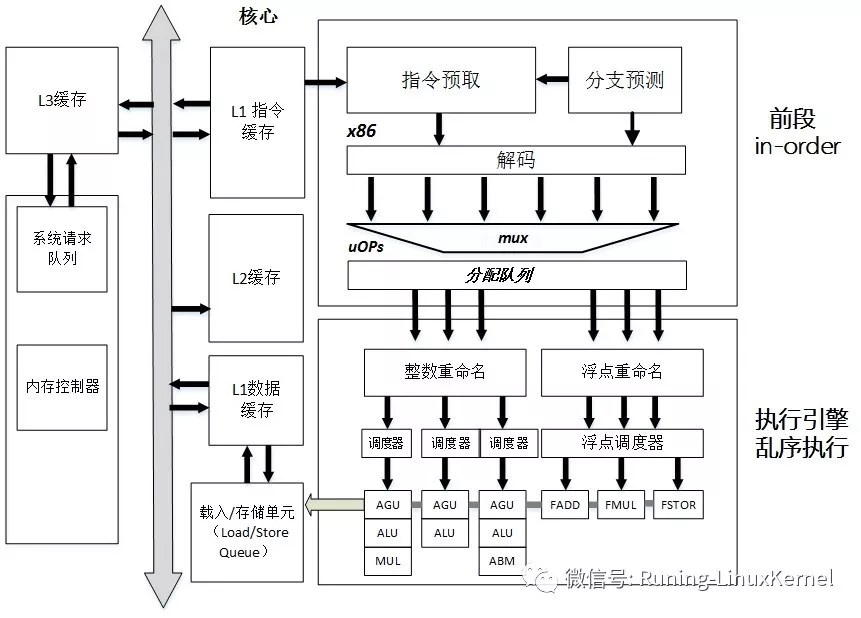
图3 经典x86处理器架构
如图3所示,在x86微处理器经典架构中,指令从L1指令cache中读取指令,L1指令cache会做指令加载、指令预取、指令预解码,以及分支预测。然后进入Fetch& Decode单元,会把指令解码成macro-ops微操作指令,然后由Dispatch部件分发到Integer Unit或者Float Point Unit。Integer Unit由Integer Scheduler和Execution Unit组成,Execution Unit包含算术逻辑单元(arithmetic-logic unit,ALU)和地址生成单元(address generation unit,AGU),在ALU计算完成之后进入AGU,计算有效地址完毕后,将结果发送到LSQ部件。LSQ部件首先根据处理器系统要求的内存一致性(memory consistency)模型确定访问时序,另外LSQ还需要处理存储器指令间的依赖关系,最后LSQ需要准备L1 cache使用的地址,包括有效地址的计算和虚实地址转换,将地址发送到L1 DataCache中。
1.4 乱序执行(out-of-order execution)
刚才提到了现代的处理器为了提高性能,实现了乱序执行(Out-of-Order,OOO)技术。在古老的处理器设计中,指令在处理器内部执行是严格按照指令编程顺序的,这种处理器叫做顺序执行的处理器。在顺序执行的处理器中,当一条指令需要访问内存的时候,如果所需要的内存数据不在Cache中,那么需要去访问主存储器,访问主存储器的速度是很慢的,那么这时候顺序执行的处理器会停止流水线执行,在数据被读取进来之后,然后流水线才继续工作。这种工作方式大家都知道一定会很慢,因为后面的指令可能不需要等这个内存数据,也不依赖当前指令的结果,在等待的过程中可以先把它们放到流水线上去执行。所以这个有点像在火车站排队买票,正在买票的人发现钱包不见了,正在着急找钱,可是后面的人也必须停下来等,因为不能插队。
1967年Tomasulo提出了一系列的算法来实现指令的动态调整从而实现乱序执行,这个就是著名的Tomasulo算法。这个算法的核心是实现一个叫做寄存器重命名(Register Rename)来消除寄存器数据流之间依赖关系,从而实现指令的并行执行。它在乱序执行的流水线中有两个作用,一是消除指令之间的寄存器读后写相关(Write-after-Read,WAR)和写后写相关(Write-after-Write,WAW);二是当指令执行发生例外或者转移指令猜测错误而取消后面的指令时,可用来保证现场的精确。其思路为当一条指令写一个结果寄存器时不直接写到这个结果寄存器,而是先写到一个中间寄存器过渡,当这条指令提交时再写到结果寄存器中。
通常处理器实现了一个统一的保留站(reservationstation),它允许处理器把已经执行的指令的结果保存到这里,然后在最后指令提交的时候会去做寄存器重命名来保证指令顺序的正确性。
如图3所示,经典的X86处理器中的“整数重命名”和“浮点重命名”部件(英文叫做reorder buffer,简称ROB),它会负责寄存器的分配、寄存器重命名以及指令丢弃(retiring)等作用。
x86的指令从L1 指令cache中预取之后,进入前端处理部分(Front-end),这里会做指令的分支预测和指令编码等工作,这里是顺序执行的(in-order)。指令译码的时候会把x86指令变成众多的微指令(uOPs),这些微指令会按照顺序发送到执行引擎(Execution Engine)。执行引擎这边开始乱序执行了。这些指令首先会进入到重命名缓存(ROB)里,然后ROB部件会把这些指令经由调度器单元发生到各个执行单元(Execution Unit,简称EU)里。假设有一条指令需要访问内存,这个EU单元就停止等待了,但是后面的指令不需要停顿下来等这条指令,因为ROB会把后面的指令发送给空闲的EU单元,这样就实现了乱序执行。
如果用高速公路要做比喻的话,多发射的处理器就像多车道一样,汽车不需要按照发车的顺序在高速公路上按顺序执行,它们可以随意超车。一个形象的比喻是,如果一个汽车抛锚了,后面的汽车不需要排队等候这辆汽车,可以超车。
