程序员深夜用Python跑神经网络,只为用中二动作关掉台灯

导读:对于上了床就再也不想下来的人来说,关灯成为睡觉前面临的最大挑战!
然而,一个来自意大利拉不勒斯的小哥哥,决定利用“舞步”(身体姿势)来控制自己家的灯,整个过程利用一个神经网络实现。
编译:啤酒泡泡、曹培信
来源:大数据文摘(ID:BigDataDigest)
原文:MakeArtWithPython
此前,关于关灯这件事,这一届网友永远不会让人失望,他们开发出了各种关灯大法:
当然少不了憨豆先生最简单粗暴的关灯方式:

而小哥哥的“舞步”是这样的:
下面是小哥哥写的教程,我们在不改变原意的基础上进行了编译。
在今天的文章里,我将手把手教大家训练一个神经网络模型,用来识别摄像头拍下的“舞步”,从而控制灯的开关。
我们将在已有的OpenPose深度学习模型之上建立我们自己的模型来识别身体的位置,然后,我们会建立一些样本来代表各种身体的各种姿态。
当我们建立好舞步(包括嘻哈超人舞步、T-Pose舞步)和其他身体姿态的样本后,我们会清理数据集,然后利用这些样例训练我们的神经网络。
当神经网络训练好之后,我们会用它来控制灯光。
今天的文章包括很多步骤,不过,所有的代码都在Github上,上面还包括了我已经搜集到的原始数据样例。
GitHub链接:
https://github.com/burningion/dab-and-tpose-controlled-lights
01 编写“编写软件”的软件:怎样训练你的神经网络?

首先就是数据——大量数据。
我们今天即将采用的
神经网络
模型卡内基梅隆大学的团队也曾经使用过,他们用自己的全景数据集来训练该模型。该数据集包括五个半小时的视频,视频中包含了150万个手动添加的代表人体骨骼位置的标签。
整个全景工作室的圆屋顶上装有500个摄像头,所有摄像头都对准人,从不同角度记录他们的动作。
这个全景工作室用构造训练数据集几乎是完美的,很方便进行计算机视觉的实验。

今天,我们将在他们的工作基础之上开始我们的工作。
首先我们会用他们的工具来创建一个很小的数据集。我们最终的神经网络只会使用171个姿态,包括记录的嘻哈超人舞步、T-Pose舞步和其他姿态。每一个姿态样例都是从卡耐基梅隆大学已有的工作中提取出来的。
神经网络的一个好处就是你可以使用别人已经建成的模型,然后加入一些新的神经网络层,以此来扩展该模型。这个过程被称之为
迁移学习
,因此我们可以用有限的资源来进行迁移学习。
从技术上来说,我们不会在这个项目中使用迁移学习,因为我们会对OpenPose的工作做一些细微的修改,然后创建一个独立的神经网络。
那么问题来了,我们该如何获取数据呢?
02 写一个程序并利用OpenCV来收集带标签的数据
使用OpenPose的成果,
我们得到了25个代表人体骨骼架构的标签。
我们可以写一个程序来控制网络摄像头,在图像上运行OpenPose,然后将动作与键盘上的按键相对应。

也就是说,我们做出一个T-Pose的动作,然后在键盘上点击m键,那么这个动作就被归到T-Pose那一类里。我们按照这个方法去添加171个不同的姿势,这样一来,我们就有数据训练神经网络了。以下是用于数据收集的代码的示例:
# create lists for dab, tpose, other examples
dabs = []
tposes = []
other = []
fps_time = 0
# loop forever, reading webcam each time
while True:
ret_val, frame = vs.read()
datum.cvInputData = frame
opWrapper.emplaceAndPop([datum])
# need to be able to see what's going on
image = datum.cvOutputData
cv2.putText(image,
"FPS: %f" % ( 1.0 / (time.time() - fps_time)),
( 10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
( 0, 255, 0), 2)
cv2.imshow( "Openpose", image)
fps_time = time.time()
# quit with a q keypress, b or m to save data
key = cv2.waitKey( 1) & 0xFF
if key == ord( "q"):
break
elif key == ord( "b"):
print( "Dab: " + str(datum.poseKeypoints))
dabs.append(datum.poseKeypoints[ 0])
elif key == ord( "m"):
print( "TPose: " + str(datum.poseKeypoints))
tposes.append(datum.poseKeypoints[ 0])
elif key == ord( "/"):
print( "Other: " + str(datum.poseKeypoints))
