BLEU : 一种机器翻译自动评价方法
BLEU : 一种机器翻译自动评价方法
BLEU:a Method for Automatic Evaluation of Machine Translation(1)
Kishore Papineni,Salim Roukos,Todd Ward, and Wei-Jing Zhu
编译: 洪洁 文章来源:多语工程技术研究中心《云翻译技术》第12期
摘要:这篇论文是关于BLEU方法的最原始的文字,由IBM公司的研究人员发表。论文从机器翻译评价的研究背景开始,详细介绍了BLEU 方法的基本原理,基本要素,和基本测量指标的选取、指标的修正,以及最终获取BLEU值的计算公式。论文中还对BLEU值的可信性的进行了考察。研究者们作了一系列的翻译评价测试,观测基本测量指标值和最终的BLEU值能否区分人工翻译结果和机器翻译结果,不同的机器翻译结果和不同的人工翻译结果。最后,研究者们还对BLEU值评分和人工评分作了一个相关性分析。
1. 研究背景
论文首先提到为什么要进行这个研究。对机器翻译作人工评价时会考量到翻译的许多方面:如翻译的充分性、忠实度、和流畅度。通常这些人工评价工作非常费时也非常昂贵。对于机器翻译的研发人员来说这种人工评价方式非常不方便,因为他们需要对机器翻译系统作日常的监测和评估,以了解每个小改变,从而甄选出好的想法。
在这篇论文中,研究者们提出一种快速、费用低廉、不受语言种类限制,而且同人工评价高度相关的机器翻译自动评价方法。他们是如何评价翻译的好坏呢?
研究者们的评价方法所依据的论点是:机器翻译同专业人工翻译越接近越好。为了评价机器翻译质量,他们还需要使用某种“数值型度量指标”来衡量机器译文同人工翻译的参考译文的相近程度。因此这个新的自动评价系统包括两个要素:
l 数值型度量指标,用来计量待测翻译结果同参考译文的相近程度;
l 高质量的人工翻译参考译文。
其中数值型度量指标参考了语音识别工作中使用的“单词出错率”这个指标,并作了一些调整:如使用多个参考译文,允许选用不同的单词(同义词)和不同的词语顺序。
2. BLEU方法使用的基本度量指标和概念
2.1 “n单位片段” (n-gram)
由于语言的多样性和复杂性,在通常情况下,一句话会有多个“正确”的翻译方式,对应着多个正确的译文。这些译文中可能选用不同的词语,或者是选用的词语相同而语言顺序不同,而人类总是能够清楚地分辨出哪个是更好的译文。比如例1中对同一句汉语的两种译法:
例1:
待评价译文 1: It is a guide to action which ensures that the military always obeys the commands of the party.
待评价译文 2: It is to insure the troops forever hearing the activity guidebook that party direct.
两个译文质量差别明显,待评价译文1 的质量明显好于待评价译文2。为了比较, 我们为这句话提供了三个参考译文:
参考译文 1: It is a guide to action that ensures that the military will forever heed Party commands.
参考译文 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
参考译文 3: It is the practical guide for the army always to heed the directions of the party.
可以看到待评价译文1同三个参考译文有着较多的相同字词和短语,而待评价译文2 则没有。待评价译文1同参考译文1 相同的部分有 ‘It is a guide to action ’‘ensures that the military ’‘commands’,同参考译文2 相同的部分有‘which’‘always’‘of the party ’, 同参考译文3 相同的部分有‘always’。 相比之下, 待评价译文2 同三个参考译文的相似处极少。
BLEU 方法便是对待评价译文和参考译文的“n-单位片段(n-gram)”进行比较,并计算出匹配片段的个数。这些匹配片段与它们在文字中存在的位置无关。匹配片段数越多,则待评价译文质量越好。作者从最简单的情况,“1单位片段(unigram)”匹配情况开始介绍。
2.2 精确度(Precision)和“修正的n-单位精确度”(modified n-gram precision)
论文中研究者们使用的“数值型度量指标”基础是精确度(precision) 的测量。先来看“1单位片段”(unigram)的情况。在例1中,将待评价译文和三个参考译文进行比较,待评价译文中单词出现在三个参考译文中的个数除以待评价译文中总单词个数,便得到原始的精确度(precision)计算结果。然而,由于一些特殊情况,研究者们对这个原始的精确度作了一些修正。来看一种特例情况:
例2:
待评价译文 : the the the the the the the
参考译文 1: The cat is on the mat.