在高速公里的终点设置了一个很大的停车场,所有的指令都必须在停车场里等候,然后停车场里有设置了一个出口,所有指令从这个出口出去的时候必须按照指令原本的顺序,并且指令在出口的时候必须进行写寄存器操作。这样从出口的角度看,指令就是按照原来的逻辑顺序一条一条出去并且写寄存器。
这样从处理器角度看,指令是顺序发车,乱序超车,顺序归队。那么这个停车场就是ROB,这个缓存机制可以称为保留站(reservation station),这种乱序执行的机制就是人们常说的乱序执行。
1.5 地址空间
现代的处理器为了实现CPU的进程虚拟化,都采用了分页机制,分页机制保证了每个进程的地址空间的隔离性。分页机制也实现了虚拟地址到物理地址的转换,这个过程需要查询页表,页表可以是多级页表。那么这个页表除了实现虚拟地址到物理地址的转换之外还定义了访问属性,比如这个虚拟页面是只读的还是可写的还是可执行的还是只有特权用户才能访问等等权限。
每个进程的虚拟地址空间都是一样的,但是它映射的物理地址是不一样的,所以每一个进程都有自己的页表,在操作系统做进程切换的时候,会把下一个进程的页表的基地址填入到寄存器,从而实现进程地址空间的切换。以外,因为TLB里还缓存着上一个进程的地址映射关系,所以在切换进程的时候需要把TLB对应的部份也清除掉。
当进程在运行的时候不可避免地需要和内核交互,例如系统调用,硬件中断。当陷入到内核后,就需要去访问内核空间,为了避免这种切换带来的性能损失以及TLB刷新,现代OS的设计都把用户空间和内核空间的映射放到了同一张页表里。这两个空间有一个明显的分界线,在Linux Kernel的源码中对应PAGE_OFFSET。
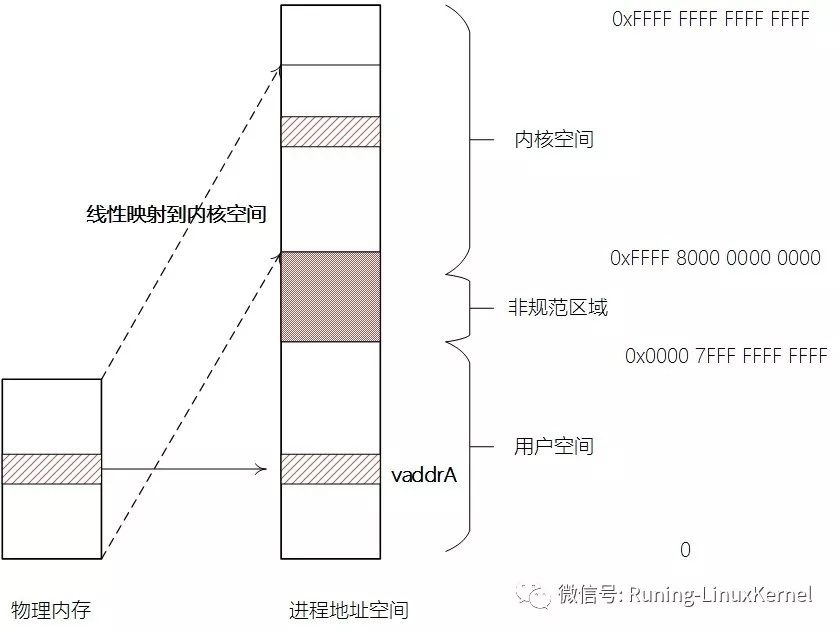
图4 进程地址空间
如图4所示,虽然两者是在同一张页表里,但是他们对应的权限不一样,内核空间部份标记为仅在特权层可以访问,而用户空间部份在特权层与非特权层都可以访问。这样就完美地把用户空间和内核空间隔离开来:当进程跑在用户空间时只能访问用户空间的地址映射,而陷入到内核后就即可以访问内核空间也可以访问用户空间。
对应地,页表中的用户空间映射部份只包含本机程可以访问的物理内存映射,而任意的物理内存都有可能会被映射到内核空间部分。
1.5 异常处理
CPU指令在执行的过程过有可能会产生异常,但是我们的处理器是支持乱序执行的,那么有可能异常指令后面的指令都已经执行了,那怎么办?
我们从处理器内部来考察这个异常的发生。操作系统为了处理异常,有一个要求就是,当异常发生的时候,异常发生之前的指令都已经执行完成,异常指令后面的所有指令都没有执行。但是我们的处理器是支持乱序执行的,那么有可能异常指令后面的指令都已经执行了,那怎么办?
那么这时候ROB就要起到清道夫的作用了。从之前的介绍我们知道乱序执行的时候,要修改什么东西都通过中间的寄存器暂时记录着,等到在ROB排队出去的时候才真正提交修改,从而维护指令之间的顺序关系。那么当一条指令发生异常的时候,它就会带着异常“宝剑”来到ROB中排队。ROB按顺序把之前的正常的指令都提交发送出去,当看到这个带着异常“宝剑”的指令的时候,那么就启动应急预案,把出口封锁了,也就是异常指令和其后面的指令会被丢弃掉,不提交。
但是,为了保证程序执行的正确性,虽然异常指令后面的指令不会提交,可是由于乱序执行机制,后面的一些访存指令已经把物理内存数据预取到cache中了,这就给Meltdown漏洞留下来后面,虽然这些数据会最终被丢弃掉。
2.Meltdown分析
下面我们对Meltdown漏洞做一些原理性的分析和后续修补的方案。
2.1 漏洞分析
理解了上述的背景知识以后就可以来看Meltdown是怎么回事了. 我们再回过头看看上面的例子:
1: clflush for user_probe[]; // 把user_probe_addr对应的cache全部都flush掉
2: u8 index = *(u8 *) attacked _mem_addr; // attacked_mem_addr存放被攻击的地址
3: data = user_probe_addr[index * 4096]; // user_probe_addr存放攻击者可以放访问的基地址
如果attached_mem_addr位于内核, 我们就可以利用它来读取内核空间的内容。