other.append(datum.poseKeypoints[ 0])
# write our data as numpy binary files
# for analysis later
dabs = np.asarray(dabs)
tposes = np.asarray(tposes)
other = np.asarray(other)
np.save( 'dabs.npy', dabs)
np.save( 'tposes.npy', tposes)
np.save( 'other.npy', other)
dabs = []
tposes = []
other = []
fps_time = 0
# loop forever, reading webcam each time
while True:
ret_val, frame = vs.read()
datum.cvInputData = frame
opWrapper.emplaceAndPop([datum])
# need to be able to see what's going on
image = datum.cvOutputData
cv2.putText(image,
"FPS: %f" % ( 1.0 / (time.time() - fps_time)),
( 10, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
( 0, 255, 0), 2)
cv2.imshow( "Openpose", image)
fps_time = time.time()
# quit with a q keypress, b or m to save data
key = cv2.waitKey( 1) & 0xFF
if key == ord( "q"):
break
elif key == ord( "b"):
print( "Dab: " + str(datum.poseKeypoints))
dabs.append(datum.poseKeypoints[ 0])
elif key == ord( "m"):
print( "TPose: " + str(datum.poseKeypoints))
tposes.append(datum.poseKeypoints[ 0])
elif key == ord( "/"):
print( "Other: " + str(datum.poseKeypoints))
other.append(datum.poseKeypoints[ 0])
# write our data as numpy binary files
# for analysis later
dabs = np.asarray(dabs)
tposes = np.asarray(tposes)
other = np.asarray(other)
np.save( 'dabs.npy', dabs)
np.save( 'tposes.npy', tposes)
np.save( 'other.npy', other)
然后用NumPy的数组来储存特征,并用np.save函数把特征保存为二进制文件以便后续使用。我个人倾向于使用Jupyter notebook来观察和处理数据。
当数据收集好之后,我们可以观察并清理数据以便更好地去训练模型。
03 观察数据、清理数据以及使用数据训练模型
这部分看上去很复杂,但是通过使用Jupyter notebook、NumPy和Keras,我们就可以很直观地去观察数据、清理数据,并且使用数据来训练神经网络。
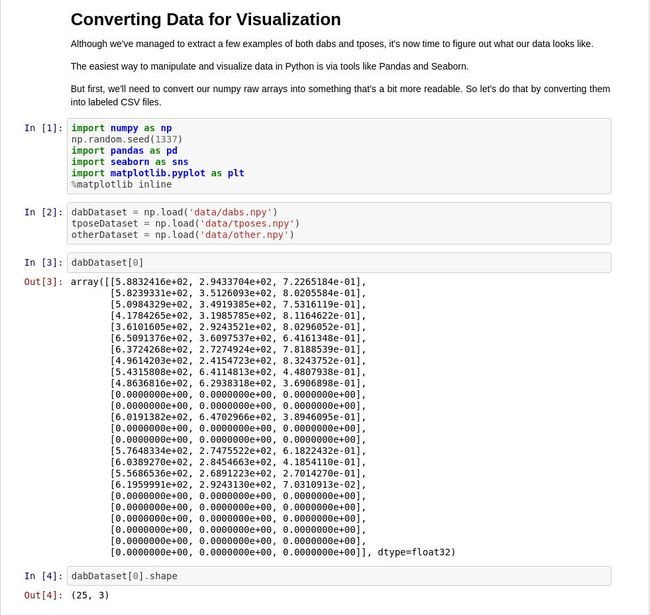
根据我们的截图,我们可以发现npy文件中保存的数据和OpenPose模型本身都有三个维度,25个已知的身体位置坐标点,X、Y、以及Confidence。
我们的模型训练工作不需要用到confidence。如果某个身体位置坐标点被命名了,我们就保留它,否则,我们就直接让它为0。
我们已经把(绝大部分)数据梳理好了,现在我们需要把数据特征和标签结合起来。
我们用0代表其他姿势,1代表嘻哈超人舞步、2代表T-Pose舞步。
labels = np.zeros(len(otherDataset))
labels = np.append(labels, np.full((len(dabDataset)), 1))
labels = np.append(labels, np.full((len(tposeDataset)), 2))
print(labels)
print( "%i total examples for training." % len(labels))
labels = np.append(labels, np.full((len(dabDataset)), 1))
labels = np.append(labels, np.full((len(tposeDataset)), 2))
print(labels)
print( "%i total examples for training." % len(labels))