参考译文2: There is a cat on the mat.
问题很明显,当某个参考译文中的某个单词匹配完以后,这个单词就不应该再继续计数匹配了。论文中对数值型指标精确度采取的这一修正方式称为“剪切”(clipping)。得到的精确度称为 “修正过的n单位片段精确度”(modified n-gram precision)。 在例2 中待评价译文得到的“修正过的1单位片段精确度值” =2/7. 在例1中, 待评价译文1 得到的“修正过的1单位片段精确度值” =17/18, 待评价译文2 得到的“修正过的1单位片段精确度值” =8/14。这种剪切方式同样适用于n=2,3,4 等任意数值的情况。如在例1中,待评价译文1的“修正过的2单位片段精确度值”(modified bigram precision)=10/17, 待评价译文2得到的“修正过的2单位片段精确度值”=1/13。这种“修正过的n单位片段精确度”(modified n-gram precision)强调了翻译的两个方面:充分性和流畅度。待评价译文同参考译文使用相同的n单位片段(n-gram)反映翻译的充分性,其中匹配片段的长度则反映了翻译的流畅度。
在机器翻译评价中通常使用的是整篇文章和大段文字,此BLEU方法也是如此,使用大文字量进行翻译评价。使用大文字量可以减少偶然性的影响,从而生成更高质量的评价。在BLEU方法中,首先逐个句子计算“n-单位片段”的匹配个数, 然后将经过剪切的“n-单位片段”匹配记数加起来求和,再除以待评价译文中“n-单位片段”个数,得到一个“经修正的n-单位片段精确度值”(modified n-gram precision score),记作。
为了证明指标能够将质量不同的翻译结果区分开来,作者选取了一段高质量的人工译文和一段标准的机器译文(代表比较差的翻译结果),分别包括127个句子,使用4个参考译文,来分别计算它们的值。当n-gram 的n取值1,2,3,4时,一共得到四个 值。结果显示随着n值增大,值的绝对值减小,而两个译文的差别增大;而且当n=1时, 值已经明显显示出两组的差别。
如原文图1.

研究者们进一步检测了在译文质量相差不是非常明显的情况下,如比较几个不同的机器翻译结果,或者是比较几个不同的人工翻译结果,这个指标能否对这些译文加以区分。为了考察这一点,研究者们使用了三个机器翻译系统给出的译文,和两个人工翻译给出的译文,在n-gram 取值不同的情况下,各自计算了值。结果发现,在n为某一固定值时,各个译文得到的值大小都有差别,而且在不同n取值情况下,五个译文得到的值大小排列顺序是完全一致的。
如原文图2.

2.3. BP值(Brevity Penalty) 和BLEU值的计算公式
值可以反映出译文的质量,那么不同n 取值的值是如何结合起来的呢?研究者们使用了值加权后的对数值之和的形式。最终BLEU值 是如何得到的呢?研究者们还考虑到一种情况,就是待测译文翻译不完全不完整的情况,这个问题在机器翻译中是不能忽略的,而简单的值不能反映这个问题。因此研究者们在最后的BLEU值中引入了BP(Brevity Penalty)这个指标。作者指定当待评价译文同任意一个参考译文长度相等或超过参考译文长度时,BP值为1,当待评价译文的长度较短时,则用一个算法得出BP值。 以c来表示待评价译文的长度,r来表示参考译文的文字长度, 则
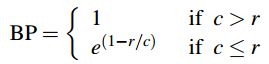
最后得到BLEU值计算公式

3、对BLEU值指标评价效果的验证
BLEU值的取值范围是从0到1的数值。只有译文同参考译文完全一致的时候才会有评分为1的情况。值得注意的一点是,使用越多的参考译文,BLEU评分值就越高。因此在参考译文数量不同的情况下,对不同BLEU值的译文结果要慎重判断。为了评价BLEU值指标的性能,作者使用了一份包含500个句子的文档进行翻译评价,选取了五种译文结果:三个为机器翻译系统给出的译文结果,用S1,S2,S3 表示, 两个为非专业人工翻译译文结果,用H1,H2 表示。评价中使用了两份参考译文。结果如表1 所示。
| 表 1. 500个句子大小文字得到的BLUE值 |
||||
| S1 |
S2 |
S3 |
S4 |
S5 |
| 0.0527 |
0.0829 |
0.0930 |
0.1934 |
0.2571 |
其中三个机器翻译译文S1, S2, S3的BLEU值非常接近。
作者还希望能回答以下三个问题:
1.各个译文结果的BLEU值差异是否可信?