如果CPU顺序执行, 在第2行就会发现它访问了一个没有权限地址, 产生page fault (缺页异常), 进而被内核捕获, 第3行就没有机会运行。不幸的是, CPU会乱序执行, 在某些条件满足的情况下, 它取得了attacked _mem_addr里的值, 并在CPU将该指令标记为异常之前将它传递给了下一条指令, 并且随后的指令利用它来触发了内存访问。在指令提交的阶段CPU发现了异常,再将已经乱序执行指令的结果丢弃掉。这样虽然没有对指令的正确性造成影响, 但是乱序执行产生的CPU cache影响依然还是在那里, 并能被利用。
该场景有个前置条件,该条件在Meltdown[3]的论文里没有被提到,但在cyber[1] 的文章指出,attached_mem_addr必须要已经被缓存到了 CPU L1,因为这样才会有可能在CPU将指令标记为异常之前指数据传给后续的指令。 并且cyber 指出,只有attacked_mem_addr已经被缓存到CPU L1 才有可能成功,在L2,L3均不行,其理由是:
“The L1 Cache is a so called VIPT or Virtually Indexed, PhysicallyTagged cache. This means the data can be looked up by directly using thevirtual address of the load request”
“If the requested data was not found in the L1 cache the load must bepassed down the cache hierarchy. This is the point where the page tables comeinto play. The page tables are used to translate the virtual address into aphysical address. This is essentially how paging is enabled on x64. It isduring this translation that privileges are checked”
这几点理由很值得商榷:
1) AMD的开发手册[10]没有找到L1 cache是VIPT的证据,Intel的开发手册[9]上只能从” L1 Data Cache Context Mode”的描述上推测NetBurst架构的L1 cache是VIPT的。
2) 就算L1 cache 是 VIPT,那也需要获得physicaladdress,必然会用到TLB里的内容或者进行页表的遍历。
那么如何来将要被攻击的内存缓存到L1里呢? 有两种方法:
1) 利用系统调用进入内核。如果该系统调用的路径访问到了该内存,那么很有可能会将该内存缓存到L1 (在footprint不大于L1大小的情况下)。
2) 其次是利用prefetch指令。 有研究[8]显示,Intel的prefetch指令会完全忽略权限检查,将数据读到cache。
我们知道,如果进程触发了不可修复的page fault,内核会向其发送SIGSEGV信号,该信号不能被用户空间捕获,所以该进程会被杀掉。所以这里有两种操作方法,其一是创建一个子进程,在子进程中触发上述的代码访问,然后在父进程中去测算user_probe_addr[]的访问时间。 所以每一次探测都需要另起一个新进程,这样会影响效率。
另一种方法是利用Intel的事务内存处理(Intel®Transactional Synchronization Extensions),该机制以事务为单元来对一系列内存操作做原子操作,如果一个事务内的内存操作全部成功完成且没有其它CPU造成内存的竞争,那么就会将该事务对应的结果进行提交,否则将中断该事务。如果我们将上述代码包含到一个内存事务中,对被攻击地址的访问并不会造成pagefault,只会被打断事务。 这样我们可以在不需要生成子进程的条件下持续进行攻击。
这里有一个很有意思的现象,上述代码在第2行处读到的index有时会全为0,不同的资料有不同的解释:
1) cyber[1]给出的解释是: “Fortunately Idid not get a slow read suggesting that Intel null’s the result when the access is notallowed”。