接下来,我们可以使用独热编码处理我们的数字标签。也就是说,我们将标签0、1、2转换成[1,0,0]、[0,1,0]、[0,0,1]。之后,我们可以使用sklearn的shuffle函数将数据标签和特征打乱(数据标签和特征仍保持原有的对应关系)
# now, let's shuffle labels and the array, the same way
from sklearn.utils import shuffle
X1, y1 = shuffle(dataset, labels)
# now let's label them for 'one hot'
from keras.utils.np_utils import to_categorical
y1 = to_categorical(y1, 3) # we have 3 categories, dab, tpose, other
print(y1.shape[ 1)]
from sklearn.utils import shuffle
X1, y1 = shuffle(dataset, labels)
# now let's label them for 'one hot'
from keras.utils.np_utils import to_categorical
y1 = to_categorical(y1, 3) # we have 3 categories, dab, tpose, other
print(y1.shape[ 1)]
我们的输入数据代表着鼻子、手等等的位置,而它们的是介于0到720和0到1280之间的像素值,所以我们需要把数据归一化。这样一来,
我们可以重复使用我们的模型而不用考虑输入图片数据的分辨率。
X1[:,:,
0] = X1[:,:,
0] /
720
# I think the dimensions are 1280 x 720 ?
X1[:,:, 1] = X1[:,:, 1] / 1280 # let's see?
X1 = X1[:,:, 1:]
print(X1.shape)
X1 = X1.reshape(len(X1), 50) # we got rid of confidence percentage
X1[:,:, 1] = X1[:,:, 1] / 1280 # let's see?
X1 = X1[:,:, 1:]
print(X1.shape)
X1 = X1.reshape(len(X1), 50) # we got rid of confidence percentage
在最后一步中,我们将把我们的多维数据变成一维。我们会分批向模型输入50个位置信息(25个部位,每个部位的X和Y值)。
04 构建并训练我们的模型
在Jupyter notebook中使用Keras可以把训练和测试神经网络模型的工作变得十分简单,这也是我最喜欢Keras的地方。
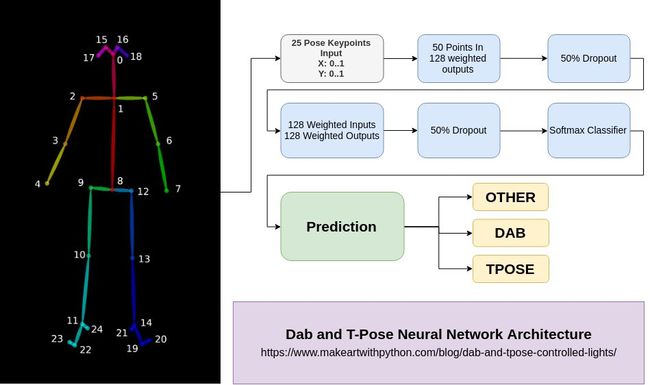
现在我们的数据已经贴上标签准备就绪了,我们可以开始训练一个简单的模型了,
只需要几行代码。
现在我们导入Keras库然后训练一个简单的神经网络模型。
from keras.models
import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.optimizers import SGD
model = Sequential()
model.add(Dense( 128, activation= 'relu', input_shape=( 50,)))
model.add(Dropout( 0.5))
model.add(Dense( 128, activation= 'relu'))
model.add(Dropout( 0.5))
model.add(Dense(y1.shape[ 1], activation= 'softmax'))
model.compile(optimizer= 'Adam',
loss= 'categorical_crossentropy',
metrics=[ 'accuracy'])
model.fit(X1, y1, epochs= 2000,batch_size= 25)
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.optimizers import SGD
model = Sequential()
model.add(Dense( 128, activation= 'relu', input_shape=( 50,)))
model.add(Dropout( 0.5))
model.add(Dense( 128, activation= 'relu'))
model.add(Dropout( 0.5))
model.add(Dense(y1.shape[ 1], activation= 'softmax'))
model.compile(optimizer= 'Adam',
loss= 'categorical_crossentropy',
metrics=[ 'accuracy'])
model.fit(X1, y1, epochs= 2000,batch_size= 25)
搞定!