2.BLEU值的方差是多少?
3.如果我们选用另外一个500句子的文档,能得到相同的结果吗?
为了回答这些问题,500个句子的文字被划分成20个部分,每个部分包含25个句子,然后分别使用这20个部分来计算译文的BLEU值。这样五组译文(三个机器翻译结果, 两个非专业人工翻译结果)各得到20个BLEU值。 然后对这五组BLEU值数据进行分析:计算均值,标准差,并对这五组数据每相邻两组(按照均值大小从左至右排列)进行比较,作配对T检验。结果发现每个BLEU值同其左侧BLEU值比较,差别均具有显著性。如表2所示。
|
表2. 配对t检验 (每组包括20个BLEU值) |
|
||||
|
|
S1 |
S2 |
S3 |
H1 |
H2 |
| 均值 |
0.051 |
0.0810 |
0.090 |
0.192 |
0.256 |
| 标准差 |
0.017 |
0.0250 |
0.020 |
0.030 |
0.039 |
| paired-t值 |
--- |
6 |
3.4 |
24 |
11 |
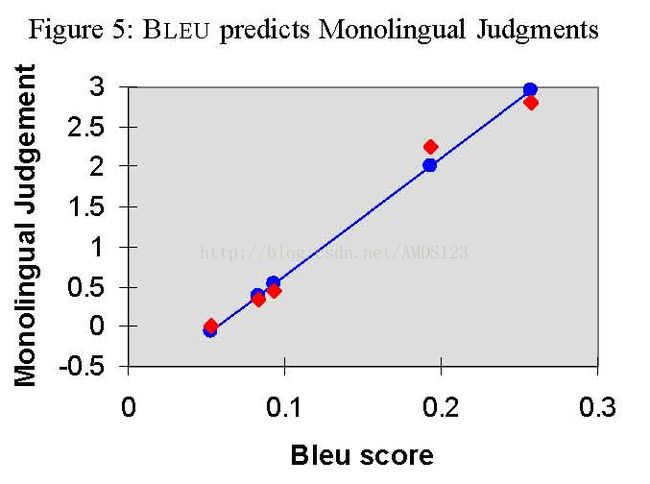
最后研究者们还进行了了将BLEU评分结果同人工评分结果进行比较的研究。同样是上面研究使用的机器译文,选取了两组人员进行人工评分,每组10人。 一组评分员只通晓英语一种语言( Monolingual),那么他们的评分侧重翻译的流畅度。一组评分员则通晓英语和汉语两种语言(Bilingual),他们的评分则反映了翻译的更多方面,除了流畅度外还考量到翻译的充分性和忠实度。研究者们对人工评分结果和BLEU值结果进行了相关性研究,发现通晓英语一种语言的评分组,其评分结果同BLEU值的相关系数为0.99;通晓汉英两种语言的组,其评分结果同BLEU值的相关系数为0.96 (见原文图5,图6)。

Reference:
(1)BLEU:a Method for Automatic Evaluation of Machine Translation. Kishore Papineni,Salim Roukos,Todd Ward, and Wei-Jing Zhu. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, July 2002, pp.311-318.