2) google zero project[2]给出的解释是: “That (read from kernel address returns all-zeroes) seems to happen for memory that is not sufficiently cached but for which pagetable entries are present, at least after repeated read attempts. For unmapped memory, the kernel address read does not return a result at all.”
3) Meltdown paper[3]给出的解释是: “If the exception is triggered whiletrying to read from an inaccessible kernel address,the register where the data shouldbe stored,appears to bezeroed out. This is reasonable because if the exception is unhandled,the user space application isterminated,and the valuefrom the inaccessible kernel address could be observed in the register contentsstored in the core dump of the crashed process. The direct solution to fix thisproblem is to zero out the corresponding registers. If the zeroing out of theregister is faster than the execution of the sub- sequent instruction (line 5in Listing 2),the attackermay read a false value in the third step”。
这个解释比较有意思,他们首先认为,将读到的内容清零是有必要的,否则读到的内容会保存到这个程序的core dump里。 果真会如此么? Terminate 进程和生产core dump都需要OS去做,软件不可能直接访问到乱序执行所访问的寄存器。
其次他们认为,该问到0是因为值传递给下一条指令的速度要慢于将值清0的操作,所以他们的解决方法是:
“prevent the tran- sientinstruction sequence from continuing with a wrong value,i.e.,‘0’,Meltdown retries reading the address until itencounters a value different from ‘0’”
所以他们的示例代码是长这样的:
他们在读到0时现再重试. 然而, 如果真的读到清0的数据, retry并不会有机会再被执行到, 因为此时很有可能异常已经被捕获。
2.2 漏洞修复
在漏洞被报告给相关厂商后,各OS和开源社区开始了修复工作,LinuxKernel采用的是Kernelpage-table isolation (KPTI)[6][7],据说Windows和Mac OS的修复也是类似的思路。
在前面的背景知识中看到, 当前的OS采用用户空间和内核空间分段的设计, 这样使得Kernel和Usersapce使用同一张页表, 位于同一个TLB context中, 所以CPU在做预取和乱序的时候可以使用TLB中的cache做地址转换, 进而获得CPU Cache中的数据, 如果我们能够让用户空间不能使用TLB中关于内核地址映射的信息, 这样就可以断掉用户空间对Cache中kernel数据的访问,这也是KPTI的思路。
KPTI将之前OS设计中, 每个进程使用一张页表分隔成了两张, kernelspace和userspace使用各自分离的页表。我们暂且称进程在kernel模式使用的页表称为Kernel页表, 相应地进程在用户空间使用的页表被称为用户页表。