这里有个稍微需要注意的地方,输入层的大小为50,提醒大家一下,这个数字是OpenPose模型中位置点的X坐标和Y坐标数量之和。
最后我们用到了Softmax层,它是用来分类的。我们将y.shape[1]传入该层,这样我们的模型就知道不同类别的数量了。
最后的最后,我们使用输入数据,用model.fit()的方法去训练模型。这里,我已经做了2000次迭代(全部样本训练一次为一次迭代)。2000次迭代貌似有点多了,500次左右的迭代可能更好,因为迭代次数过多可能使我们的模型出现一些过拟合问题。但是不论是哪一种情况,你都需要经过多次尝试来确定迭代次数。
当我们运行这段代码时,我们会看到准确度在提高。如果你看不到,请再次确认当你打乱数据时,数据标签和数据特征的对应关系是不变的。此外,也要确认数据里的数值是不是在0到1之间。
最后,我们可以保存训练后的模型,也可以使用样本数据集来测试该模型,保存模型的代码很简单:
model.save(
'data/dab-tpose-other.h5')
# save our model as h5
# in our other code, or inline, load the model and test against sample dab dataset
import keras
modello = keras.models.load_model( 'data/dab-tpose-other.h5')
dabDataset = np.load( 'data/test-dabs.npy')
dabDataset[:,:, 0] = dabDataset[:,:, 0] / 720 # I think the dimensions are 1280 x 720 ?
dabDataset[:,:, 1] = dabDataset[:,:, 1] / 1280 # let's see?
dabDataset = dabDataset[:,:, 1:]
dabDataset = dabDataset.reshape(len(dabDataset), 50)
modello.predict_classes(dabDataset) # returns array([1, 1, 1, 1, 1, 1])
# in our other code, or inline, load the model and test against sample dab dataset
import keras
modello = keras.models.load_model( 'data/dab-tpose-other.h5')
dabDataset = np.load( 'data/test-dabs.npy')
dabDataset[:,:, 0] = dabDataset[:,:, 0] / 720 # I think the dimensions are 1280 x 720 ?
dabDataset[:,:, 1] = dabDataset[:,:, 1] / 1280 # let's see?
dabDataset = dabDataset[:,:, 1:]
dabDataset = dabDataset.reshape(len(dabDataset), 50)
modello.predict_classes(dabDataset) # returns array([1, 1, 1, 1, 1, 1])
05 用模型来控制灯光
我们现在已经有了可以识别姿势的模型,接下来要做的只是把这个模型和无线灯光控制关联起来就行了。
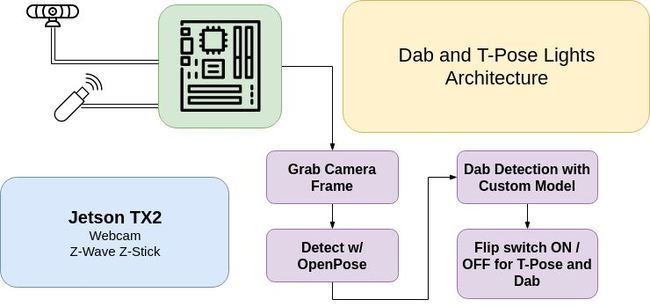
在我的这个例子中,我使用Aeotec Z-Stick来发送Z-Wave指令,并配有两个GE Z-Wave的室外开关。USB接口接入到NVIDIA TX2人工智能模块,其实NVIDIA的Jestson Nano也能胜任,尽管Jetson Nano所能提供的分辨率要低于我样例中1280x720的分辨率。当Z-Stick插入到ARM设备后,你首先需要把开关调到Z-Wave模式,可能需要多按几下USB Stick上的按钮和灯的开关。
