spark python 练习(一)
最近学习《Spark快速大数据分析》这本书,记录一下练习的例子,可以在忘记时查看。
如果在pycharm里写pyspark,配置可以参考文章:
http://blog.csdn.net/huobanjishijian/article/details/52287995。
spark版本2.02,python 版本2.7.5
spark官方文档地址:http://spark.apache.org/docs/latest/quick-start.html
python lambda,内联函数简介:
http://blog.csdn.net/Anne999/article/details/66972451
一、入门基础练习
1.行数统计
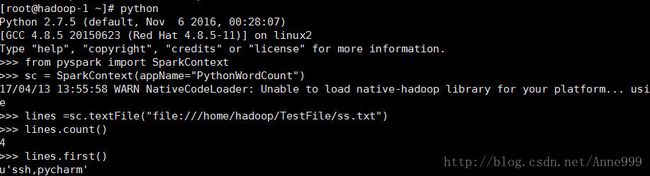
SparkContext对象创建与集群的连接。
2.筛选
pythonLines = lines.filter(lambda line: "Python" in line)另一种写法:
def hasPython(line):
return "Python" in line
pythonLines = lines.filter(hasPython)spark的fliter可以在集群上运行。
3.python初始化的写法
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)或者
sc = SparkContext(appName="PythonWordCount")第二种更加简洁些。传递的两个参数:
集群url:告诉spark如何连接到集群,local单机运行。
appName:应用名字。

图中的第一行url即为集群地址;
sc.stop()sys.exit()System.exit(0)这三个方法都可以退出应用。
二、RDD
1.创建RDD
#创建一个RDD
lines = sc.textFile("/usr/hdp/2.5.0.0-1245/spark2/README.md")2.RDD的两种操作:转化操作(transformation)和行动操作(action).转化操作会由 RDD 生成新的 RDD,例如筛选,map(),filter()。行动操作会 对RDD 计算出一个结果,并把结果返回驱动程序中,或把结果存储到外部存储系统(例如HDFS)中。first(),count().转化操作返回RDD,行动操作返回其他数据类型。
3. RDD.persist() 让Spark 把RDD缓存下来,用于多个操作重用一个RDD.

pythonLines.persist
>>> pythonLines.count()
2
>>> pythonLines.first()
u'## Interactive Python Shell'cache() 与使用缓存级别的 persist() 一样的。
4.创建RDD的两种方法
(1)程序中已有集合SparkContext的 parallelize()方法。除了开发和测试用的不多。
lines = sc.parallelize(["pandas", "i like pandas"])lines = sc.textFile("/path/to/README.md")5.转化操作
>>> imputRDD=sc.textFile("/var/log/yum.log")
>>> errorRDD=imputRDD.filter(lambda x:"python" in x)union(),操作两个RDD
errorsRDD = inputRDD.filter(lambda x: "error" in x)
warningsRDD = inputRDD.filter(lambda x: "warning" in x)
badLinesRDD = errorsRDD.union(warningsRDD)
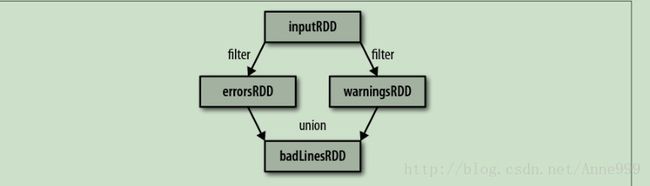
6.行动操作
print "Input had " + badLinesRDD.count() + " concerning lines"
print "Here are 10 examples:"
for line in badLinesRDD.take(10):
print linecollect()函数,获取整个RDD数据。
saveAsTextFile() 、 saveAsSequenceFile()保存RDD
7.惰性操作
sc.textFile() 时,数据没有有读进,而必要时会读。

8.python向Spark传递函数
传递比较短的时候,可以用lambda函数。
传递顶层函数
传递定义的局部函数
word = rdd.filter(lambda s: "error" in s)
def containsError(s):
return "error" in s
word = rdd.filter(containsError)安全的传递方式
class WordFunctions(object):
...
def getMatchesNoReference(self, rdd):
query = self.query
return rdd.filter(lambda x: query in x)9.常见的转化操作
(1)基本RDD
map():接收一个函数,把函数作用于每一个RDD元素的返回作为结果对元素的值。把字符串解析并返回double类型。
filter():满足函数的作为RDD返回。
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x).collect()
for num in squared:
print "%i " % (num)flatmap():把每个元素输出多个元素。
lines = sc.parallelize(["hello world", "hi"])
words = lines.flatMap(lambda line: line.split(" "))
words.first()
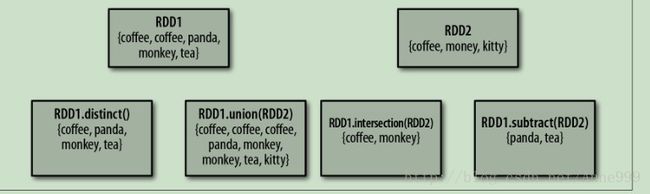
RDD.distinct()生成不含重复元素的RDD,开销很大
(2)伪集合操作
数据类型必须相同
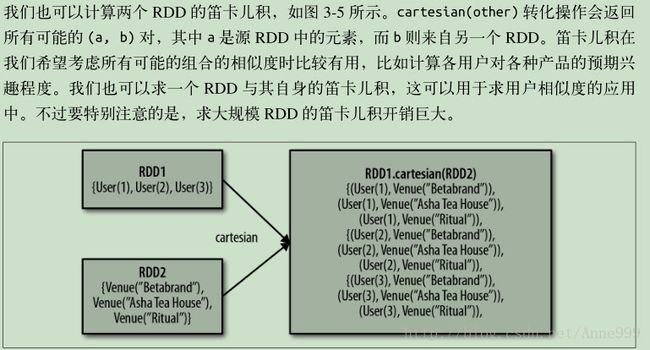
笛卡尔乘积
10.常见RDD操作总结


11.行动操作
reduce:
sum = rdd.reduce(lambda x, y: x + y)
aggregate() 函数:返回值类型可与前面不同。
sumCount = nums.aggregate((0, 0),
(lambda acc, value: (acc[0] + value, acc[1] + 1),
(lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1]))))
return sumCount[0] / float(sumCount[1])
x={1,2,3,3}

12.不同类型RDD之间的转换
mean(),variance()只能用于数值类型RDD
join()用于键值对型RDD
13.持久化(缓存)
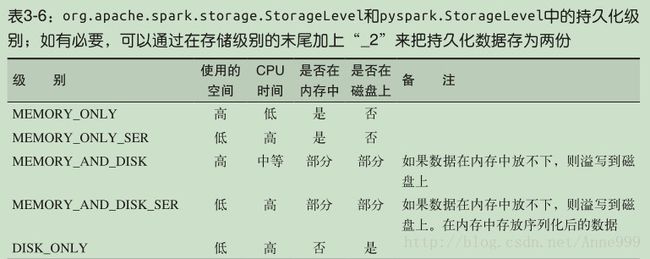
unpersist():把持久化的RDD从缓存中移除。
三、键值对操作
可以通过一些初始ETL(抽取,转换、装载)操作将数据转换键值对形式。键值对运算可以用来进行聚合运算。
1.pair RDD:Spark为键值对提供的特有操作。
reduceByKey():分别规约每个键对对应的数据。
join():建相同的元素组合在一起,合并为一个RDD.
2.创建pair RDD