具体地来说, 当进程运行在用户空间时, 使用的是用户页表, 当发生中断或者是异常时, 需要陷入到内核, 进入内核空间后, 有一小段内核跳板将页表切换到内核页表, 当进程从kernel空间跳回到用户空间时, 页表再次被切换回用户页表。
Kernel页表包含了进程用户空间地址的映射和Kernel使用的内存映射, 所以Kernel依然可以使用当前进程的内存映射。用户页表仅仅包含了用户空间的内存映射以及内核跳板的内存映射。
2.3 性能影响
从这里可以看到, 每一次用户空间到内核空间的切换都需要切换页表, 在没有PCID支持的CPU上, 切换页表 (reload CR3) 会flush除了global page以外的所有TLB。然而, 即使在支持PCID的情况下, 由于引入的中间跳板, 性能损失仍然存在. 一位开发者指出在有CPID支持的情况下, 通常的workload会有5%的性能损失, 某些workload会达到30%。
3. 总结
在这里需要指出的是, 也是所有paper没有提到的, 虽然在当前的OS的设计中, 进程在内核空间和用户空间使用的是同一张页表, 但是该页表的内核部份映射的生成是on-demand的, 即在访问的时候才会被逐渐映射,因此只有在系统调用上被touch到的内存才有可能被映射到页表里。所以被严格限制系统调用的用户攻击难度会更大一些, 例如使用seccomp,然后尽管如此, 所有的代码路径不可能完全被审计到。
Meltdown漏洞并不需要利用已有的软件缺陷, 仅仅只需攻击者和受害者在只有一个地址空间中就会有影响, 比如基于container的Docker、 Xen的PV guest等等。基于硬件虚拟化的VM并不会受其影响,然而情况不容乐观, 接下来要分析的Spectre具有更大范围的破坏力。
虽然这篇文章是以cache为例来描述攻击, 但是对体系体构可观察到的影响都可以拿来作为攻击的手段, 比如诱发CPU算术单元的繁忙运算后再来观突某条算术指令执行的时间, 再如观察不同情况下的电力消耗等等。
这一次漏洞的影响之大足以被写进教科书, 甚至会影响接下来所有硬件和OS的设计, 2018年或许是OS, Hardware, Security的新起点。
参考资料
[1] Negative Result:Reading Kernel Memory From User Modehttps://cyber.wtf/2017/07/28/negative-result-reading-kernel-memory-from-user-mode/
[2] Google Zero Projecthttps://googleprojectzero.blogspot.com/
[3] Meltdownhttps://meltdownattack.com/meltdown.pdf
[4] Spectre Attacks:Exploiting Speculative Execution https://spectreattack.com/spectre.pdf
[5] KAISER: hiding thekernel from user space https://lwn.net/Articles/738975/
[6] The current state ofkernel page-table isolation https://lwn.net/Articles/741878/
[7] Kernel page-tableisolation https://en.wikipedia.org/wiki/Kernel_page-table_isolation
[8] Prefetch Side-ChannelAttacks: Bypassing SMAP and Kernel ASLR https://gruss.cc/files/prefetch.pdf
[9] Intel® 64 and IA-32architectures software developer’s manualhttps://software.intel.com/sites/default/files/managed/39/c5/325462-sdm-vol-1-2abcd-3abcd.pdf
[10] AMD64 ArchitectureProgrammer’s Manual https://developer.amd.com/resources/developer-guides-manuals/