代码并不复杂,基本上就是训练环境再加上一个额外的步骤。现在,我们导入Keras,然后使用清理过的数据训练模型。
import cv2
import pyopenpose as op
from imutils import translate, rotate, resize
import openzwave
from openzwave.option import ZWaveOption
from openzwave.network import ZWaveNetwork
# make sure these commands get flushed by doing them first, then loading tensorflow...
# tensorflow should take enough time to start for these commands to flush
options = ZWaveOption( '/dev/ttyACM0')
options.lock()
network = ZWaveNetwork(options)
import time
import numpy as np
np.random.seed( 1337)
import tensorflow as tf
# make sure tensorflow doesn't take up all the gpu memory
conf = tf.ConfigProto()
conf.gpu_options.allow_growth= True
session = tf.Session(config=conf)
import keras
# Custom Params (refer to include/openpose/flags.hpp for more parameters)
params = dict()
params[ "model_folder"] = "../../models/"
# built in TX2 video capture source
vs = cv2.VideoCapture( "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=(int)1280, height=(int)720,format=(string)NV12, framerate=(fraction)24/1 ! nvvidconv flip-method=0 ! video/x-raw, format=(string)BGRx ! videoconvert ! video/x-raw, format=(string)BGR ! appsink")
tposer = keras.models.load_model( 'dab-tpose-other.h5')
# Starting OpenPose
opWrapper = op.WrapperPython()
opWrapper.configure(params)
opWrapper.start()
datum = op.Datum()
np.set_printoptions(precision= 4)
fps_time = 0
DAB = 1
TPOSE = 2
OTHER = 0
LIGHTS = 0
bounced = time.time()
debounce = 3 # wait 3 seconds before allowing another command
while True:
ret_val, frame = vs.read()
datum.cvInputData = frame
opWrapper.emplaceAndPop([datum])
# need to be able to see what's going on
image = datum.cvOutputData
cv2.putText(image,
"FPS: %f" % ( 1.0 / (time.time() - fps_time)),
( 10, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
( 0, 255, 0), 2)
cv2.imshow( "Openpose", image)
if datum.poseKeypoints.any():
first_input = datum.poseKeypoints
try:
first_input[:,:, 0] = first_input[:,:, 0] / 720
first_input[:,:, 1] = first_input[:,:, 1] / 1280
first_input = first_input[:,:, 1:]
first_input = first_input.reshape(len(datum.poseKeypoints), 50)
except:
continue
output = tposer.predict_classes(first_input)
for j in output:
if j == 1:
print( "dab detected")
if LIGHTS == 0 or (time.time() - bounced) < debounce:
continue
for node in network.nodes:
for val in network.nodes[node].get_switches():
network.nodes[node].set_switch(val, False)
LIGHTS = 0
bounced = time.time()
elif j == 2:
print( "tpose detected")
if LIGHTS == 1 or (time.time() - bounced) < debounce:
continue
for node in network.nodes:
for val in network.nodes[node].get_switches():
network.nodes[node].set_switch(val, True)
LIGHTS = 1
bounced = time.time()
fps_time = time.time()
# quit with a q keypress, b or m to save data
key = cv2.waitKey( 1) & 0xFF
if key == ord( "q"):
break
# clean up after yourself
vs.release()
cv2.destroyAllWindows()
import pyopenpose as op
from imutils import translate, rotate, resize
import openzwave
from openzwave.option import ZWaveOption
from openzwave.network import ZWaveNetwork
# make sure these commands get flushed by doing them first, then loading tensorflow...
# tensorflow should take enough time to start for these commands to flush
options = ZWaveOption( '/dev/ttyACM0')
options.lock()
network = ZWaveNetwork(options)
import time
import numpy as np
np.random.seed( 1337)
import tensorflow as tf
# make sure tensorflow doesn't take up all the gpu memory
conf = tf.ConfigProto()
conf.gpu_options.allow_growth= True
session = tf.Session(config=conf)
import keras
# Custom Params (refer to include/openpose/flags.hpp for more parameters)
params = dict()
params[ "model_folder"] = "../../models/"
# built in TX2 video capture source
vs = cv2.VideoCapture( "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=(int)1280, height=(int)720,format=(string)NV12, framerate=(fraction)24/1 ! nvvidconv flip-method=0 ! video/x-raw, format=(string)BGRx ! videoconvert ! video/x-raw, format=(string)BGR ! appsink")
tposer = keras.models.load_model( 'dab-tpose-other.h5')
# Starting OpenPose
opWrapper = op.WrapperPython()
opWrapper.configure(params)
opWrapper.start()
datum = op.Datum()
np.set_printoptions(precision= 4)
fps_time = 0
DAB = 1
TPOSE = 2
OTHER = 0
LIGHTS = 0
bounced = time.time()
debounce = 3 # wait 3 seconds before allowing another command
while True:
ret_val, frame = vs.read()
datum.cvInputData = frame
opWrapper.emplaceAndPop([datum])
# need to be able to see what's going on
image = datum.cvOutputData
cv2.putText(image,
"FPS: %f" % ( 1.0 / (time.time() - fps_time)),
( 10, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
( 0, 255, 0), 2)
cv2.imshow( "Openpose", image)
if datum.poseKeypoints.any():
first_input = datum.poseKeypoints
try:
first_input[:,:, 0] = first_input[:,:, 0] / 720
first_input[:,:, 1] = first_input[:,:, 1] / 1280
first_input = first_input[:,:, 1:]
first_input = first_input.reshape(len(datum.poseKeypoints), 50)
except:
continue
output = tposer.predict_classes(first_input)
for j in output:
if j == 1:
print( "dab detected")
if LIGHTS == 0 or (time.time() - bounced) < debounce:
continue
for node in network.nodes:
for val in network.nodes[node].get_switches():
network.nodes[node].set_switch(val, False)
LIGHTS = 0
bounced = time.time()
elif j == 2:
print( "tpose detected")
if LIGHTS == 1 or (time.time() - bounced) < debounce:
continue
for node in network.nodes:
for val in network.nodes[node].get_switches():
network.nodes[node].set_switch(val, True)
LIGHTS = 1
bounced = time.time()
fps_time = time.time()
# quit with a q keypress, b or m to save data
key = cv2.waitKey( 1) & 0xFF
if key == ord( "q"):
break
# clean up after yourself
vs.release()
cv2.destroyAllWindows()
到了这一步,工作基本上就算完成了!
我们成功地训练了一个用于识别嘻哈超人舞步、T-Pose舞步的神经网络模型,然后我们可以让它根据我们的舞步来制造可互动的灯。
太棒了,给自己点个赞!
06 后记
所有代码、模型以及训练数据都免费公布在Github上。
我建议你们在Jupyter notebook上试试这个项目。我的代码中有个漏洞,我一直无法从自己的工作簿中找出来。这个漏洞导致我的原始的X和Y标签并没有被正确地标记。如果你找到了解决这个漏洞的方法,记得在Github上创建一个Pull Request(PR)。
另外,我们今天构建的基础模型可以用来训练很多类型的舞蹈动作。尽管我的模型每秒只能捕捉很少的画面,但我们可以开始建立一个有关舞步的数据集,然后再构建一个能识别这些不同舞步的神经网络模型。
相关报道:
https://www.makeartwithpython.com/blog/dab-and-tpose-controlled-lights/
有话要说
Q:
万能的Python还有哪些神应用?
欢迎留言与大家分享
猜你想看
更多精彩
在公众号对话框
输入以下
关键词
查看更多优质内容!
PPT
|
报告
|
读书
|
书单
|
干货
大数据
|
揭秘
|
Python
|
可视化
AI
|
人工智能
|
5G
|
区块链
机器学习
|
深度学习
|
神经网络
合伙人
|
1024
|
段子
|
数学
|
高考
据统计,99%的大咖都完成了这个神操作
觉得不错,请把这篇文章分享给你的朋友
转载 / 投稿请联系:[email protected]
更多精彩,请在后台点击“历史文章”查看